大型语言模型的微调#
在本课程中,我们将详细研究论文《BERT: 深度双向 Transformer 的语言理解预训练》,该论文已在第 7 课:Transformer 的应用中提及。
大多数大型语言模型(如 GPT 和 BERT)首先在词预测任务(如下一个词预测或掩码词预测)上进行预训练,然后在更具体的任务上进行微调。若不进行微调,这些模型通常不太实用。
注意:微调大型语言模型需重新训练其所有参数。而对于视觉模型(如 CNN),通常只重新训练部分层(有时仅最后一层)。
BERT 与 GPT 的区别#
在 Transformer 课程中,我们介绍并实现了 GPT。GPT 是单向的:在预测某个 token 时,它仅使用前面的 token。然而,这种方法对许多任务并不理想,因为通常需要完整的句子上下文。
BERT 提出了一种基于双向 Transformer 的替代方案,它利用双侧上下文进行预测。其架构支持两类微调任务:
句子级别预测(sentence-level prediction):预测整个句子的类别(如情感分析)。
token 级别预测(token-level prediction):预测每个 token 的类别(如命名实体识别)。
与 GPT 不同,BERT 基于 Transformer 的编码器(encoder)而非解码器(decoder)(详见第 7 课回顾)。
Token 与嵌入#
首先,注意每个输入序列开头都会添加一个 [CLS] token。其用途将在模型微调部分详细说明。
在预训练阶段,BERT 的输入为两个 token 序列,由 [SEP] token 分隔。此外,每个 token 嵌入 还会添加一个 段嵌入,以标识其所属的原始句子(1 或 2)。与 GPT 类似,每个 token 嵌入 还会添加 位置嵌入。
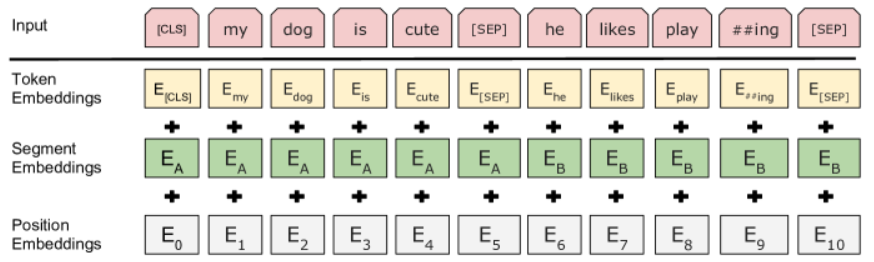
注意:“phrase”(句子)不应从语言学角度理解,而应视为一系列连续的 token。
BERT 的预训练#
任务 1:掩码词预测#
对于 GPT,训练时会掩盖未来的 token(即待预测的 token 及其右侧的 token)。然而,由于 BERT 是双向的,这种方法不适用。
作者提出随机掩盖 15% 的 token,并训练模型预测这些词。此时 BERT 被称为 掩码语言模型(Masked Language Model, MLM)。具体操作为:将这些 token 替换为 [MASK]。
在微调阶段,没有 [MASK] token。为弥补这一点,作者建议不对所有 15% 的 token 都替换为 [MASK],而是采用以下策略:
80% 的 token 替换为
[MASK]。10% 的 token 替换为随机 token。
10% 的 token 保持不变。
这种技术提升了微调的有效性。
注意 1:切勿混淆 masked 一词。掩码语言模型(MLM)不使用 掩码自注意力层,而 GPT(非 MLM)则使用该层。
注意 2:BERT 与 去噪自编码器 之间存在有趣的类比。BERT 通过掩盖输入文本中的部分 token 来“破坏”文本,并尝试预测原始文本;而 去噪自编码器 则通过添加噪声“破坏”图像,并尝试预测原始图像。二者理念相似,但实际操作有所不同:去噪自编码器 重建整个图像,而 BERT 仅预测缺失的 token,不改变输入中的其他 token。
任务 2:下一句预测#
许多 NLP 任务依赖于两个句子间的关系,而 语言模型 无法直接捕捉这些关系,因此需要添加专门的训练目标来理解它们。
为此,BERT 增加了 下一句预测(next sentence prediction)的二元分类任务。输入为句子 A 和句子 B,由 [SEP] token 分隔。在 50% 的情况下,句子 A 和 B 在原始文本中是连续的;在另外 50% 的情况下则不是。BERT 需要预测这两个句子是否连续。
添加这一训练目标对 BERT 的微调非常有益,特别是在问答任务中。
训练数据#
论文还列出了训练所用的数据,这类信息在当今已越发罕见。
BERT 使用了两个数据集进行训练:
BooksCorpus(8 亿词):包含约 7000 本书的数据集。
英语维基百科(25 亿词):仅包含维基百科英文版的正文内容(不含列表等)。
BERT 的微调#
BERT 的微调相对简单:使用目标任务的输入输出,并重新训练模型的所有参数。
任务主要分为两类:
句子级别预测(sentence-level prediction): 这类任务使用
[CLS]token 提取句子的分类结果。[CLS]token 使模型能处理任意长度的输入句子(在上下文限制内),且不受 token 选择偏见的影响。若没有[CLS]token,则需采用以下两种方法之一:将所有输出嵌入连接到全连接层以获得预测(但无法处理任意长度的序列)。
从随机选取的 token 嵌入中进行预测(可能因 token 选择而产生偏见)。
token 级别预测(token-level prediction): 这类任务为每个 token 嵌入预测一个类别,因其需为每个 token 分配标签。
注意:BERT 或其他大型语言模型的微调成本远低于模型的预训练。一旦拥有预训练模型,便可低成本地重复利用于多种任务。