YOLO in Detail#
In this notebook, we will explore the workings of the YOLO model in detail.
Object Detection#
History of Object Detection#
Shortly after the publication of the famous paper that popularized deep learning, image processing researchers began developing deep learning models.
As explained in the previous notebook, there are three main categories of image processing algorithms: classification, detection, and segmentation.
Classification is relatively simple to implement with a deep learning model, provided you have the necessary resources. On the other hand, detection requires more ingenuity.
In 2014, a group of researchers proposed the paper Rich feature hierarchies for accurate object detection and semantic segmentation, better known as R-CNN. This highly influential paper introduces a two-step architecture for object detection and offers remarkable performance. The main drawback of this approach is its slow processing time, which does not allow for real-time detection. Many methods have attempted to solve this problem by proposing different architectures, such as fast R-CNN, faster R-CNN, and mask R-CNN. These methods significantly improve the basic R-CNN, but they are not sufficient for real-time detection in most cases.
In 2015, a paper caused a major upheaval in the field of object detection. This paper is You Only Look Once: Unified, Real-Time Object Detection.
You Only Look Once#
Previous approaches used region proposals followed by classification. In other words, they relied on powerful classifiers for object detection.
The You Only Look Once (YOLO) paper proposes to predict bounding boxes and class membership probabilities directly using a single neural network. This architecture is much faster and can achieve processing speeds of up to 45 frames per second.
It’s a revolution in the field of object detection!
But how does it work?
YOLO: How Does It Work?#
This section describes the architecture of YOLO, inspired by the blog post. I invite you to check it out. The images used are taken from the blog post or the original paper.
Grid Separation#
The basic principle of YOLO is to divide the image into smaller parts using a grid of size \(S \times S\) like this:
The cell containing the center of an object (e.g., a dog or a bicycle) is responsible for its detection (for calculating the loss). Each grid cell predicts \(B\) bounding boxes (configurable, 2 in the original paper) and a confidence score for each. The predicted bounding box contains the values \(x,y,w,h,c\), where \((x,y)\) is the center position in the grid, \((w,h)\) are the dimensions of the box as a percentage of the entire image, and \(c\) is the model’s confidence (probability).
To calculate the accuracy of our bounding box during training (component of the loss), we use the intersection over union, defined as:
\(\frac{pred_{box}\cap label_{box}}{pred_{box} \cup label_{box}}\)
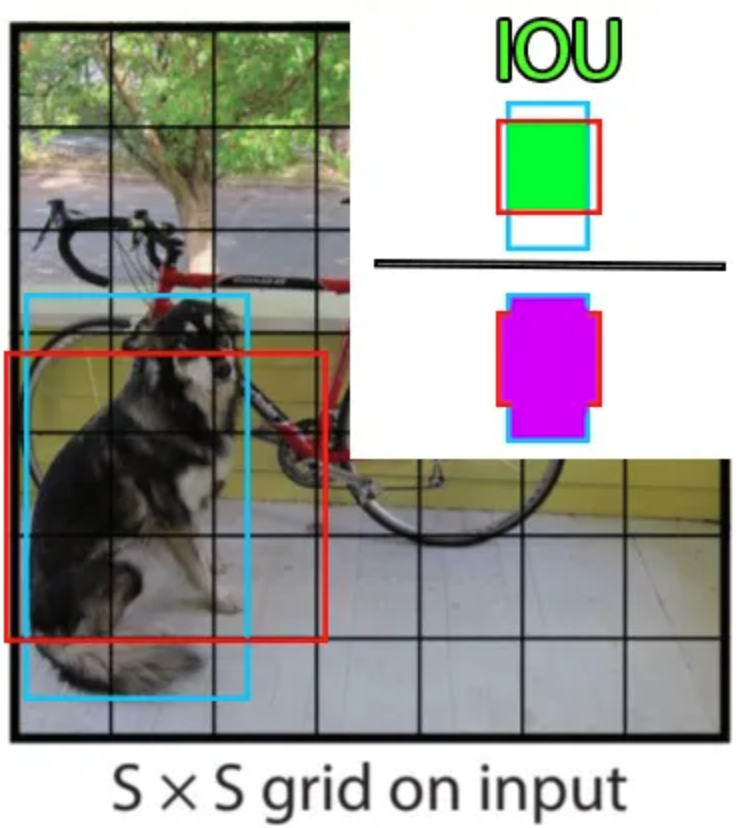
In addition to predicting the bounding box and confidence, each cell also predicts the class of the object. This class is represented by a one_hot vector (which contains only 0s except for a 1 in the correct class) in the annotations. It is important to note that each cell can predict multiple bounding boxes but only one class. This is one of the limitations of the algorithm: if multiple objects are in the same cell, the model will not be able to predict them correctly.
Now that we have all the information, we can calculate the output dimension of the network. We have \(S \times S\) cells, each cell predicts \(B\) bounding boxes and \(C\) probabilities (with \(C\) the number of classes).
The model’s prediction is therefore of size: \(S \times S \times (C + B \times 5)\).
This leads us to the following figure:
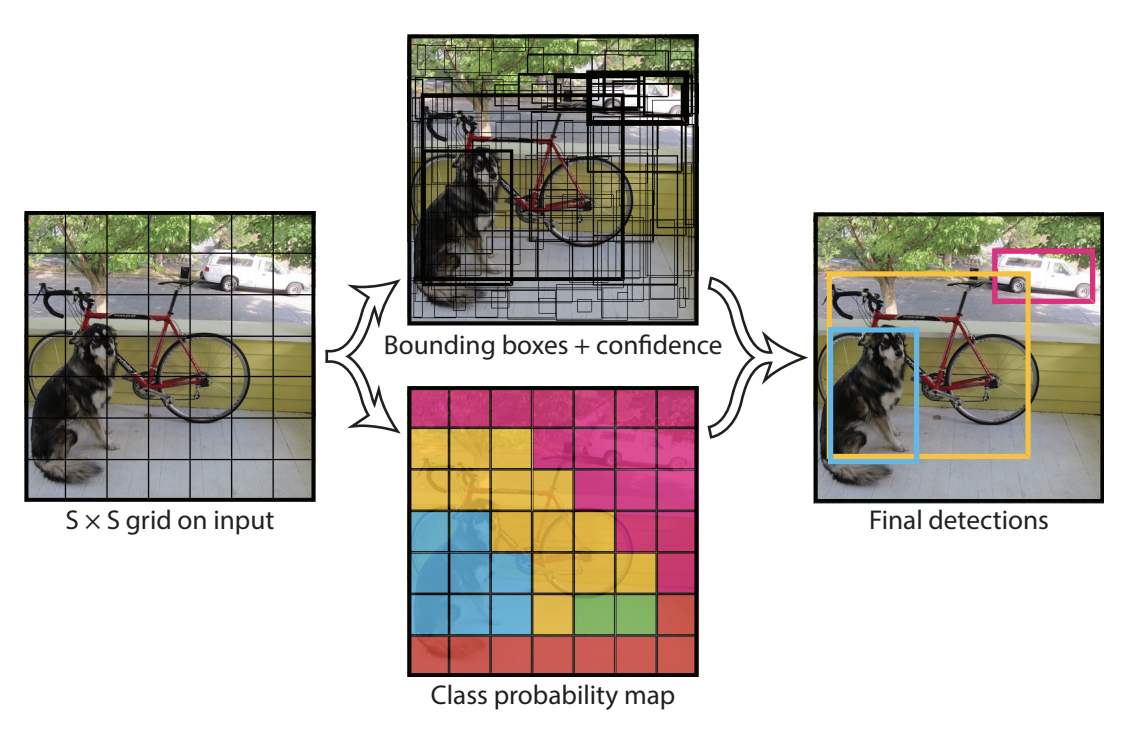
The top center figure shows the bounding boxes predicted by the model (those with a thicker line have high confidence scores). The bottom center figure shows the predicted class in each cell (blue for the dog class, yellow for the bicycle class, and pink for the car class).
Model Architecture#
The architecture of the YOLO model, in terms of layer arrangement, is also unique. It consists of three main components: head, neck, and backbone.
Backbone: This is the most important part of the network, consisting of a series of convolutions to detect the most important features. This part is often pre-trained on a classification dataset.
Neck and Head: These layers process the output of the convolutional layers to produce a prediction of size \(S \times S \times (C + B \times 5)\).
In the original YOLO paper, the grid is 7x7, there are 20 classes (Pascal VOC), and two bounding boxes are predicted per cell. This results in a prediction of size:
\(7 \times 7 \times (20 + 2 \times 5) = 1470\)
Model Training#
The model’s training values (image size, epochs, number of layers, batch_size, etc.) are detailed in the original paper, and we will not go into detail here.
However, it is interesting to delve a bit into the loss function. The basic logical idea would be to simply use the MSE loss between our predictions and the labels. However, this does not work as is because the model would give similar importance to the quality of localization and the accuracy of the prediction. In practice, we use a weighting on the losses \(\lambda_{coord}\) and \(\lambda_{noobj}\). The values in the original paper are set to 5 for \(\lambda_{coord}\) and 0.5 for \(\lambda_{noobj}\). Note that \(\lambda_{noobj}\) is used only on cells where there are no objects to prevent its confidence score, close to 0, from overly impacting cells containing objects.
Limitations of YOLO#
We have already mentioned its main limitation: predicting only a limited number of bounding boxes per cell and not allowing the detection of objects of different categories in the same cell. This poses a problem when you want to detect people in a crowd, for example.
Improving YOLO#
We have seen that YOLO is a very powerful and fast model for object detection in images. That’s why many researchers have sought to improve it by proposing various optimizations. Even today, new versions of YOLO are released regularly.
This section chronologically presents the different versions of YOLO.
YOLOv2 (2017) - Also Known as YOLO9000#
Paper: YOLO9000: Better, Faster, Stronger
Innovations:
Introduction of the idea of anchors (anchors) to improve the accuracy of box predictions.
Changing the input resolution from 224x224 to 416x416 to improve the detection of small objects.
YOLOv3 (2018)#
Paper: YOLOv3: An Incremental Improvement
Innovations:
Use of a deeper model with a Darknet-53 architecture, a residual convolutional neural network.
Multi-scale detection, with predictions made at three different levels of granularity (feature maps of different sizes).
YOLOv4 (2020)#
Paper: YOLOv4: Optimal Speed and Accuracy of Object Detection
Innovations:
Use of the CSPDarknet53 backbone for better performance.
Improvements in detection heads with PANet (Path Aggregation Network) to improve information flow.
Introduction of the Mosaic Data Augmentation concept to enrich the diversity of training data.
Addition of various modern techniques such as DropBlock, Mish activation, and SPP (Spatial Pyramid Pooling).
YOLOv5 (2020)#
Developed by Ultralytics
Innovations:
No official paper, but practical improvements in implementation and performance.
Lighter model and easier to train with better dependency management.
YOLOv6 (2022)#
Innovations:
New YOLOv6S backbone, optimized for real-time performance.
Advanced techniques for reducing latency.
Improvements in data augmentation methods and hyperparameter optimization.
YOLOv7 (2022)#
Paper: YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
Innovations:
Integration of bag of freebies to improve accuracy without increasing inference time.
Optimized architecture for an optimal trade-off between speed and accuracy.
Addition of various regularization techniques to improve overall performance.
YOLOv8 (2023)#
Developed by Ultralytics
Innovations:
Even more optimized for real-time performance and mobile integration.
Flexible architecture allowing adjustments for various use cases, including detection, segmentation, and classification.
YOLO-World (2024)#
Paper: YOLO-World: Real-Time Open-Vocabulary Object Detection
Innovations:
Use of a transformer encoder for text enabling open-vocabulary detection.