Introduction to Hugging Face#
What is it?#
Hugging Face is a major player in the open-source artificial intelligence community. It offers a website that brings together datasets, models, and “spaces,” as well as several libraries (mainly transformers, diffusers, and datasets).
Why use Hugging Face? Hugging Face provides simplified access to cutting-edge complex models. It allows you to use these models quickly and efficiently. Additionally, you can test models via the site’s “spaces” category and download community datasets. In a way, it’s the “github” of deep learning.
What will we learn in this course?#
This course is less theoretical than previous ones, but it allows you to explore highly performant models and discover the current capabilities of deep learning. It draws on resources available on the Hugging Face website and the free course on deeplearning.ai titled “Open Source Models with Hugging Face.” I encourage you to check out this course, which covers many applications in vision, audio, and NLP.
Here is the course outline:
In this introduction, we present the Hugging Face website and its three main categories: Models, Datasets, and Spaces.
The next three notebooks focus on using the transformers library: the first covers vision models, the second NLP, and the third audio.
Then, a notebook is dedicated to the diffusers library, which allows you to use diffusion models (like Stable Diffusion) to generate images.
Finally, the last notebook introduces Gradio, a library for quickly creating interfaces for demonstrations.
Hugging Face Website#
Spaces#
The most fun and accessible category is Spaces, which groups demonstrations of various models.
Here’s what the homepage looks like:
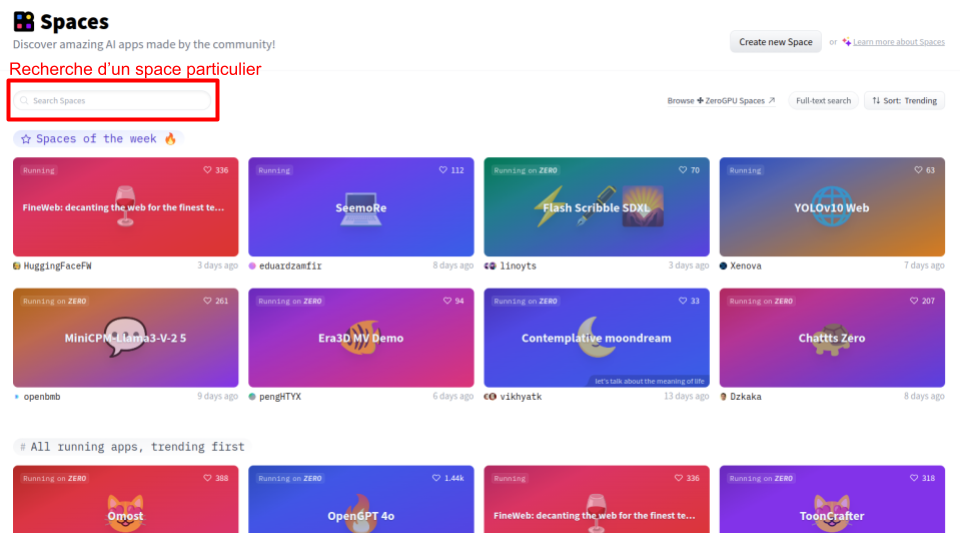
The demonstrations (spaces) are categorized by usage and popularity, but you can use the “Search spaces” function to find a specific model you want to test. I also recommend regularly browsing the different spaces to stay informed about the latest developments in deep learning.
If you train your own model, you can share it for free in a space using the “Create New Space” tool. To do this, you need to master the basics of the Gradio library, which we will cover in the last notebook of this course.
If you train your own model, you can share it for free in a space using the “Create New Space” tool. To do this, you need to master the basics of the Gradio library, which we will cover in the last notebook of this course.
Models#
Sometimes, a model you want to test is not available in the spaces, or you prefer to use it in your own code. In this case, you need to go through the Models category on the site. The Models page groups together many open-source models.
Here’s what the page looks like:
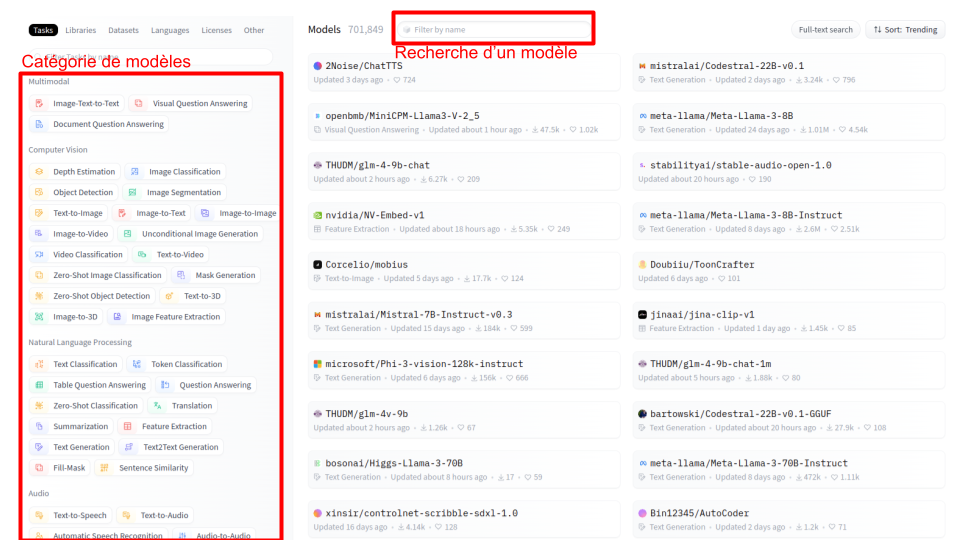
This page contains a lot of information. You can search for a specific model by name via “Filter by name”. You can also use the filters on the left to search for models by category.
For example, imagine I’m looking for a “zero-shot object detection” model, which allows you to detect any object in an image from a prompt.
What is a prompt? A prompt is an input that guides the model in its task. In NLP, a prompt is simply the model’s input, i.e., the text entered by the user. A prompt can also be a coordinate on an image (for a segmentation task) or even an image or video. Most of the time, when we talk about a prompt, it refers to adding text as input to the model. In the case of “zero-shot object detection,” if I want to detect bananas in an image, the model’s input will be the image and the text “banana”.
To find a model that might suit me, I use the left filtering by selecting the “zero-shot object detection” category and I check the proposed models.
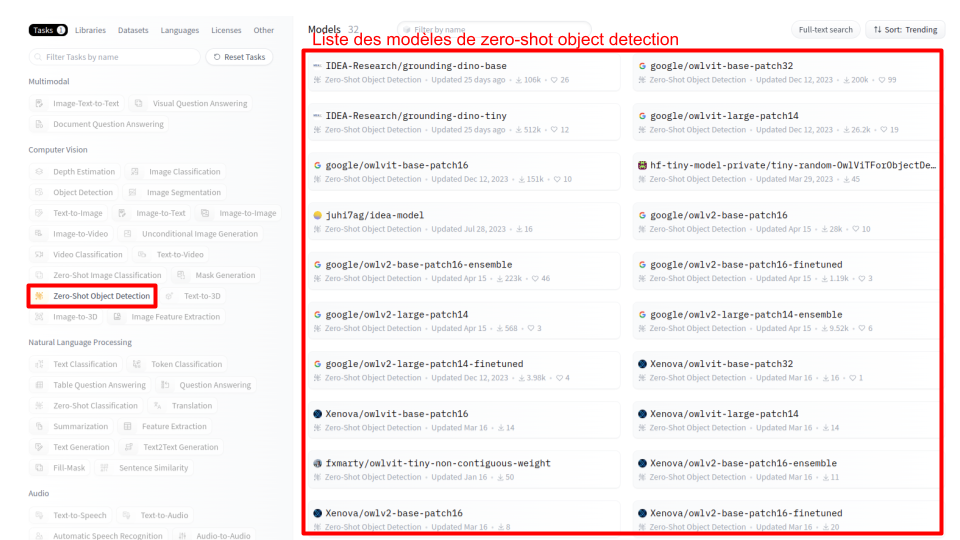
The model “IDEA-Research/grounding-dino-tiny” seems good to me, I select it and I arrive on the following page:
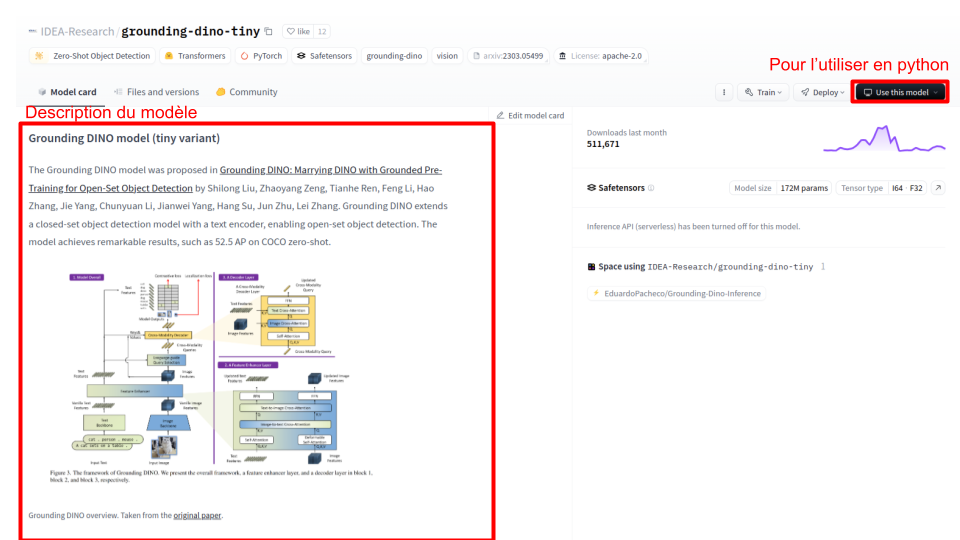
The model card provides a precise description of the model (its operation, capabilities, etc.). To get the code to use it directly in Python (via the transformers or diffusers library, depending on the chosen model), you can use the Use this model button.
For the chosen model, here is the corresponding code:
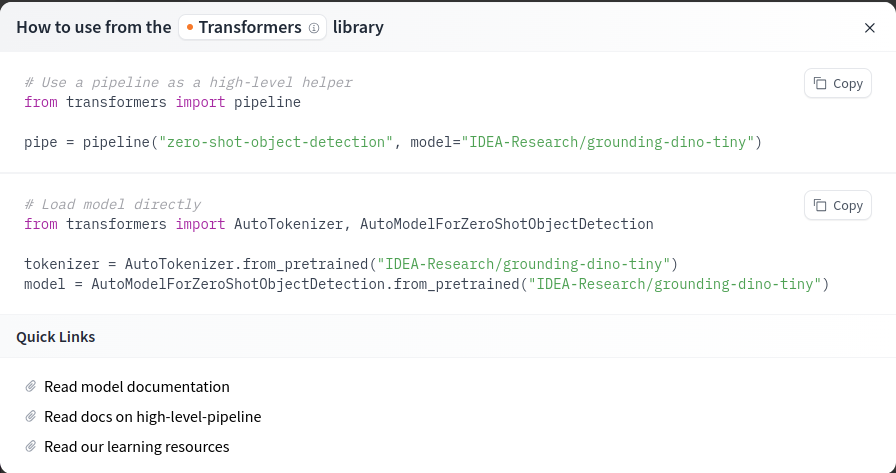
In the following notebooks, we will see how to use this code for our task.
Datasets#
If you want to train your own model, you need a dataset. You can choose to create it yourself, but there are many open-source datasets that you can find on Hugging Face.
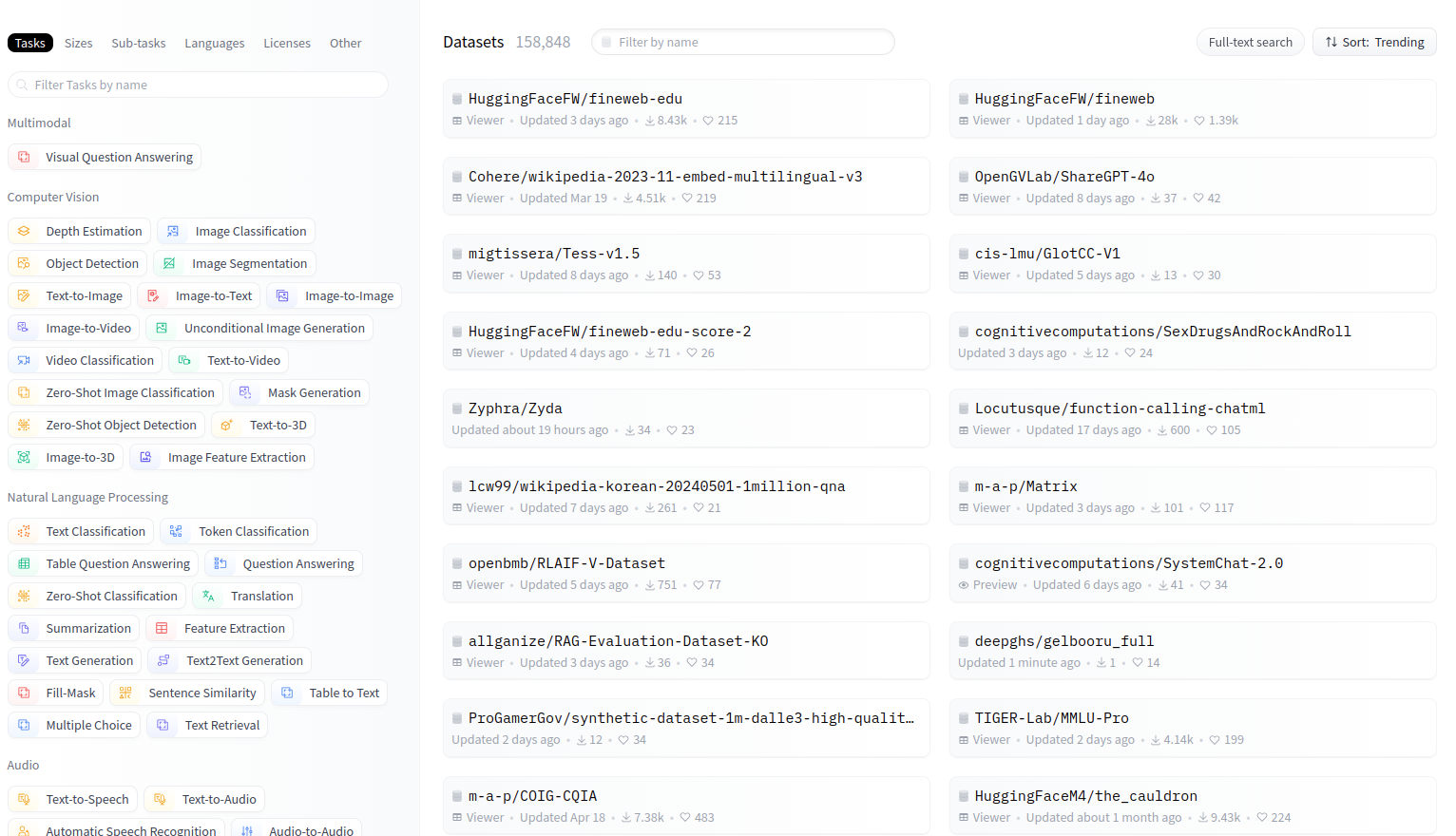
The Datasets page is similar to the Models page, with filtering and search functions:
You can select a dataset and arrive on the following page:
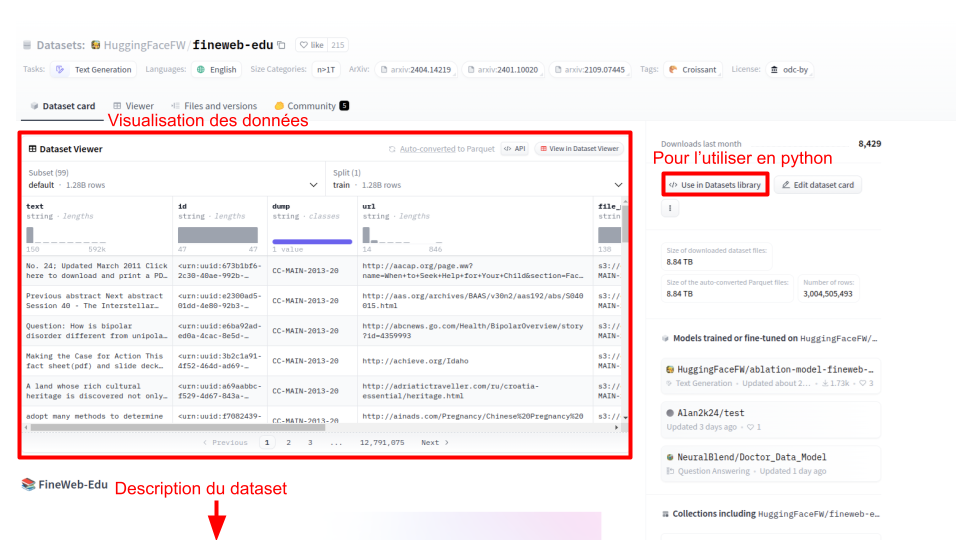
Like for models, the Dataset card allows you to view the dataset’s data and get a description of it. To use it directly in Python, you can use Use in Datasets library to get the corresponding Python code.
Other Categories#
The site is more comprehensive than this, but this introduction is not meant to be exhaustive. I invite you to explore the site on your own to discover things that interest you. In the following notebooks, we will present an overview of the types of models available and their use in Python via Hugging Face.