Transformer architecture and features#
So far, we have studied the decoder architecture of the transformer, focusing solely on the masked multi-head self-attention. In this section, we will explore the intuition behind the encoder block and the multi-head cross-attention.
Text-specific features#
Before diving into the encoder block, it’s important to understand why we only needed the decoder block in the previous notebooks. In the following figure, the red box shows the part of the model we used (without the second multi-head attention).
Text is read from left to right, which is why a text generation model uses the same direction to process information. This is called an autoregressive model. The model predicts the next token based on the previous tokens (included in the context).
During training, a mask is used to prevent the model from “seeing” tokens that come after the current token.
However, this approach is only optimal for left-to-right text generation. There are many cases where the autoregressive approach is not the best. Among these cases are certain NLP applications such as translation or sentiment analysis, as well as approaches in computer vision. Currently, the transformer architecture has proven itself in most deep learning domains, and in many cases, it is not an autoregressive approach.
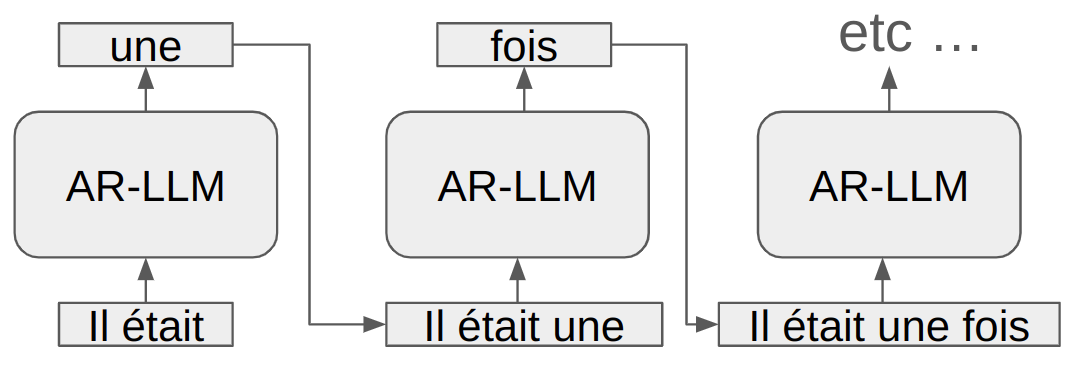
AR-LLM stands for auto regressive large language model.
The encoder block#
The encoder block is the left block shown in the architecture figure (highlighted in red again).
The only difference with the previously used block is that the multi-head attention layer is not masked. To draw an analogy with the previous notebooks, this means we use a full matrix instead of a lower triangular matrix for the attention calculation.
In practice, this means each token in the input sequence can interact with all other tokens (whether they come before or after). In cases like sentiment analysis, this is the preferred approach because we have a known input sequence and we want to predict a label (positive, negative, or neutral).
Note on sentiment analysis: In NLP, sentiment analysis involves giving the model a text and asking it to identify the sentiment associated with that text. For example, for a movie review, we want the model to predict negative for the review “This movie is a real flop” and positive for the review “For me, it’s the best movie of all time.”
Important point to consider: To predict the sentiment associated with a sentence, we only need to pass through the transformer once. For text generation, we must call the model after each generated token (so we pass through the model 10 times to generate 10 tokens).
Transformer models based solely on the encoder block have many uses beyond sentiment detection: spam detection, document classification, named entity extraction, and content recommendation. We will also see that for image processing, a variant of the transformer is used that can be likened to an encoder. In summary, we could say that the encoder block is suited for classification tasks (detection and segmentation for images as well).
Full architecture with cross-attention#
We still need to understand the usefulness of the full architecture. As a reminder, the article “Attention Is All You Need” that introduces the transformer is about automatic translation.
Let’s analyze the translation problem before understanding how the architecture works. In translation, we have a text in one language and we want to generate the same text in another language. Therefore, we have a generation part (decoder) and an encoding part of the available information.
We need to imagine that the decoder part that generates the tokens does so based both on the previously generated tokens and by querying the encoded part via the cross-attention layer.
Mathematical formulation#
The transformer’s encoder takes the source sequence \(x\) as input and produces a contextual representation for each token in this sequence: \(E = \text{Encoder}(x)\) Here, \(E\) is a matrix of contextual representations for the source sequence \(x\). Each row of \(E\) corresponds to a contextual representation \(e_i\) for the token \(x_i\).
The transformer’s decoder takes the contextual representations \(E\) from the encoder as input and generates the target sequence \(y\). At each generation step, the decoder produces a token \(y_t\) based on the previously generated tokens and by querying the encoder via the cross-attention layer: \(y_t = \text{Decoder}(y_{<t}, E) \) Here, \(y_{<t}\) represents the tokens generated so far up to step \(t-1\). The generation process uses both self-attention (to capture sequential dependencies in the target sequence) and cross-attention (to incorporate information from the encoder \(E\)).
The cross-attention allows the decoder to consult the contextual representations \(E\) from the encoder to obtain relevant information when generating each token \(y_t\). It is calculated as: \( \text{Cross-Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V \) where \(Q\) (query) are the embeddings of the tokens previously generated by the decoder, \(K\) (key) and \(V\) (value) are the embeddings from the encoder \(E\), and \(d_k\) is the dimension of the embeddings \(K\) for normalization.
By combining these elements, the transformer model can effectively translate a sequence of tokens from a source language to a target language using attention mechanisms and positional embeddings to maintain sequential order and capture long-term dependencies.
Notes: The decoder model attempts to generate a relevant token based on the tokens from the encoder. It will issue a query (query) and look at the keys (key) and values (value) transmitted by the encoder via the cross-attention layer. In a second step, it will issue a query, key, and value to find a token consistent with the tokens it has previously generated via the self-attention layer.
Usage examples#
The full architecture is used in cases where we want to generate text from another text. The most common applications are: translation, text summarization, automatic correction, and guided text generation.
Notes: You have probably noticed that ChatGPT is capable of translation and text summarization. Indeed, the model is so powerful that it can perform tasks that are theoretically difficult for it. It is trained to predict the next token, and with a bit of thought, one can easily imagine that the task of predicting the next token allows all NLP tasks to be performed. However, for more limited models, it is better to stick to an architecture suited to our problem.