Fine-Tuning of LLMs#
In this course, we will study in detail the article BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, already mentioned in the course 7 on transformers.
Most LLMs (like GPT and BERT) are pre-trained on word prediction tasks (predicting the next word or masked words). They are then fine-tuned on more specific tasks. Without fine-tuning, these models are generally not very useful.
Note: Fine-tuning an LLM involves retraining all its parameters. In contrast, for vision models like CNNs, only part of the layers are often retrained (sometimes just the last one).
Differences between BERT and GPT#
In the course on transformers, we introduced GPT and implemented it. GPT is unidirectional: to predict a token, it only uses the previous tokens. However, this approach is not optimal for many tasks, as we often need the full context of the sentence.
BERT offers an alternative with a bidirectional transformer, which uses context from both sides for prediction. Its architecture allows fine-tuning on two types of tasks:
Sentence-level prediction: We predict the class of the entire sentence (e.g., for sentiment analysis).
Token-level prediction: We predict the class of each token (e.g., for named entity recognition).
Unlike GPT, BERT’s architecture is based on the transformer’s encoder block, not the decoder block (see course 7 for reference).
Tokens and embeddings#
First, note that the [CLS] token is added at the beginning of each input sequence. Its use will be explained later in the section on model fine-tuning.
During pre-training, BERT takes two sequences of tokens as input, separated by a [SEP] token. In addition to this separation, a segment embedding is added to each token embedding to indicate the original sentence (1 or 2). As with GPT, a position embedding is also added to each token embedding.
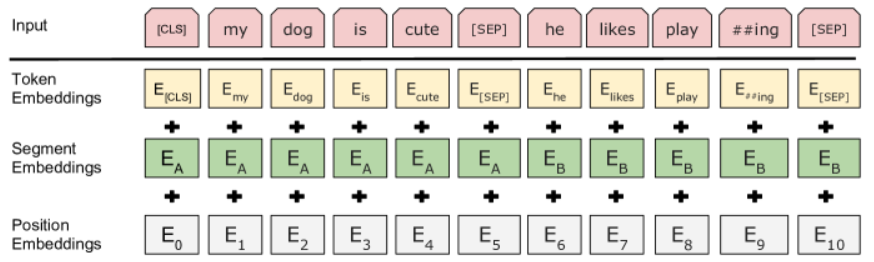
Note: The term “sentence” should not be understood in the linguistic sense, but rather as a sequence of tokens that follow each other.
Pre-training of BERT#
Task 1: Predicting Masked Words#
For GPT, training involved masking future tokens (the token to predict and those to the right). However, since BERT is bidirectional, this method is not applicable.
Instead, the authors propose randomly masking 15% of the tokens and training the model to predict these words. BERT is then called a Masked Language Model (MLM). The idea is to replace these tokens with [MSK] tokens.
During fine-tuning, there are no [MSK] tokens. To compensate for this, the authors suggest not converting all 15% of tokens to [MSK], but rather:
80% of tokens are converted to [MSK].
10% are replaced with another random token.
10% remain unchanged.
This technique improves the effectiveness of fine-tuning.
Note: Be careful not to confuse the term masked. The Masked Language Model (MLM) does not use a masked self-attention layer, unlike GPT (which is not an MLM).
Note 2: An interesting parallel can be drawn between BERT and a denoising autoencoder. Indeed, BERT corrupts the input text by masking certain tokens and attempts to predict the original text. Similarly, a denoising autoencoder corrupts an image by adding noise and attempts to predict the original image. The idea is similar, but in practice, there is a difference: denoising autoencoders reconstruct the entire image, while BERT only predicts the missing tokens without altering the other tokens in the input.
Task 2: Predicting the Next Sentence#
Many NLP tasks rely on the relationships between two sentences. These relationships are not directly captured by language modeling, hence the interest in adding a specific objective to understand them.
For this, BERT adds a binary next sentence prediction. We take sentence A and sentence B, separated by a [SEP] token. 50% of the time, sentences A and B follow each other in the original text, and 50% of the time, they do not. BERT must then predict whether these sentences follow each other.
Adding this training objective is very beneficial, especially for fine-tuning BERT on question-answering tasks, for example.
Data Used for Training#
The article also indicates the data used for training. This information is becoming increasingly rare nowadays.
BERT was trained on two datasets:
BooksCorpus (800 million words): A dataset containing approximately 7,000 books.
English Wikipedia (2,500 million words): A dataset containing the texts of the English version of Wikipedia (only the text, without lists, etc.).
Fine-Tuning of BERT#
Fine-tuning BERT is quite simple. We use the inputs and outputs of the desired task and retrain all the model’s parameters.
There are two main types of tasks:
Sentence-level prediction: For these tasks, we use the [CLS] token to extract the sentence classification. The [CLS] token allows the model to work regardless of the input sentence size (within the context limit), without bias related to token selection. Without the [CLS] token, we would have to use one of these two methods:
Connect all output embeddings to a fully connected layer to obtain the prediction (but this would not work for an arbitrary sequence size).
Predict from the embedding of a randomly selected token (but this could bias the result based on the selected token).
Token-level prediction: For this task, we predict a class for each token embedding, as we want a label per token.
Note: Fine-tuning BERT or another LLM is much less costly than pre-training the model. Once we have a pre-trained model, we can reuse it on a large number of tasks at a lower cost.