长短期记忆网络(LSTM)#
在之前的笔记本中,我们介绍了经典的循环神经网络(RNN)层。自其发明以来,已开发出多种其他循环层结构。
这里,我们将介绍长短期记忆网络(LSTM)层,它是经典 RNN 层的一种替代方案。
什么是 LSTM 层?#
LSTM 层由一个记忆单元和 4 个全连接层组成。其中三个层用于选择前一步骤中的相关信息:即遗忘门(forget gate)、输入门(input gate)和输出门(output gate)。
遗忘门:从记忆中删除信息
输入门:向记忆中插入信息
输出门:使用存储的信息
第四个全连接层生成记忆单元的“候选信息”。
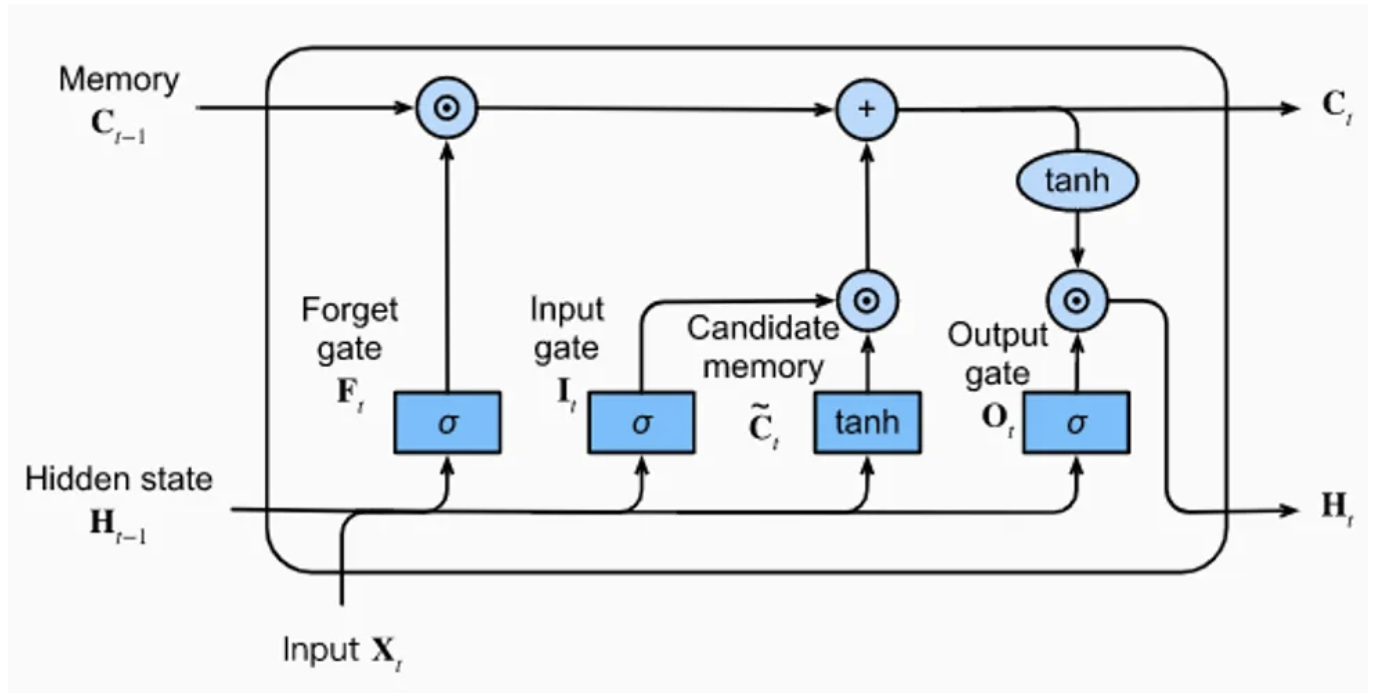
图片来源:博客文章。
如图所示,LSTM 层接收 3 个输入向量:\(H_{t-1}\)、\(C_{t-1}\) 和 \(X_{t}\)。前两个直接来自 LSTM 本身,\(X_{t}\) 是当前时刻 \(t\) 的输入(在本例中是一个字符)。
简单来说:
\(H_{t-1}\) 包含短期记忆
\(C_{t-1}\) 包含长期记忆
这种结构能够在保留广泛上下文的重要信息的同时,不忽视局部上下文。
LSTM 的核心思想是解决经典 RNN 在长序列中信息传播的问题。
PyTorch 实现#
import torch
import torch.nn as nn
数据集#
为创建数据集,我们仍使用 moliere.txt 文件,并沿用前一个笔记本中的代码。
with open('moliere.txt', 'r', encoding='utf-8') as f:
text = f.read()
print("Nombre de caractères dans le dataset : ", len(text))
Nombre de caractères dans le dataset : 1687290
我们减少了元素数量以加快训练(若需完整训练,可取消注释相关代码)。
text=text[:100000]
print("Nombre de caractères dans le dataset : ", len(text))
Nombre de caractères dans le dataset : 100000
chars = sorted(list(set(text)))
vocab_size = len(chars)
print(''.join(chars))
print("Nombre de caractères différents : ", vocab_size)
!'(),-.:;?ABCDEFGHIJLMNOPQRSTUVYabcdefghijlmnopqrstuvxyz«»ÇÈÉÊàâæçèéêîïôùû
Nombre de caractères différents : 76
stoi = { ch:i for i,ch in enumerate(chars) }
itos = { i:ch for i,ch in enumerate(chars) }
encode = lambda s: [stoi[c] for c in s] # encode : prend un string et output une liste d'entiers
decode = lambda l: ''.join([itos[i] for i in l]) # decode: prend une liste d'entiers et output un string
data = torch.tensor(encode(text), dtype=torch.long)
将数据集分为训练集和测试集。
n = int(0.9*len(data)) # 90% pour le train et 10% pour le test
train_data = data[:n]
test = data[n:]
模型构建#
构建模型时,我们直接使用 PyTorch 提供的 LSTM 层实现。与线性层或卷积层不同,nn.LSTM 允许通过 num_layers 参数堆叠多个层。若需逐层定义,可使用 nn.LSTMCell。
class lstm(nn.Module):
def __init__(self, vocab_size, hidden_size,num_layers=1):
super(lstm, self).__init__()
self.hidden_size = hidden_size
# On utilise un embedding pour transformer les entiers(caractères) en vecteurs
self.embedding = nn.Embedding(vocab_size, hidden_size)
# La couche LSTM peut prendre l'argument num_layers pour empiler plusieurs couches LSTM
self.lstm = nn.LSTM(hidden_size, hidden_size, num_layers=num_layers)
# Une dernière couche linéaire pour prédire le prochain caractère
self.fc = nn.Linear(hidden_size, vocab_size)
def forward(self, x, hidden):
x = self.embedding(x)
x, hidden = self.lstm(x, hidden)
x = self.fc(x)
return x, (hidden[0].detach(), hidden[1].detach())
def init_hidden(self, batch_size):
return (torch.zeros(1, batch_size, self.hidden_size), torch.zeros(1, batch_size, self.hidden_size))
训练#
epochs = 20
lr=0.001
hidden_dim=128
seq_len=100
num_layers=1
model=lstm(vocab_size,hidden_dim,num_layers)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
LSTM 层接收一个序列并输出相同长度的序列。这种方式加速了训练,因为可以同时处理多个示例。
注意:还可以通过并行处理多个序列(即批处理)来进一步加速训练。
for epoch in range(epochs):
state=None
running_loss = 0
n=0
data_ptr = torch.randint(100,(1,1)).item()
# On train sur des séquences de seq_len caractères et on break si on dépasse la taille du dataset
while True:
x = train_data[data_ptr : data_ptr+seq_len]
y = train_data[data_ptr+1 : data_ptr+seq_len+1]
optimizer.zero_grad()
y_pred,state = model.forward(x,state)
loss = criterion(y_pred, y)
running_loss += loss.item()
n+=1
loss.backward()
optimizer.step()
data_ptr+=seq_len
# Pour éviter de sortir de l'index du dataset
if data_ptr + seq_len + 1 > len(train_data):
break
print("Epoch: {0} \t Loss: {1:.8f}".format(epoch, running_loss/n))
Epoch: 0 Loss: 2.17804336
Epoch: 1 Loss: 1.76270216
Epoch: 2 Loss: 1.62740668
Epoch: 3 Loss: 1.54147145
Epoch: 4 Loss: 1.47995140
Epoch: 5 Loss: 1.43100239
Epoch: 6 Loss: 1.39074463
Epoch: 7 Loss: 1.35526441
Epoch: 8 Loss: 1.32519794
Epoch: 9 Loss: 1.29712536
Epoch: 10 Loss: 1.27268774
Epoch: 11 Loss: 1.24876227
Epoch: 12 Loss: 1.22720749
Epoch: 13 Loss: 1.20663312
Epoch: 14 Loss: 1.18768359
Epoch: 15 Loss: 1.16936996
Epoch: 16 Loss: 1.15179397
Epoch: 17 Loss: 1.13514291
Epoch: 18 Loss: 1.11997525
Epoch: 19 Loss: 1.10359089
现在,我们可以在测试数据上评估损失值。
state=None
running_loss = 0
n=0
data_ptr = torch.randint(100,(1,1)).item()
while True:
with torch.no_grad():
x = test[data_ptr : data_ptr+seq_len]
y = test[data_ptr+1 : data_ptr+seq_len+1]
y_pred,state = model.forward(x,state)
loss = criterion(y_pred, y)
running_loss += loss.item()
n+=1
data_ptr+=seq_len
if data_ptr + seq_len + 1 > len(test):
break
print("Loss de test: {0:.8f}".format(running_loss/n))
Loss de test: 1.51168611
该模型存在较明显的过拟合现象… 请尝试自行解决。
文本生成#
现在,我们可以测试文本生成功能!
import torch.nn.functional as F
moliere='.'
sequence_length=250
state=None
for i in range(sequence_length):
x = torch.tensor(encode(moliere[-1]), dtype=torch.long).squeeze()
y_pred,state = model.forward(x.unsqueeze(0),state)
probs=F.softmax(torch.squeeze(y_pred), dim=0)
sample=torch.multinomial(probs, 1)
moliere+=itos[sample.item()]
print(moliere)
.
Çà coeuse, et bon enfin l'avoir faire.
MASCARILLE.
En me donner d vous, Le pas.
MASCARILLE, à dans un pour sûte matinix! cette ma foi.
PANDOLFE.
Ma foi, tu te le sy sois touves d'arrête sa bien sans les bonheur.
MASCARILLE.
Moi, je me suis to
生成的文本比基础 RNN 模型略有改善,但尚不理想。您可以尝试通过调整参数(如层数、隐藏层维度等)来提升性能。