Unsupervised Contrastive Learning#
Today, a large portion of deep learning research focuses on unsupervised learning. As we saw in the course 4 on autoencoders, unsupervised learning involves training a model without labeled data. The main advantage of this approach is that it significantly reduces the costs and efforts required for data preparation. This type of learning has brought NLP to the forefront and enables impressive image generation with DALL-E or video generation with SORA.
In course 5 on NLP, we saw how to perform unsupervised learning on text (you just need to retrieve any text and train the model to predict the next character). For image processing, we haven’t really addressed this question, except for a brief mention of CLIP in course 7 on transformers.
How to Adapt Contrastive Learning to Unsupervised Learning?#
CLIP Model#
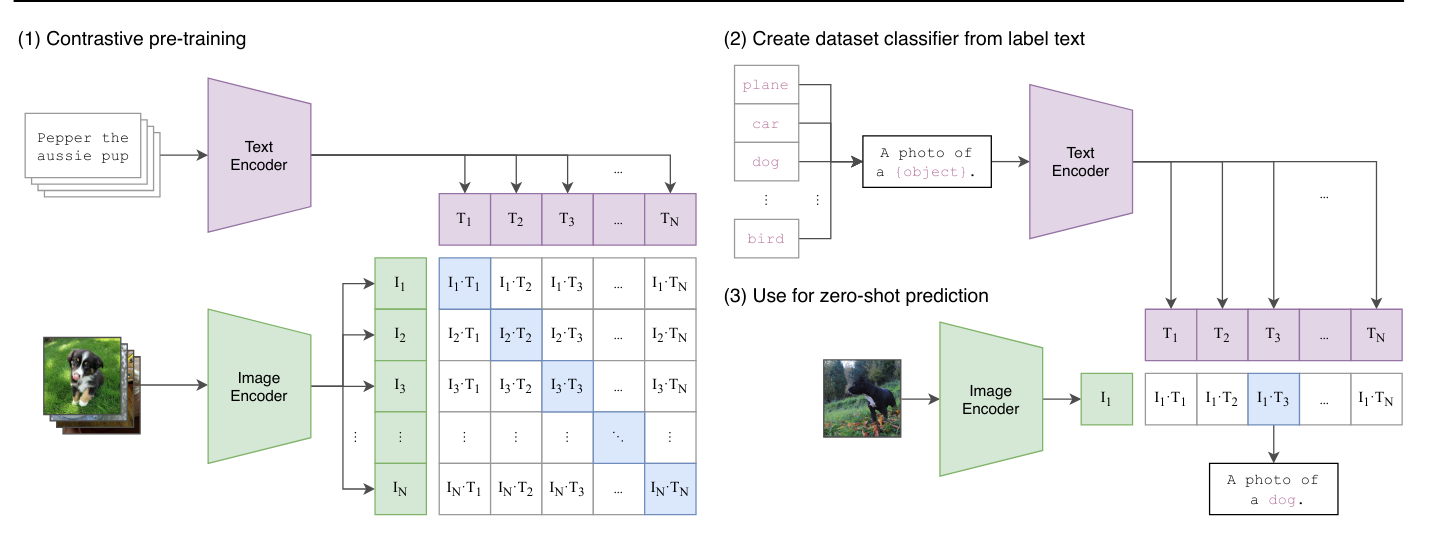
We have already seen the CLIP model in course 7, which is trained contrastively within the batch. This approach differs from what we have seen before: a vision transformer takes the images of the batch as input, while a text transformer takes the descriptions of each image as input. The model is then trained to correctly associate images and descriptions in a contrastive manner, minimizing the distance between the embeddings of the same pair and maximizing that of different pairs.
CLIP is a model using a contrastive loss function, but it is not truly unsupervised. It relies on pairs of images/texts that serve as labels for training.
Unsupervised Learning for Images#
In unsupervised learning, we aim to avoid labeled data. The method SimCLR proposes a technique for using contrastive learning in this context. The idea is to process a batch of data where each element is a pair of images. The particularity of this pair is that it is the same image to which a transformation has been applied (see bonus course on data augmentation). Each image is then passed through an identical network (siamese), and the model is trained to minimize the distance between the representations of images from the same pair and to maximize that of images from different pairs.
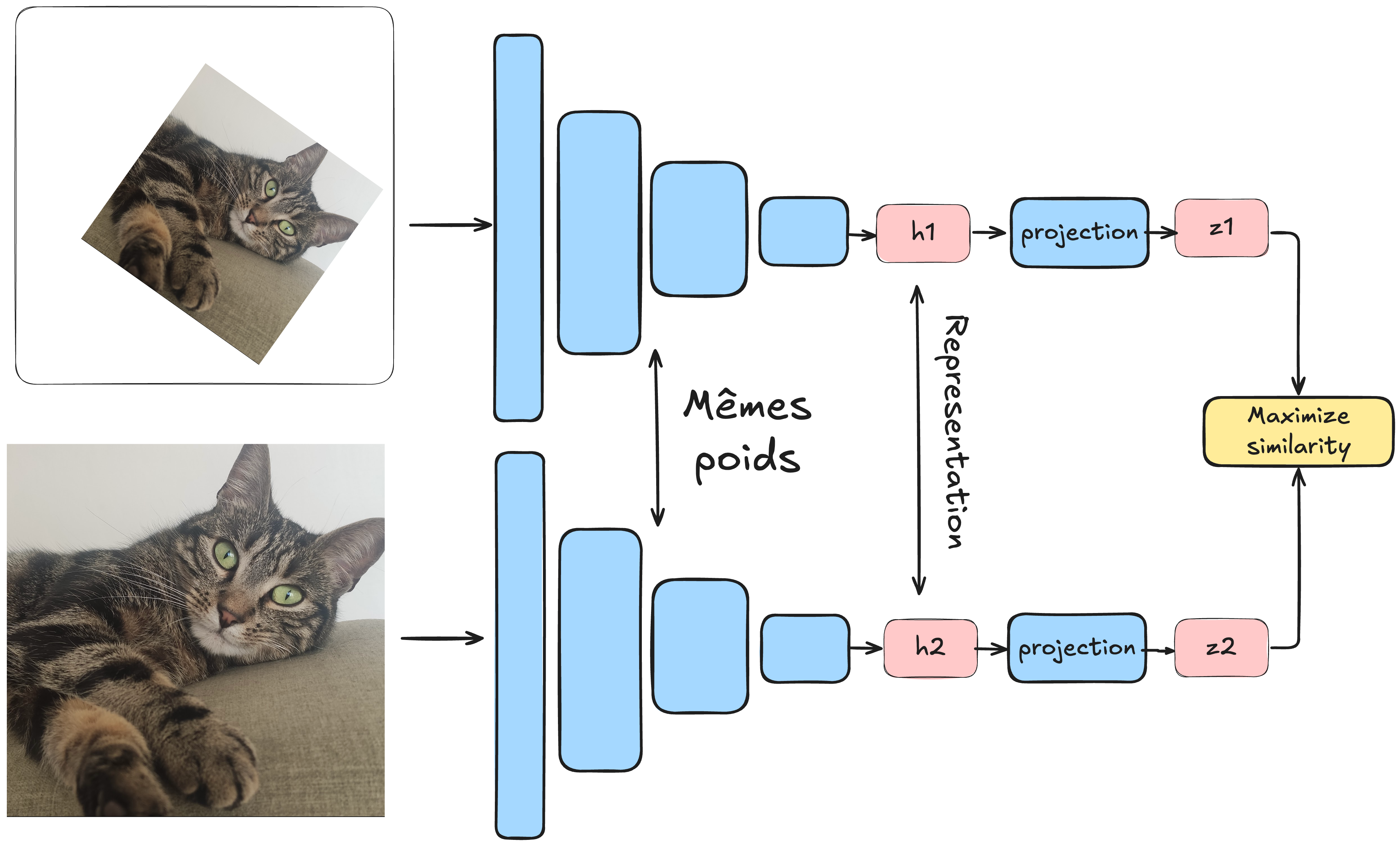

In this method, data augmentation is crucial, and it is important not to neglect the various possible transformations. To make the analogy with positive and negative pairs:
Positive pairs: The two transformed images \(x_i\) and \(x_j\) coming from the same image \(x\).
Negative pairs: Two transformed images \(x_i\) and \(x'_j\) coming from different images \(x\) and \(x'\). Thanks to this method, the model can learn relevant representations of images without needing labels. It can thus distinguish images representing different objects, without necessarily knowing what these objects represent.
Advantages of This Approach#
One might wonder the interest in training such a model. What can it be used for once trained? To answer this question, we can draw an analogy with language models. These models are first pre-trained on a large portion of the Internet, then fine-tuned on a specific task (like a chatbot for ChatGPT, for example). For images, it’s roughly the same: models trained contrastively on billions of images can serve as generic models that can then be fine-tuned on more specific tasks, such as classification. Note: Fine-tuning and transfer learning are covered in detail in the next course. In short, these are techniques for reusing a model already trained on different tasks.
Alternatives to Contrastive Learning for Unsupervised Learning#
It is important to note that contrastive learning is not the only method for performing unsupervised learning on images.
Autoencoders#
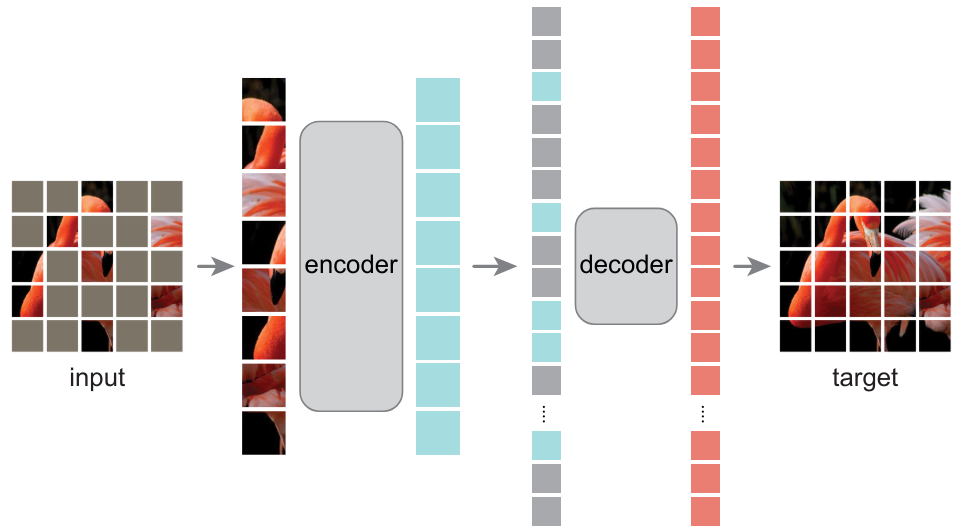
We have already introduced autoencoders in course 4, which allow learning relevant image representations. The paper Masked Autoencoders Are Scalable Vision Learners demonstrates that masked autoencoders can be used to learn very useful image representations.
Generative Adversarial Networks (GANs)#
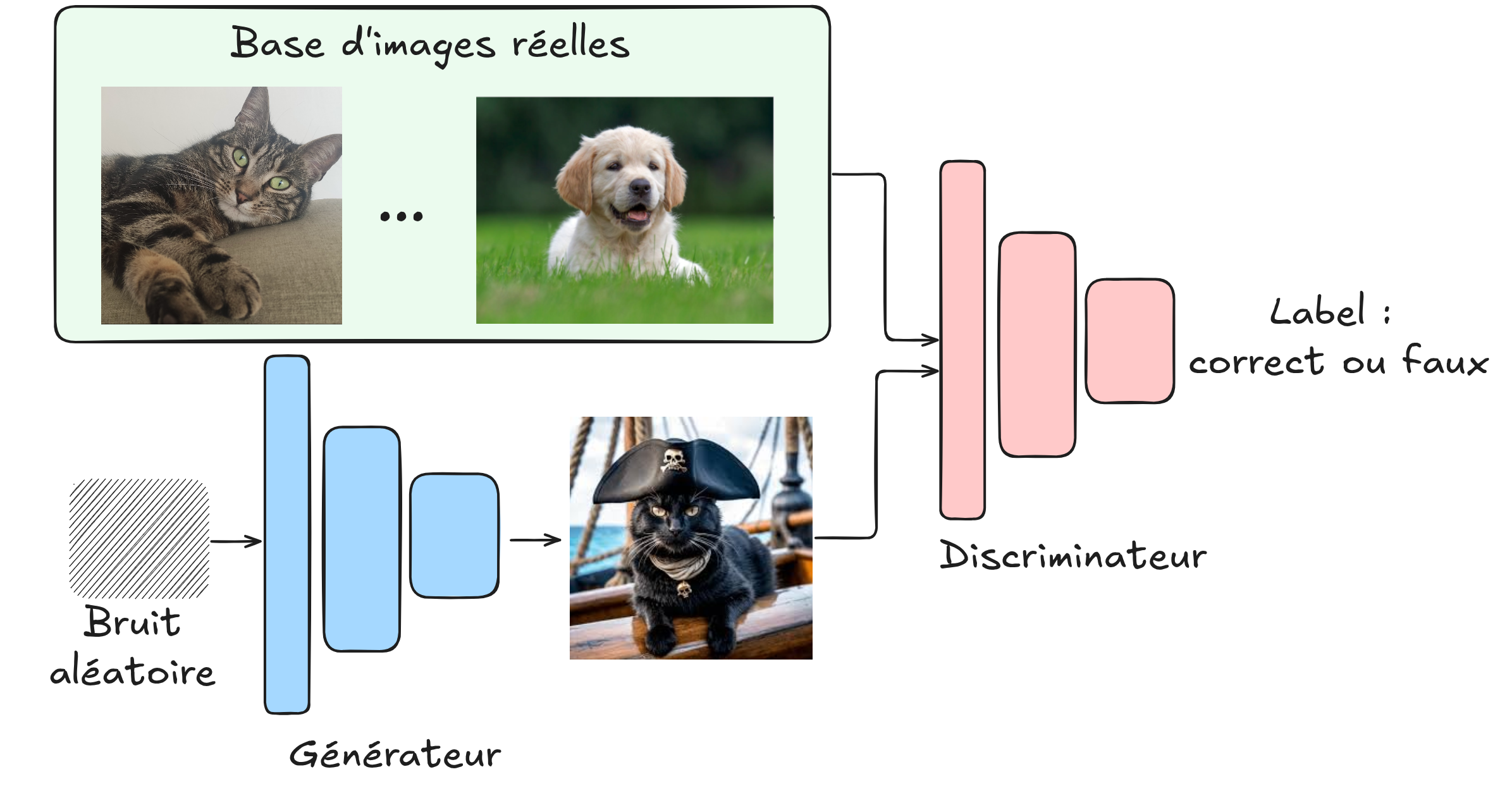
In this course, we have not yet discussed GANs. Briefly, these are networks that train in an adversarial manner: a generator creates fake images, while a discriminator must distinguish between a real image and a generated image. By training together, we can obtain a generator capable of producing very realistic images without needing a labeled dataset. A few years ago, this was the most used method for image generation (since then, diffusion models are preferred, which are also unsupervised).
Transformation Prediction#
Another approach involves predicting a transformation applied to the image. For example, you can rotate the image (RotNet) and train the model to predict this rotation, or mix the image like a puzzle and train the model to reconstruct it (JigSaw).

Self-Supervised Distillation#
More recently, methods based on knowledge distillation again use image transformations, like in contrastive learning, but without using negative pairs. To prevent the model from collapsing, various techniques are used. For more information, you can read the paper DINO. Note: The concept of knowledge distillation will be covered in the next course.

Note: The list of unsupervised methods is not exhaustive, but you now have a good idea of the existing methods. Furthermore, GANs and diffusion models are unsupervised, but they are not used to create base models that can be fine-tuned on more specific tasks.