Introduction to Transformers#
In the previous chapter, we explored many applications of the Hugging Face Transformers library. As its name suggests, this library manages transformer models. But what exactly is a transformer model?
Origins of the Transformer#
Until 2017, most neural networks for NLP used RNNs. In 2017, Google researchers published a paper that revolutionized the field of NLP, and later other areas of deep learning (vision, audio, etc.). They introduced the transformer architecture in their paper “Attention Is All You Need”.
Here is what the transformer architecture looks like:
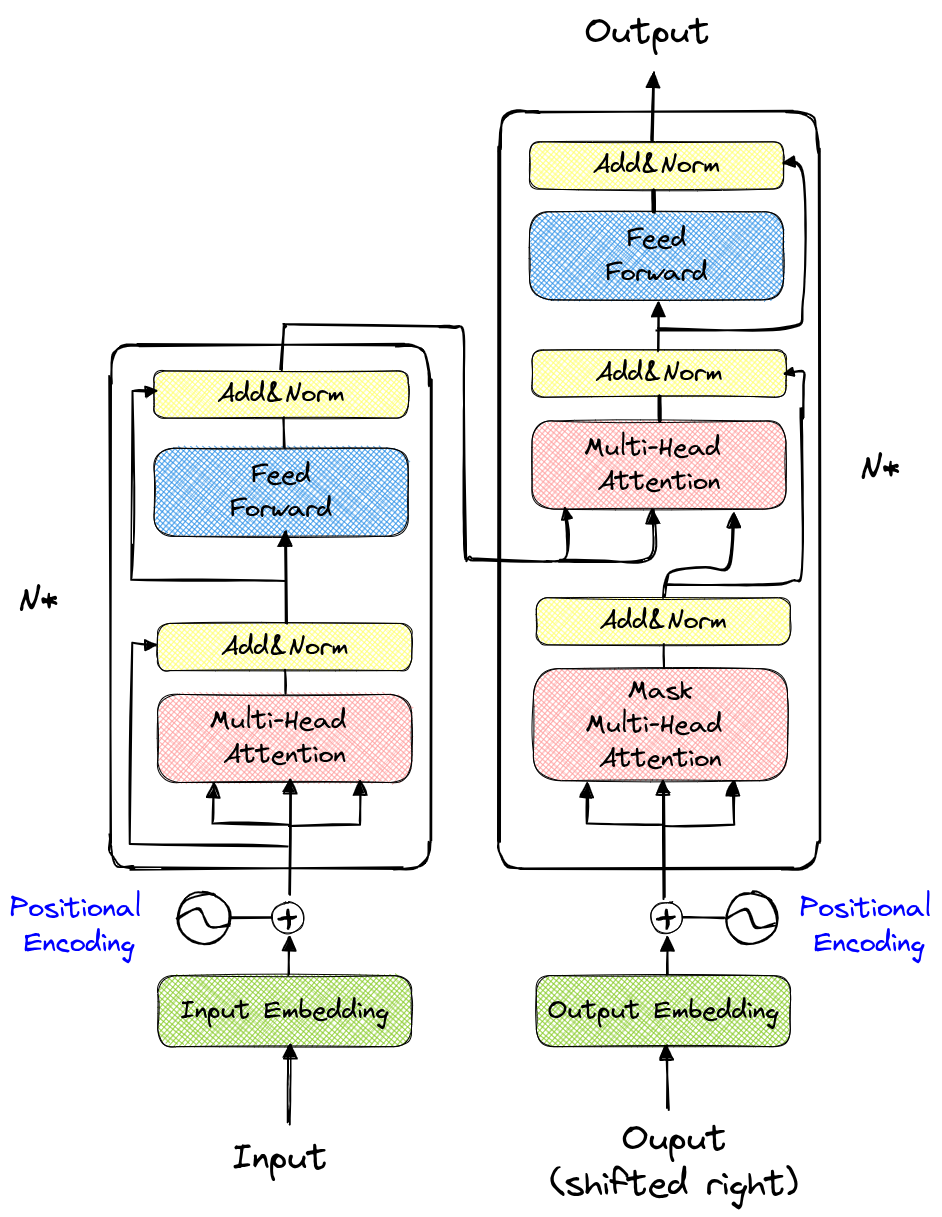
At first glance, this seems quite complex. The left part is called the encoder, and the right part is the decoder.
Course Content#
Part 1: Building GPT from Scratch#
The first part of this course is heavily inspired by Andrej Karpathy’s video “Let’s build GPT: from scratch, in code, spelled out.”. In this part, we implement a model that predicts the next character based on previous characters (similar to Course 5 on NLP). This will help us understand the benefits of the transformer architecture, especially on the decoder side. In this part, we will train a model to automatically write “Molière.”
Part 2: Theory and Encoder#
The second part covers more mathematical concepts and also introduces the decoder of the transformer architecture.
Part 3: ViT, BERT, and Other Notable Architectures#
This third part quickly introduces adaptations of the transformer architecture for tasks other than GPT.
Part 4: Implementing the Vision Transformer#
In the fourth part, we implement the vision transformer based on the paper An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale and train it on the CIFAR-10 dataset.
Part 5: Implementing the Swin Transformer#
This fifth and final part provides an explanation of the paper Swin Transformer: Hierarchical Vision Transformer using Shifted Windows along with a simplified implementation.