生成模型简介#
在之前的课程中,我们学习了各种深度学习模型,包括判别模型和生成模型。本课程将重点介绍生成模型,详细解释其工作原理,并提供具体示例和实现代码。
判别模型和生成模型#
判别模型与生成模型的定义如下:
判别模型(Discriminative Model) 目标是区分不同类型的数据。训练时使用输入数据 \(X\) 及其对应标签 \(Y\),旨在对新输入的数据进行分类。常见应用包括:
图像/文本/音频分类
目标检测
图像分割
生成模型(Generative Model) 目标是学习数据的分布,以生成与训练数据相似的新样本。与判别模型不同,训练过程不依赖标签。我们曾在NLP课程5中介绍过部分生成模型。
注:
标准**自编码器(Autoencoder)**不属于上述任一类别,因其既不预测标签,也不学习输入数据的概率分布。
**变分自编码器(VAE)**基于类似架构,但能学习数据的概率分布。
从形式化角度看:
判别模型学习条件概率 \(P(X \mid Y)\);
生成模型学习数据分布 \(P(X)\)(无标签)或联合分布 \(P(X,Y)\)(有标签)。
课程内容#
本课程将介绍主要的生成模型家族,并为每种模型提供实现示例:
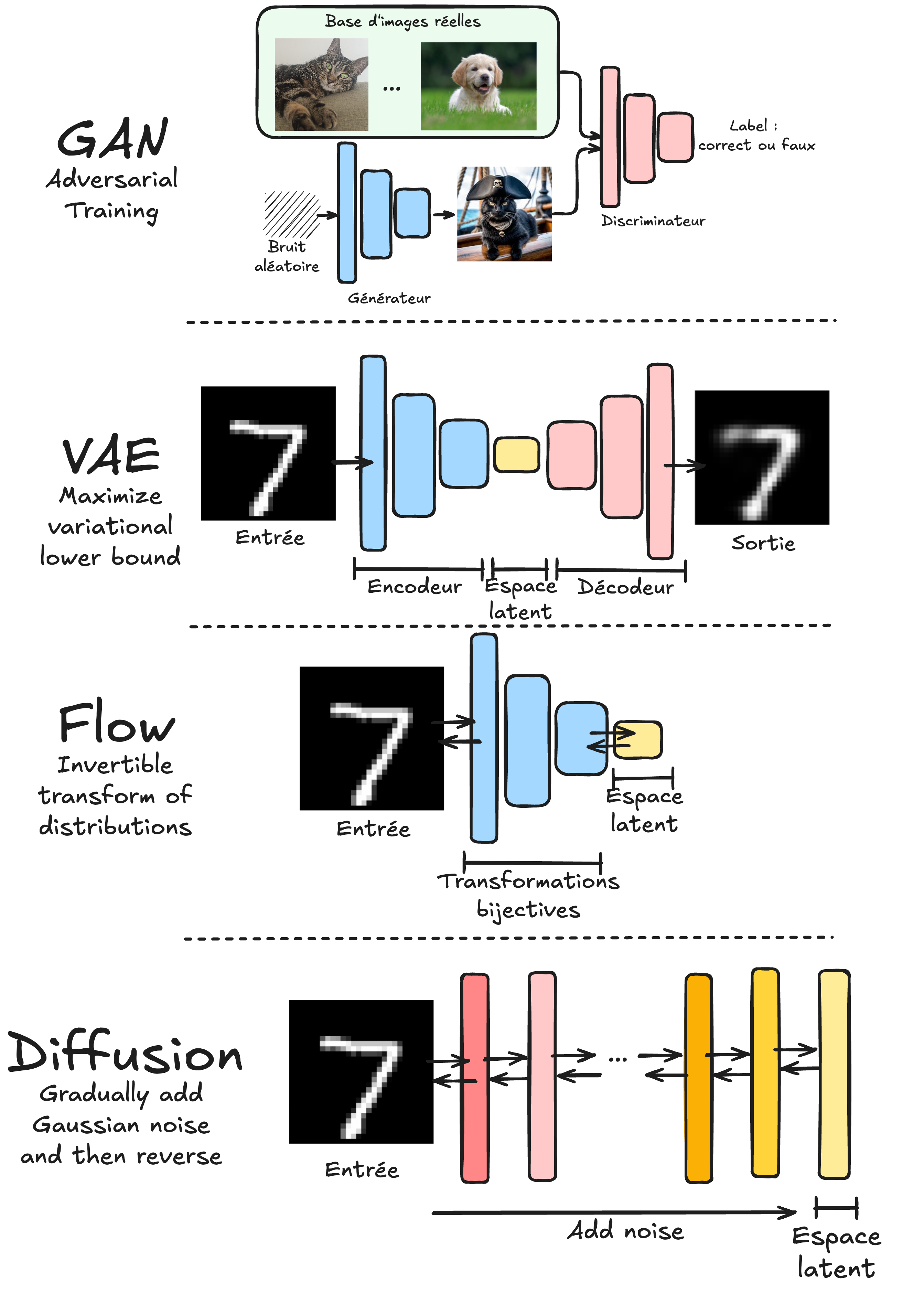
GAN(生成对抗网络)
Notebook 2 & 3涵盖 GAN 的原理。
核心机制:由生成器(生成与训练数据分布相似的样本)和判别器(区分真实数据与生成数据)两个模型对抗训练。
VAE(变分自编码器)
Notebook 4 & 5详解 VAE。
与传统自编码器不同,VAE 在潜在空间中学习数据的概率分布,而非确定性表示。
Normalizing Flows(归一化流)
Notebook 6 & 7探讨 Normalizing Flows。
通过双射变换,将简单分布(如高斯分布)转换为训练数据的复杂分布。
Diffusion Models(扩散模型)
Notebook 4 & 5介绍扩散模型。
训练网络逐步去噪,从高斯噪声迭代生成图像。
注 1: 自回归模型(如 GPT)未在此课程中展开,详见NLP课程5。
注 2: 本课程为生成模型的入门教程。欲深入学习,可参考斯坦福 CS236 课程: