Transformer 模型简介#
在上一章中,我们探索了 Hugging Face 的 Transformers 库的多种应用。顾名思义,这个库主要处理 Transformer 模型。那么,什么是 Transformer 模型呢?
Transformer 的起源#
在 2017 年之前,自然语言处理(NLP)领域的大多数神经网络都采用 循环神经网络(RNN) 架构。2017 年,Google 的研究人员发表了一篇论文,彻底改变了 NLP 领域,并随后影响了深度学习的其他分支(如计算机视觉、音频处理等)。他们在论文 “Attention Is All You Need” 中提出了 Transformer 架构。
Transformer 的架构示意图如下:
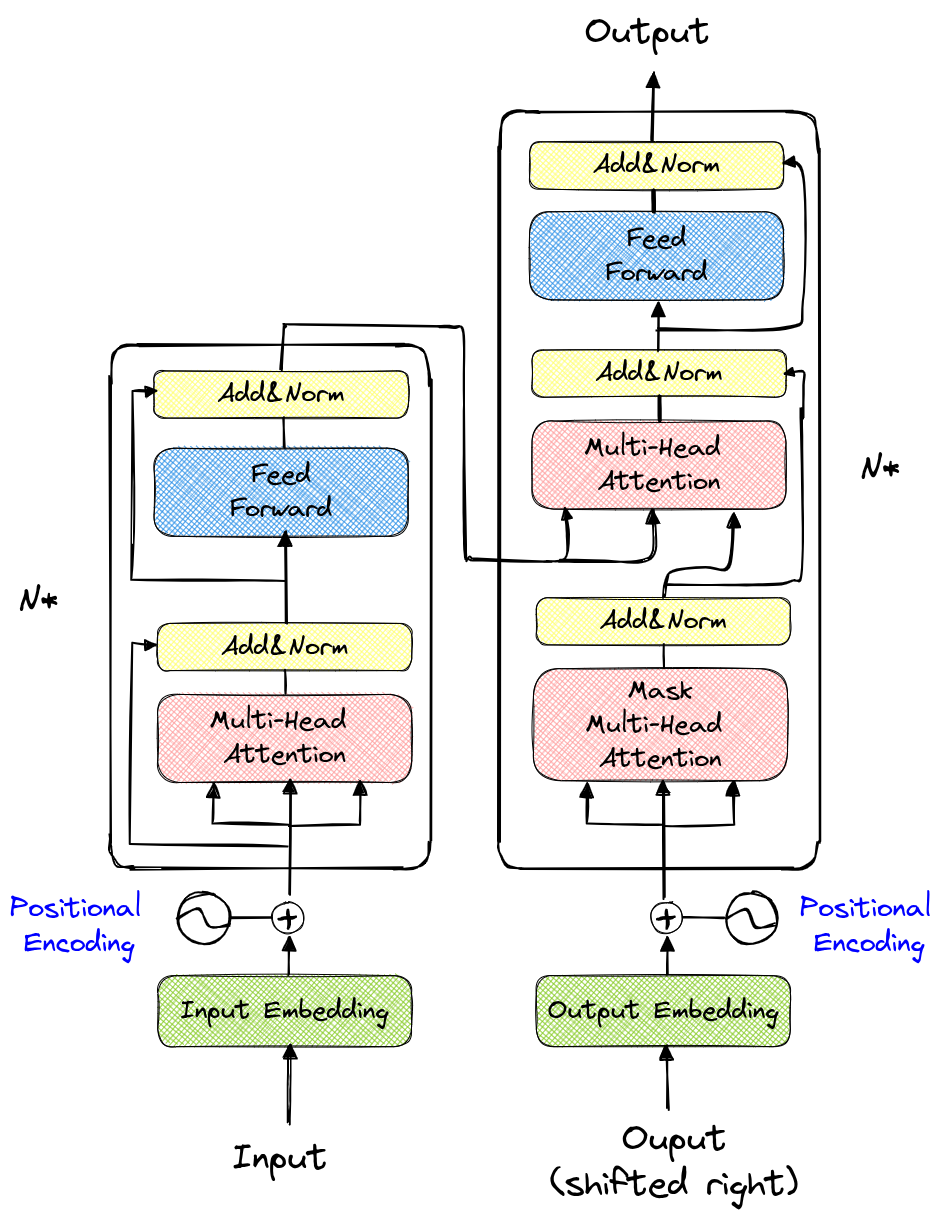
乍看之下,这个架构似乎非常复杂。图中,左侧部分称为 编码器(Encoder),右侧部分称为 解码器(Decoder)。
课程内容概览#
第一部分:从零开始构建 GPT#
本课程的第一部分深受 Andrej Karpathy 的视频 “Let’s build GPT: from scratch, in code, spelled out.” 启发。我们将实现一个模型,该模型基于前文字符预测下一个字符(类似于第 5 课中的 NLP 任务)。这部分内容将帮助我们理解 Transformer 架构的优势,特别是其 解码器部分。
在本部分中,我们将训练一个模型,自动生成“莫里哀风格”的文本。
第二部分:理论与编码器#
第二部分将介绍一些更深入的数学概念,并详细讲解 Transformer 架构中的解码器。
第三部分:ViT、BERT 与其他经典架构#
第三部分将简要介绍 Transformer 架构 在 GPT 以外任务中的改进与应用。
第四部分:Vision Transformer 的实现#
第四部分将基于论文 《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》 实现 Vision Transformer(ViT),并使用 CIFAR-10 数据集 进行训练。
第五部分:Swin Transformer 的实现#
第五部分(也是最后一部分)将解读论文 《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》,并提供一个 简化版的实现。