Introduction to Object Detection in Images#
Image processing is divided into three main categories:
Classification: Determines if an object is present in the image (example: is this a picture of a dog?).
Detection: Locates the position of an object in the image (example: where is the dog?).
Segmentation: Identifies the pixels belonging to an object (example: which pixels belong to the dog?).

Image extracted from this site.
In the course on CNNs, we covered classification problems with a classic CNN architecture ending with a Fully Connected layer, as well as segmentation problems with the U-Net model.
Object detection is more complex to explain, so this course focuses on existing methods and a detailed description of the YOLO model.
We will first explain the differences between the two main categories of detectors:
Two-Stage Detectors: These include the family of RCNN (Region-based Convolutional Neural Networks).
Single-Stage Detectors: These include the family of YOLO (You Only Look Once).
Two-Stage Detectors#
As its name suggests, a two-stage detector follows two steps to detect objects:
First step: Proposing regions (region proposal) where objects of interest might be located.
Second step: Refining the detection, i.e., associating the object class and the precision of the bounding box (if an object is present).
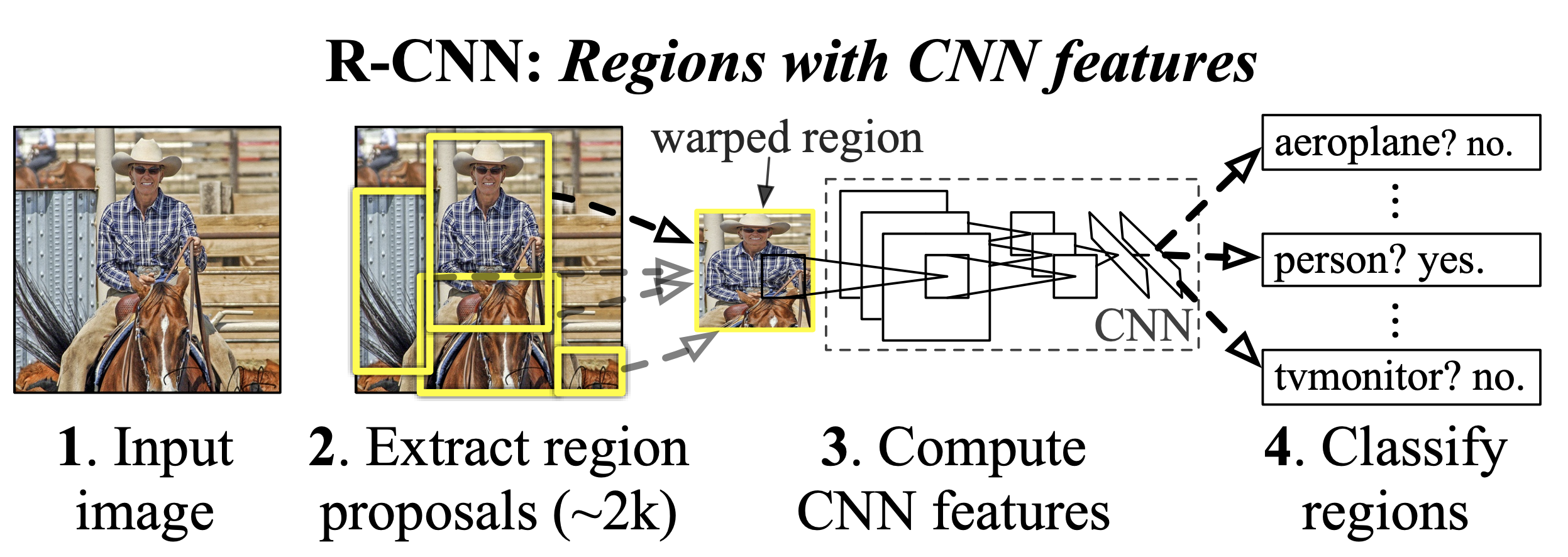
Image extracted from the article.
Generally, two-stage detectors are very accurate and allow for complex detections, but they are quite slow and do not support real-time processing.
The most well-known two-stage networks are the family of RCNNs. For more information, check out this blogpost.
One-Stage Detectors#
The one-stage detector only requires a single step to generate the bounding boxes with the corresponding labels. The network divides the image into a grid and predicts several bounding boxes and their probabilities for each cell of the grid.
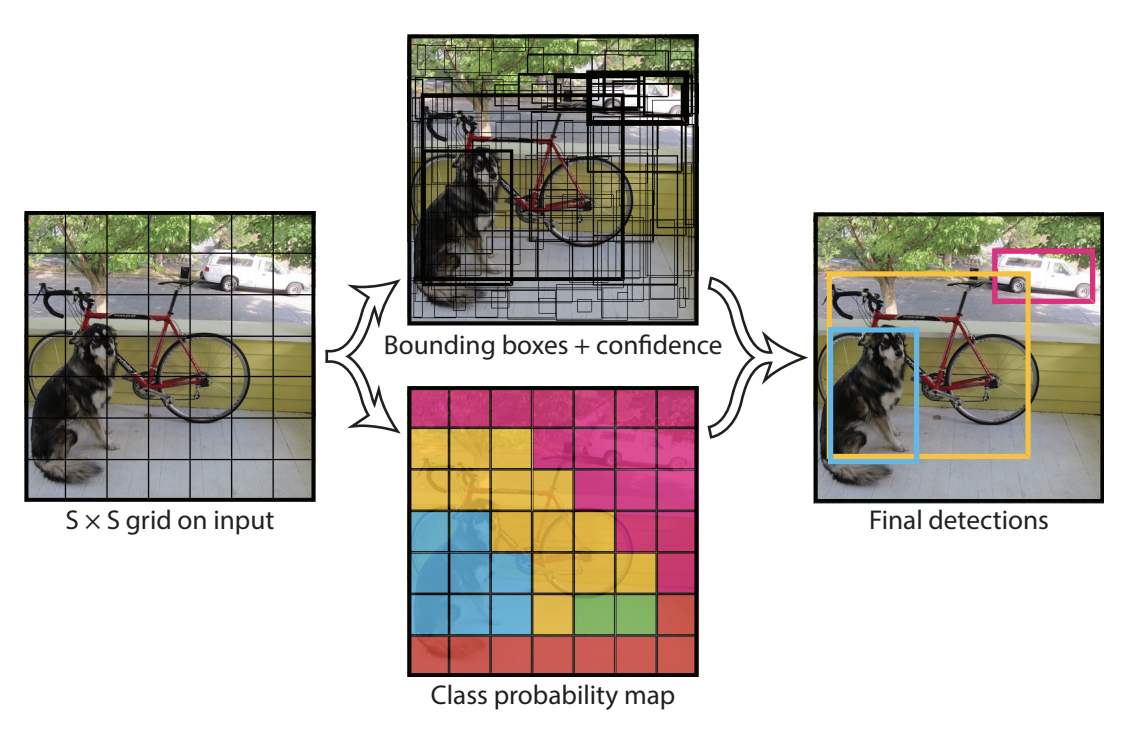
Figure extracted from the article.
One-stage detectors are generally less accurate than two-stage detectors, but they are much faster and allow for real-time processing. This is the most widely used family of detectors today.
Non-Maximum Suppression and Anchors#
NMS (Non-Maximum Suppression)#
When detecting objects with our model, the architecture does not prevent multiple bounding boxes from overlapping on the same object. Before transmitting the detections to the user, we want to have one detection per object, the most relevant possible.
This is where non-maximum suppression comes into play. The algorithm will not be detailed in this course, but you can consult the following resources for more details: blogpost and site.

Anchors (Anchor boxes)#
Anchors are predefined bounding boxes placed on a regular grid covering the image. They can have different aspect ratios (length/height) and variable sizes to cover as many possible object sizes as possible. Anchors reduce the number of positions to study for the model. With anchors, the model predicts the offset from the pre-generated anchor and the probability of belonging to an object.
This method improves the quality of detections. For more information, check out the blogpost.
In practice, there are often many anchors. The following figure shows 1% of the anchors from the retinaNet model:

Bonus: Object Detection with the Transformer Architecture#
Recently, the transformer architecture has been adapted for object detection. The DETR model uses a CNN model to extract visual features. These features are then passed through a transformer encoder (with a positional embedding) to determine spatial relationships between features using the attention mechanism. A transformer decoder (different from the one used in NLP) takes as input the output of the encoder (keys and values) and embeddings of object labels (queries), converting these embeddings into predictions. Finally, a final linear layer processes the decoder output to predict the labels and bounding boxes.
For more information, check out the article or this blogpost.
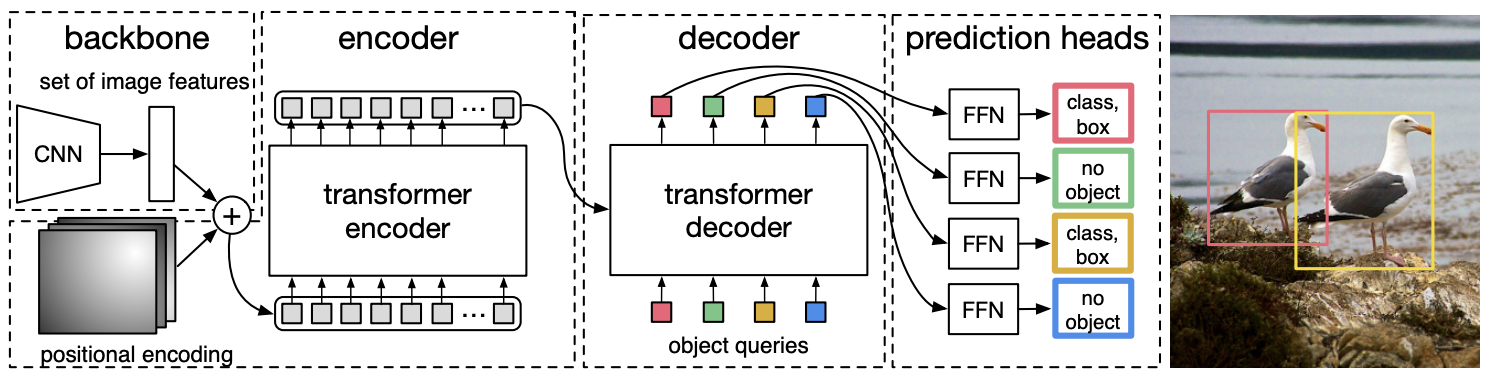
This method offers several advantages:
No need for NMS, anchors, or region proposal, which simplifies the architecture and training pipeline.
The model has a better overall understanding of the scene thanks to the attention mechanism.
However, it also has some drawbacks:
Transformers are computationally intensive, so this model is slower than a one-stage detector like YOLO.
Learning is often longer than for a detector based solely on a CNN.
Note: Transformers used in vision often have longer training times than CNNs. A possible explanation is that CNNs have a bias that makes them particularly suitable for images, requiring shorter training times. Transformers, being general-purpose models without bias, have to learn from scratch.