Transfer Learning#
Transfer learning is a common technique in deep learning. It involves reusing the weights of a pre-trained network as a base to train a new model.
Here are its main advantages:
Training is faster if the tasks are similar.
Performance is better than with a model trained from scratch.
Less data is required.
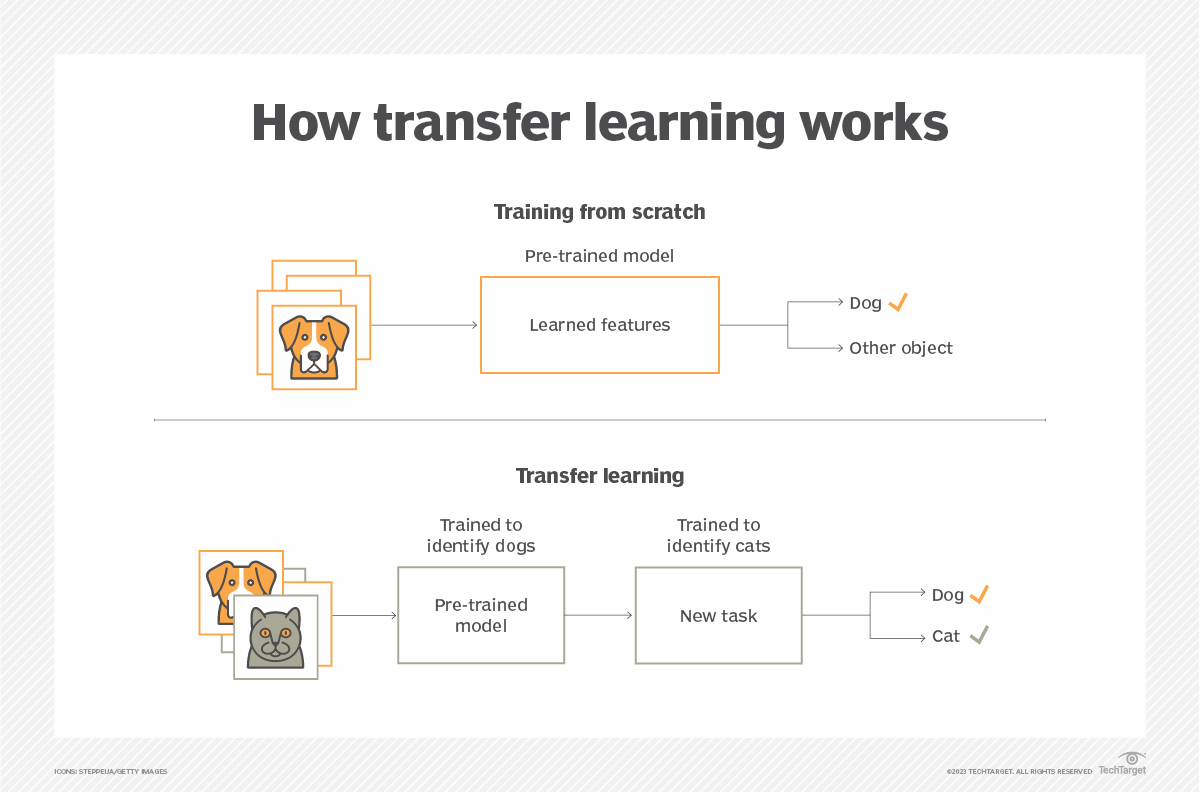
Figure from this article.
Transfer Learning or Fine-Tuning?#
These two terms are often confused as they are very similar. In practice, fine-tuning is a form of transfer learning that involves re-training only part of the layers of the reused model.
Here are the clear definitions:
Transfer Learning: Training a model using the weights of a pre-trained model on another task (you can re-train the entire model or just some layers).
Fine-Tuning: Re-training certain layers (often the last ones) of a pre-trained model to adapt it to a new task.
How to Use Fine-Tuning?#
Fine-tuning involves re-training certain layers of a pre-trained model to adapt it to a new task. Therefore, you need to choose the number of layers to re-train.
How to choose this number of layers? There is no fixed formula. We generally rely on our intuition and these rules:
The fewer data you have, the fewer layers you re-train (little data = only the last layer; a lot of data = almost all layers).
The more similar the tasks are, the fewer layers you re-train (e.g., detecting hamsters in addition to cats, dogs, and rabbits; detecting diseases from a cat/dog/rabbit model is very different).
When to Use Transfer Learning or Fine-Tuning?#
In general, using a pre-trained model as a base is always beneficial (unless the domains are very different). I recommend using it whenever possible.
However, this imposes some constraints:
The model architecture can no longer be modified as desired (the non-re-trained layers).
You need to have the weights of a pre-trained model (many are available online, see course 6 on HuggingFace).
Note: For image classification, a model pre-trained on ImageNet is often used because its 1000 classes make the model quite generalist.
Training Dataset: How to Proceed?#
When fine-tuning a model, you can have two objectives:
Case 1: Train a model on a completely different task from the one it was pre-trained for (e.g., classifying dinosaurs when the model is trained on mammals). In this case, the model can “forget” its original task without any issues.
Case 2: Train a model on a complementary task to the one it was pre-trained for (e.g., detecting birds while remaining performant on mammals). In this case, you want the model to remain performant on the original task.
Depending on the case, different data is used for training. For Case 1, the dataset contains only the new images to classify (e.g., only dinosaurs). For Case 2, data from both the old and new datasets is included so that the model remains performant on the old data. Generally, a 50/50 split is used, but this can vary (e.g., half mammals, half birds).
Note: According to this principle, true open-source means making the code, weights, and training data of the model accessible. Without these three elements, you cannot effectively fine-tune the model. This is particularly true for language models LLM.
Base Models#
Base models are trained on large amounts of data (often unlabeled) and serve as a basis for fine-tuning or transfer learning.
Base Models for NLP: For NLP, there are many base models such as GPT, BLOOM, Llama, Gemini, etc. These models are fine-tuned for various tasks. For example, chatGPT is a fine-tuned version of GPT for chatbot-type conversations.
Base Models for Images: For images, the term base model is debated as it is not as clear-cut as for NLP. Examples include ViT, DINO, CLIP, etc.
Base Models for Sound: For sound, the CLAP model is an example of a base model.