Convolutional Networks#
Intuition#
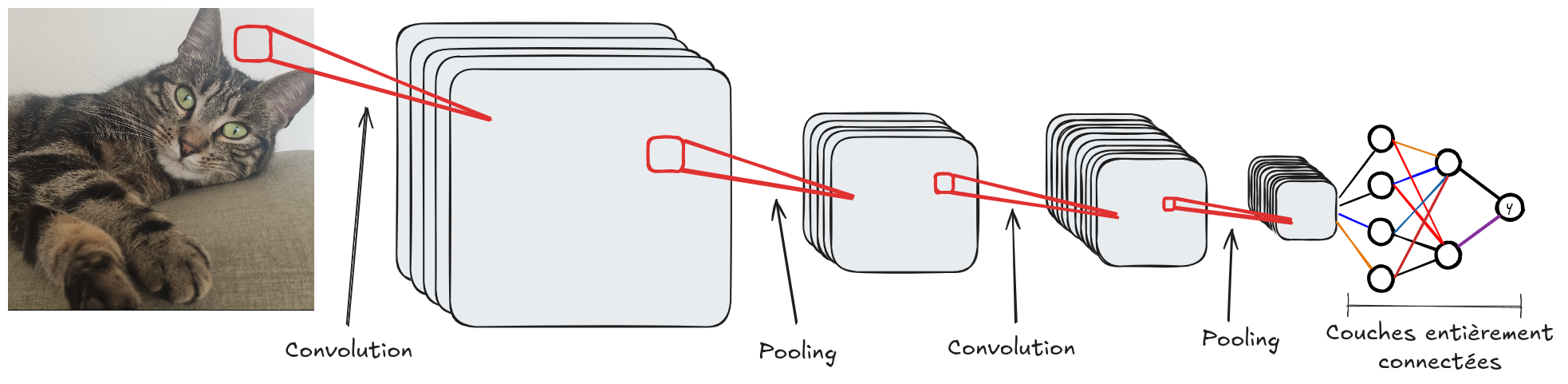
Like fully connected networks, convolutional networks consist of multiple layers. The idea is to increase the number of filters (channels) in depth while reducing the spatial resolution of the FeatureMaps. This increases abstraction: the first layers primarily detect edges, while the deeper layers capture more contextual information.
For a classification problem (such as MNIST), the final layers are often fully connected layers to adapt the convolution output to the number of classes.
A convolutional network typically consists of convolution, activation (ReLU, sigmoid, tanH, etc.), and pooling layers. The convolution layer adjusts the number of filters and adds trainable parameters. The activation layer makes the network non-linear, and the pooling layer reduces the spatial resolution of the image.
Here is the classic architecture of a convolutional network:
Receptive Field#
As seen previously, a single convolutional layer only allows local interaction between pixels (with a \(3 \times 3\) filter, each pixel is only influenced by its neighbors). This poses a problem for detecting elements covering the entire image.
However, stacking multiple convolutional layers increases the influence area of a pixel.
The following image illustrates this principle:
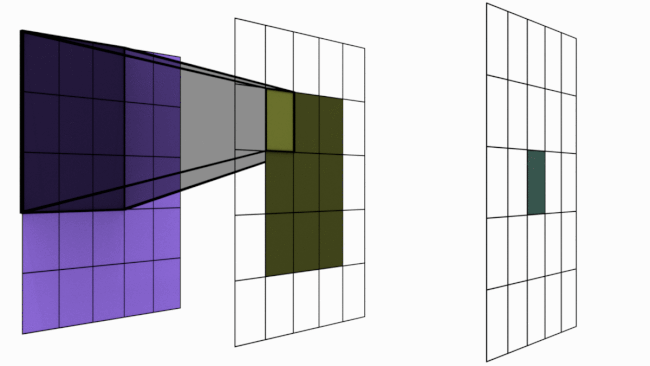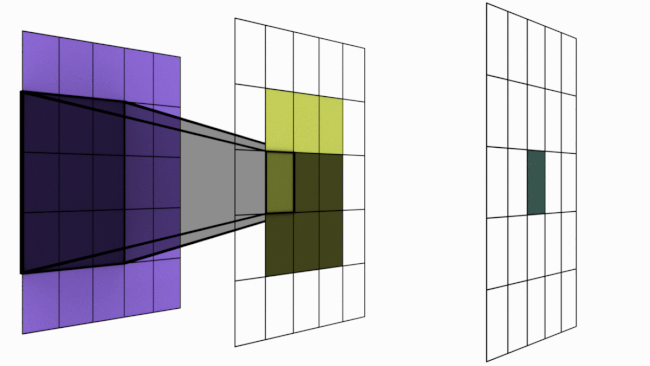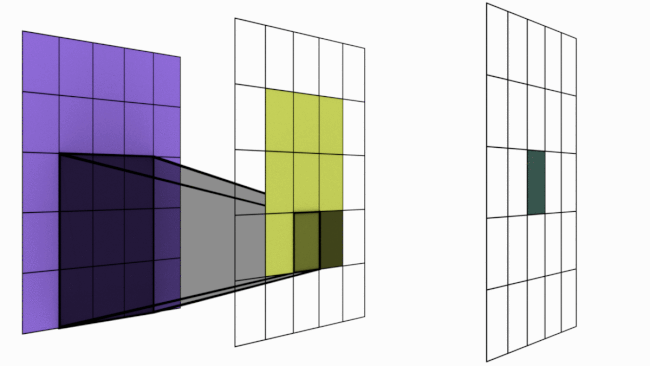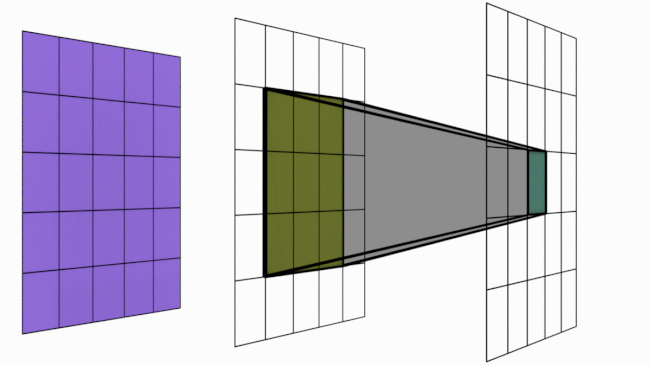
Figure extracted from blogpost.
More formally, the receptive field of a pixel is calculated with the formula:
\(R_{Eff}=R_{Init} + (k-1)*S\)
Where \(R_{Eff}\) is the receptive field of the output layer, \(R_{Init}\) is the initial field, \(k\) is the kernel size, and \(S\) is the stride.
When implementing convolutional networks, you need to check this parameter to ensure the network analyzes all pixel interactions. The larger the input image, the wider the receptive field must be.
Note: The tools seen previously to improve models (such as BatchNorm and Dropout) also apply to convolutional networks.
Visualization of What the Network Learns#
To understand the operation of a convolutional network and the role of each layer, you can visualize the activations of the FeatureMaps based on depth.
Here is a visualization based on network depth:
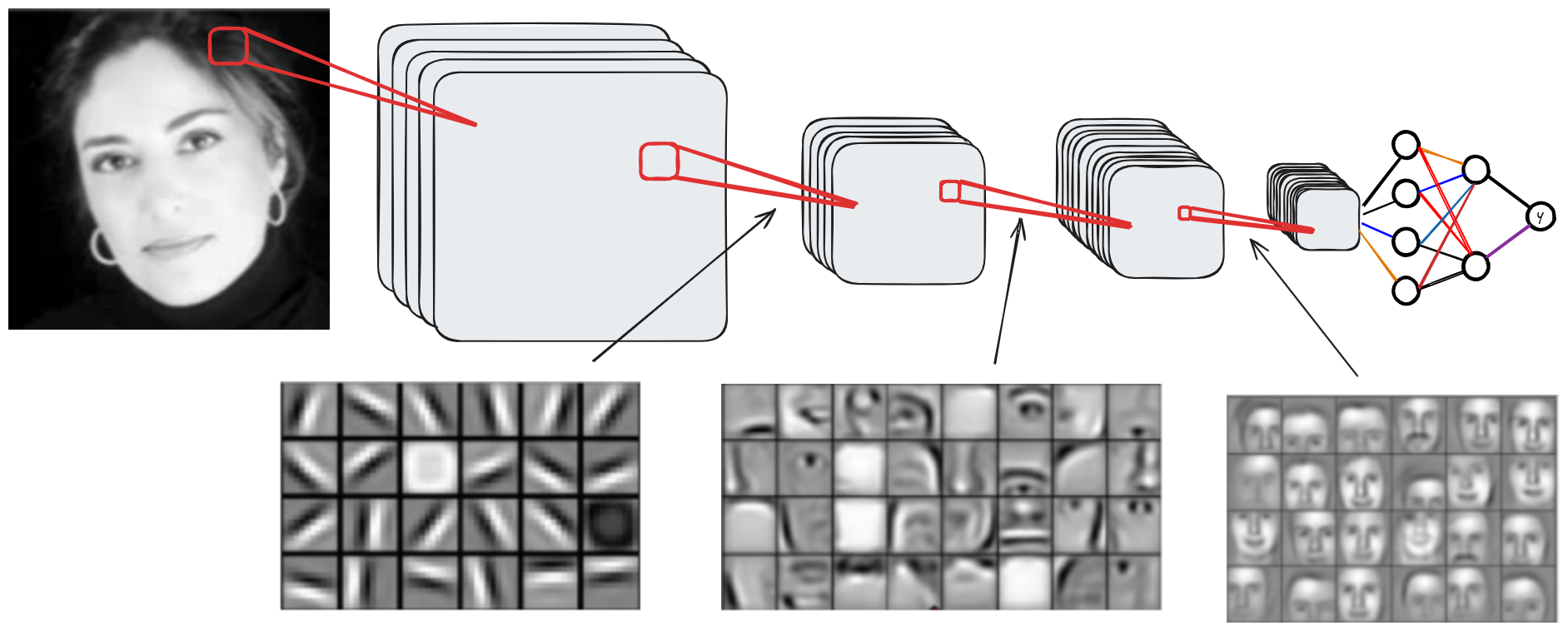
As seen, the shallow layers primarily capture local information (edges, basic shapes), while the deep layers contain contextual information. The intermediate layers contain information covering a significant part of the image.