交叉验证简介#
交叉验证(Cross-Validation)是一种用于精确评估深度学习模型在所有可用训练数据上的表现的方法。本课程内容参考了这篇博文,文中的示意图也来源于该博文。
深度学习模型的问题#
如前所述,过拟合(Overfitting)是深度学习模型常见的问题之一。想要了解更多关于过拟合的内容,可参阅正则化补充课程。仅在训练数据上表现优异是不够的,关键在于模型在测试数据上的表现。
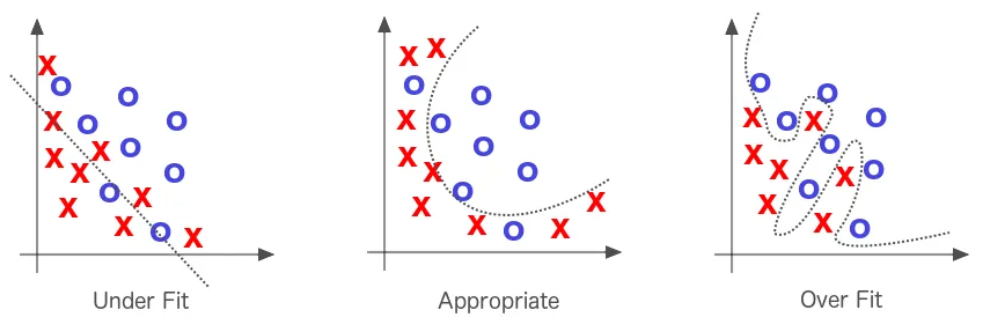
交叉验证是一种能够更容易检测过拟合并精确调整超参数以应对该问题的技术。
交叉验证的工作原理#
交叉验证技术可分为三个阶段:
将数据集划分为若干个子集。
保留一个子集,用剩余子集训练模型。
在保留的子集上测试模型。
重复后两个步骤,直到所有子集都被评估过。例如,将数据集分为10个子集,则需训练模型10次。所有训练完成后,通过计算模型在各次训练中的平均表现来评估其整体性能。
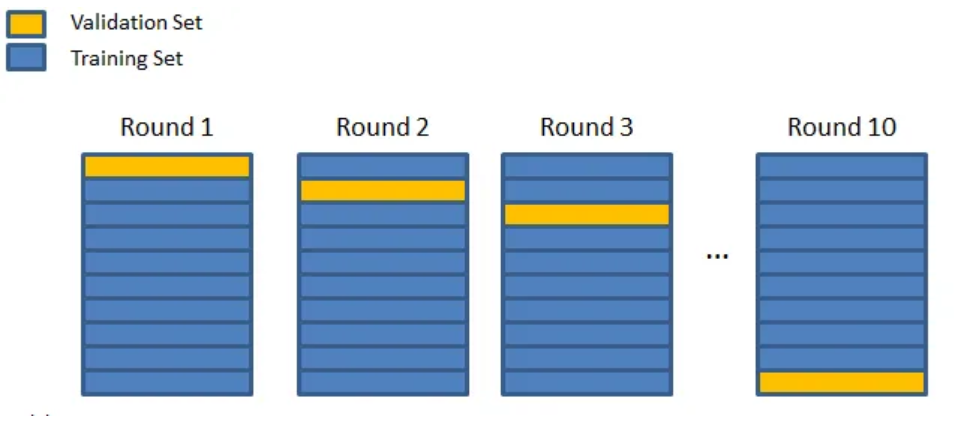
交叉验证有三种常见类型,它们之间差异不大:
k折交叉验证(k-fold cross validation)
分层k折交叉验证(stratified k-fold cross validation)
留一交叉验证(leave one out cross validation,LOOCV)
k折交叉验证#
k折交叉验证是最经典的交叉验证方法。具体步骤是将数据集分为k个子集,每次训练时使用不同的子集作为验证集,最终计算k次训练结果的平均分数来评估模型的整体性能。

如何选择参数k:
通常k应足够大,使每个子集能统计上代表原始数据集。
k的选择还需考虑时间和计算资源,k越大,训练次数越多。
一般情况下,k=10 是一个合理的选择。
分层k折交叉验证#
该方法与基本的k折交叉验证几乎相同,但增加了一个约束:每个子集必须保持相同的类别分布。这样能确保每个子集在各类别上的表现评估公平一致。
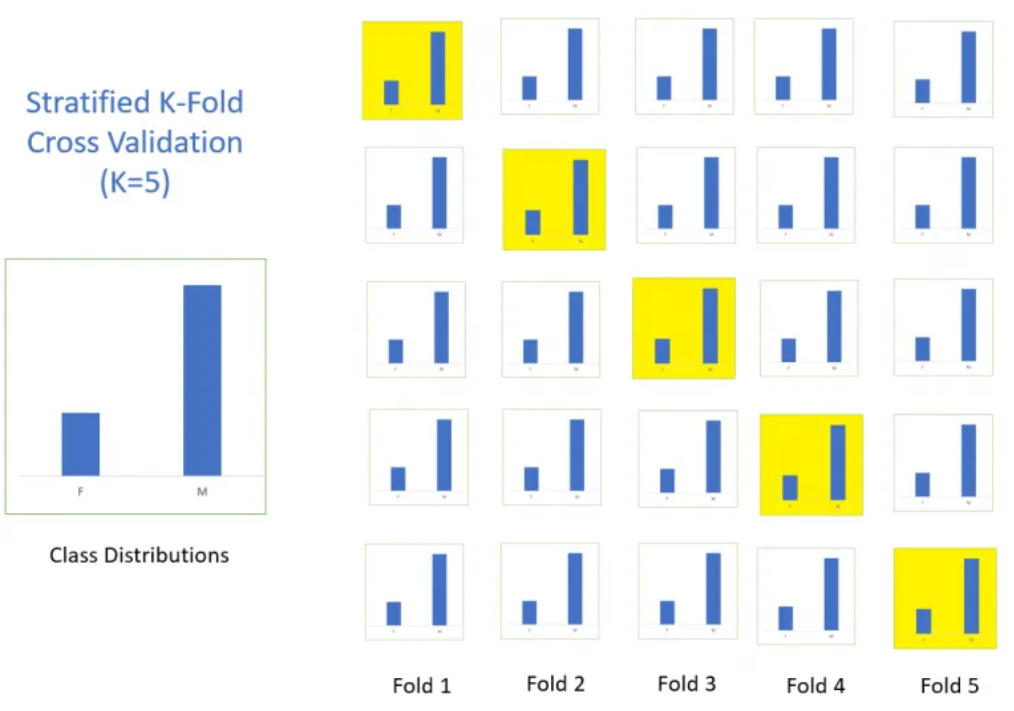
留一交叉验证#
该方法与k折交叉验证类似,只是将k设为数据集大小n(即 k=n)。每次训练时,模型使用除一个样本外的所有数据进行训练,相当于训练n次。虽然计算成本高,但其优势在于模型几乎能在所有数据上训练。在实际应用中,该方法较少使用,除非在小数据集微调(finetuning)场景下,其优势尤为明显。
交叉验证的优势#
交叉验证的主要优势包括:
更容易检测过拟合,并据此调整超参数。
在科学研究中,使用交叉验证能提供更可靠的模型评估,减少随机划分训练/验证集时带来的偶然性影响。
如果条件允许(时间和计算资源充足),建议系统性地使用交叉验证来评估模型。