Generative Adversarial Networks (GANs)#
GANs (Generative Adversarial Networks) are a family of generative models. As their name suggests, these models are unsupervised, meaning they do not require labels during training. GANs use a trick to transform this unsupervised problem into a supervised one.
Basic Principle of GANs#
Two Competing Models#
The basic principle of GANs relies on the use of two neural networks that train concurrently.
The Generator: Its role is to create examples similar to those in the training data. It takes a random vector (from a Gaussian distribution) as input and generates an example from this input.
The Discriminator: Its role is to classify an example as real (from the training data) or fake (generated by the generator). It is a simple classifier, like those seen previously.
A Zero-Sum Game#
These models train concurrently in what is called a zero-sum game. The goal is for the discriminator to be unable to determine whether an example is real or generated (it returns a probability of \(\frac{1}{2}\) for each element). This means the generator is capable of creating plausible examples. In this case, the generator has learned the probability distribution of the training data.
During training, the generator creates a batch of examples that are mixed with real examples (from the training data). These examples are then given to the discriminator for classification. The discriminator is updated by gradient descent based on its performance. The generator is updated based on its ability to fool the discriminator.
The generator can be compared to a counterfeiter and the discriminator to the police. The counterfeiter tries to fool the police by creating perfect fake bills, while the police develop new techniques to detect the fake bills. Thus, both progress together. Personally, I find that the idea behind GANs can be applied to many real-life situations. We often give our best in adversity.
Note: Generally, during the training of a GAN, we are primarily interested in the generator. The discriminator is only used for training. However, since there are far more unlabeled images (almost all images available on the internet) than labeled ones, it may be interesting to train a GAN on a large number of images and use the discriminator and generator as pre-trained models for other tasks.
GAN Architecture#
Most GANs are convolutional neural networks, and for several reasons. On the one hand, it is easy for a human to evaluate the quality of a generated image, which allows for direct and intuitive assessment of the model’s performance. On the other hand, GANs have shown impressive performance for image generation, but less so for other tasks like text generation.
The architecture of most GANs is based on the paper DCGAN.
Note: GANs were invented before transformer architectures. Recently, GAN-type architectures have been proposed with a transformer instead of a CNN.
Note 2: There is an important theoretical aspect behind GANs, but we will not go into the details in this course. To learn more, you can refer to Stanford’s CS236 course and in particular this link.
Conditional GANs#
The architecture we have seen allows generating a realistic image from a random vector from a Gaussian distribution. However, we have no control over the generated image. If we train the model on images of people, it generates a person with random attributes (gender, eyes, hair, skin, etc.). This is not very practical, as in many cases, we want to generate a specific image and not just a random realistic one.
To solve this problem, we can use a conditional GAN (conditional GAN), which takes the classic GAN architecture but adds information about the data as input to the generator and discriminator.
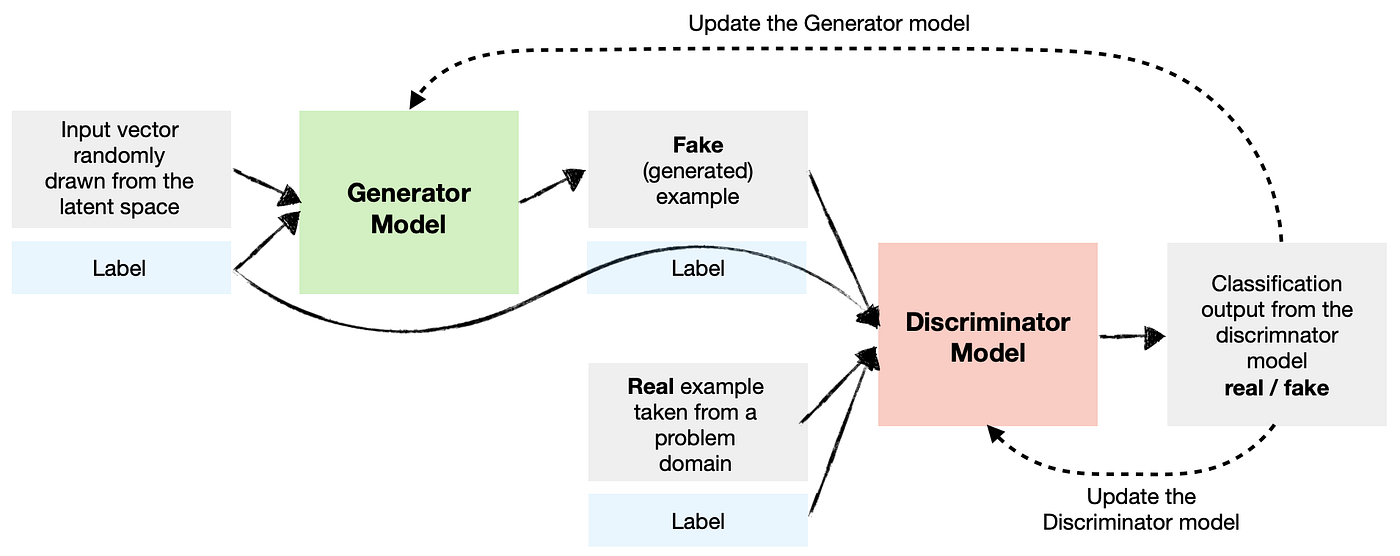
Figure taken from the blogpost
Thus, we can direct the generation using a label, which allows generating images containing specific attributes.
Problems with GANs#
The architecture of GANs is an excellent idea and works very well in practice when the model is well trained. In previous courses, we emphasized the difficulty of training a deep learning model and presented many techniques to facilitate training. Here, we have two models to train at the same time and in an antagonistic manner. This is the main problem with GANs: in practice, they are very complicated to train.
Mode Collapse#
The main problem that makes GAN users shudder is mode collapse. This occurs when the generator learns to produce a limited variety of often very similar results. In this case, the generator has not succeeded in capturing the diversity of the training data, but still manages to systematically fool the discriminator. One can imagine that the generator has learned to generate a perfect image, but can only generate that image.
This problem stems directly from the GAN training objective and is very difficult to manage.
Balance Between Generator and Discriminator#
During training, we want the generator and discriminator to progress together. However, it may happen that one of the two models progresses faster than the other, which can cause chaotic behavior during training.
There are also other problems to mention:
Convergence problem: The model may have difficulty converging to a stable solution, even after long training.
Choice of network architecture: A consistent architecture must be chosen for the generator and discriminator.
Some strategies can be used to limit these problems, but it’s not magic. To stabilize training, one can use a Wasserstein GAN and/or more progressive training.
Examples of GAN Usage#
GAN for Super Resolution#
It is possible to use GANs for super-resolution, i.e., to increase the resolution of an image. The paper Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network proposes a GAN architecture for this purpose.

GAN for Data Augmentation#
Data augmentation involves artificially increasing the training data through various techniques. If you haven’t already, you can follow the bonus course on data augmentation.
Thinking about it, basic data augmentation (cropping, rotation, etc.) can be seen as a form of generative modeling where we generate training images close to the distribution of normal images.
Starting from this consideration, it is quite obvious to see how a GAN can help with data augmentation. If we want to classify cats, our GAN can generate cat images in quantity.
Image-to-Image Translation#
Another common use of GANs is image-to-image translation, introduced in the paper Image-to-Image Translation with Conditional Adversarial Networks. This allows converting an image from a source domain to a target domain while preserving structural and contextual correspondences (according to training).
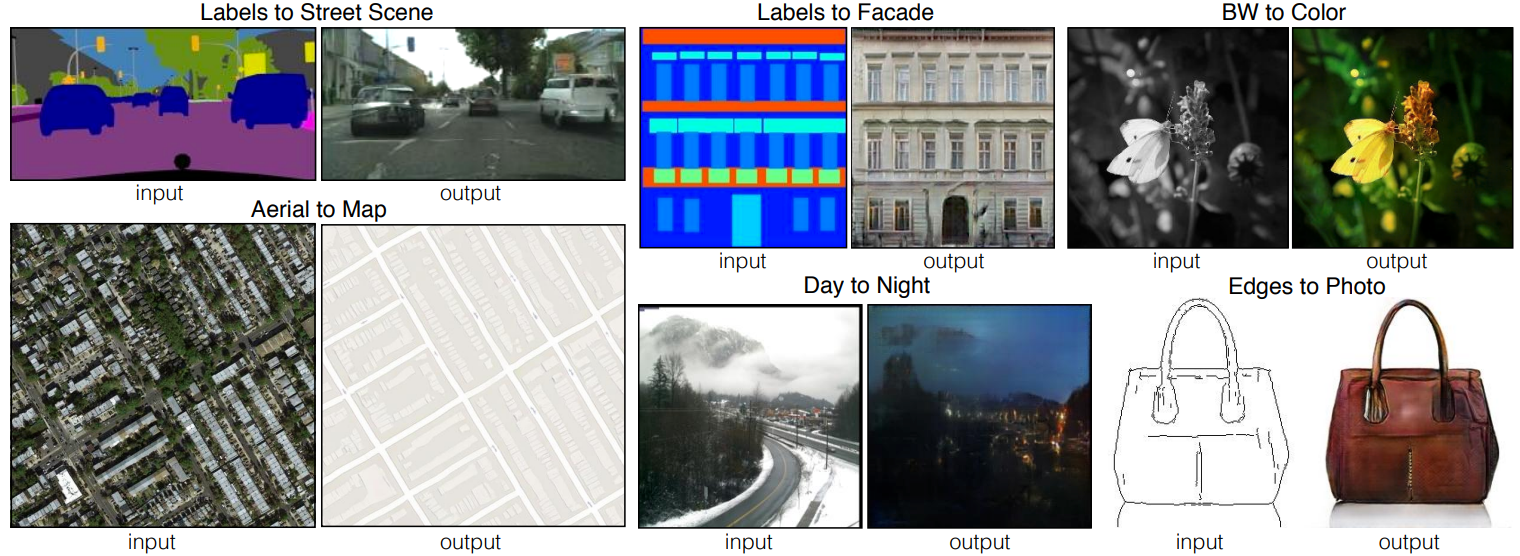
Note: Image-to-image translation can also be used for data augmentation. Suppose we generate fake data using a video game software like Unity and want to make these images realistic. It is then sufficient to train a style transfer GAN to go from one image to another.