知识蒸馏#
知识蒸馏的概念最早出现在 2015 年的论文《Distilling the Knowledge in a Neural Network》中。其核心思想是:利用一个已训练好的深度模型(称为教师模型,teacher)将其知识传递给一个更小的模型(称为学生模型,student)。
工作原理#
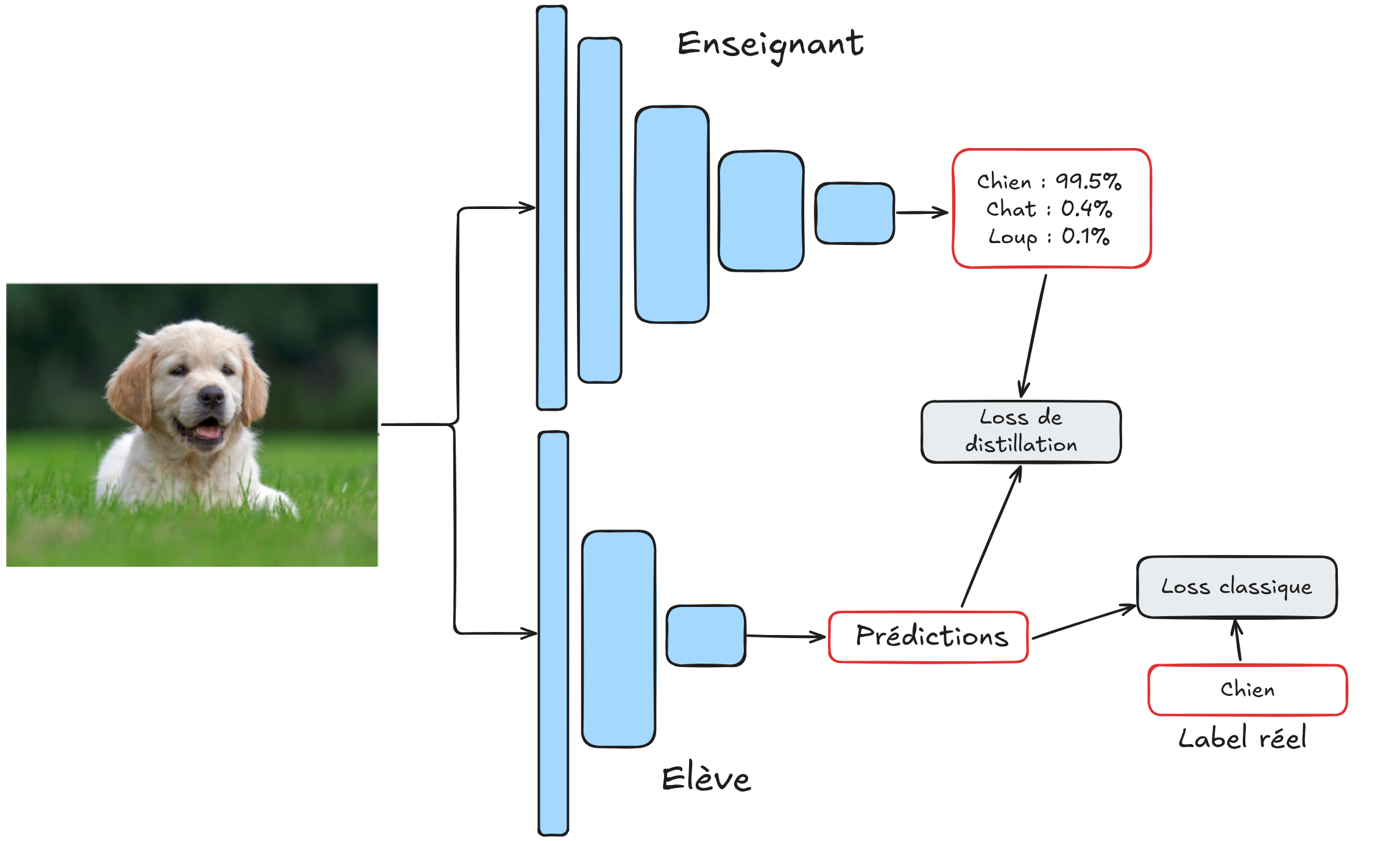
在实践中,学生模型的训练基于两个目标:
最小化其预测结果与教师模型对同一输入的预测结果之间的差异;
最小化其预测结果与输入数据真实标签之间的差异。
这两个损失函数通过一个可调权重因子 \(\alpha\) 进行组合。因此,学生模型同时利用了输入图像的真实标签和教师模型的预测分布(概率分布)。
注意:在实际应用中,第一个损失函数通常比较的是教师模型和学生模型在 softmax 函数应用前的原始输出(即 logits),而非概率值。为了表述简洁,本文统一使用“预测”一词代替 logits。
为何有效?#
与直接使用标签训练学生模型的传统方法相比,知识蒸馏为何能取得更佳效果?以下是几个关键原因:
隐性知识传递:教师模型的预测(如概率分布)能揭示数据中类别间的相似性等隐性信息,学生模型通过模仿这些预测,能学习到数据中隐含的模式。
复杂关系保留:教师模型通常结构复杂,能捕捉数据中的高阶特征,学生模型通过蒸馏可高效学习这些复杂关系,同时保持推理速度快、内存占用低的优势(因其模型规模更小)。
训练稳定性提升:实践表明,采用蒸馏方法训练的学生模型收敛更稳定。
标注噪声缓解:教师模型具备良好的泛化能力,即使训练数据存在标注错误,其预测仍相对可靠。在蒸馏过程中,学生模型可通过比较教师模型输出与标签的差异,识别数据质量问题。
实际应用#
在实际应用中,知识蒸馏可将大型高性能模型的知识迁移至小型模型,且几乎不损失预测精度。这在以下场景中尤为实用:
模型轻量化:适用于嵌入式设备或 CPU 环境,显著降低计算资源需求;
多教师蒸馏:可将多个教师模型的知识融合至单一学生模型,某些情况下,学生模型甚至能超越所有教师模型的单独表现。
知识蒸馏是一种通用且高效的技术,值得在多种场景中应用。
拓展应用#
自诞生以来,知识蒸馏已被广泛应用于解决各类问题。本节将介绍两个典型案例:
利用 NoisyStudent 提升图像分类性能;
利用 STPM 实现无监督异常检测。
Noisy Student:分类性能优化#
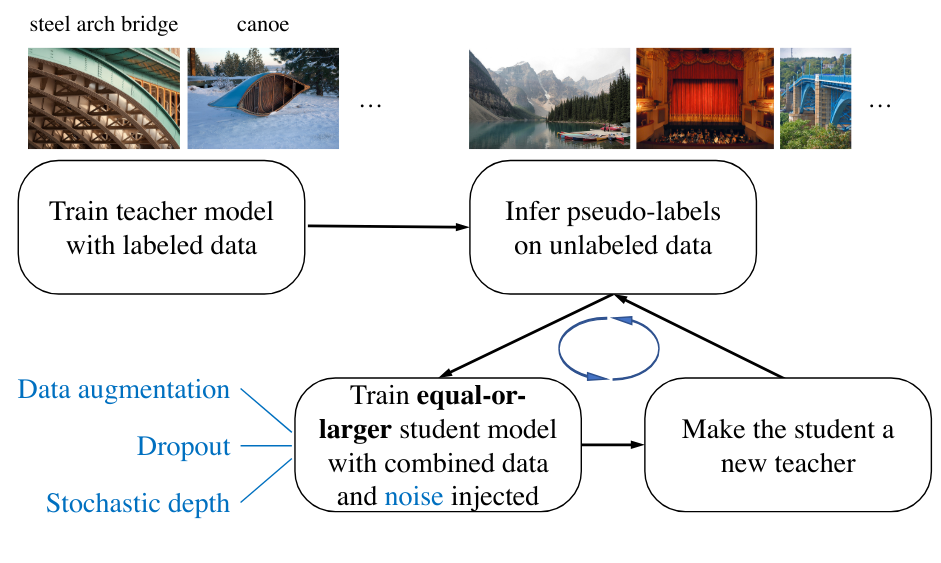
长期以来,ImageNet 数据集的性能竞赛一直是深度学习研究的核心。2020 年的论文《Self-training with Noisy Student improves ImageNet classification》提出了一种创新方法:通过知识蒸馏,使学生模型在每次迭代中超越教师模型。
具体流程如下:
教师模型为未标注图像生成伪标签(pseudo-labels);
学生模型基于这些伪标签训练,并引入噪声(如数据增强)以提升鲁棒性;
训练完成后,学生模型替代教师模型,为新一轮未标注数据生成更优的伪标签;
重复上述过程,最终得到性能远超初始教师模型的模型。
STPM:无监督异常检测#
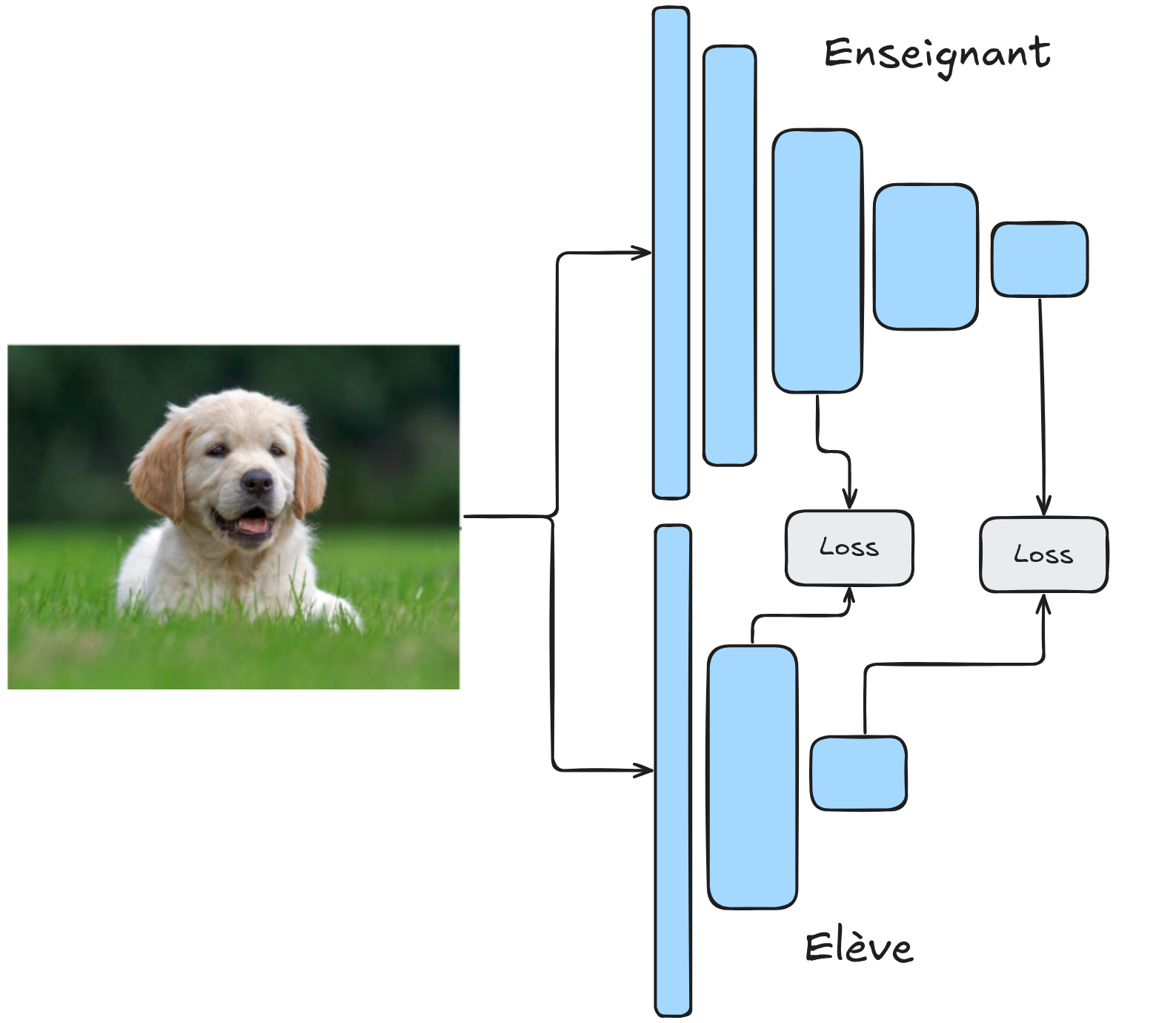
知识蒸馏在无监督异常检测中的应用典范是 STPM(Student-Teacher Feature Pyramid Matching)方法。该方法的核心创新在于:
架构对称:教师模型与学生模型采用相同的网络结构;
特征对齐:训练阶段关注网络中间层的特征图(feature maps),而非最终预测。使用无异常数据训练时,教师模型(预训练于 ImageNet 并固定参数)学生模型(随机初始化)被训练以复现教师模型的特征图。训练完成后,两者在无异常数据上的特征图应完全一致。
在测试阶段:
对于无异常数据,学生模型的特征图与教师模型高度一致;
对于异常数据,两者特征图差异显著。通过计算特征图的相似度得分,可实现异常检测。
实验证明,STPM 是目前无监督异常检测领域性能最优的方法之一。接下来的 notebook 将实现该方法。