Introduction à la validation croisée#
La validation croisée, ou cross-validation, est une méthode qui permet d’évaluer précisément un modèle de deep learning sur l’ensemble des données disponibles pour l’entraînement. Ce cours s’inspire du blogpost, et les figures utilisées proviennent également de ce blogpost.
Problèmes des modèles de deep learning#
Comme vu précédemment, un des problèmes des modèles de deep learning est l’overfitting. Pour en savoir plus sur l’overfitting, vous pouvez consulter le cours bonus sur la régularisation. En effet, il ne suffit pas d’avoir un modèle performant sur les données d’entraînement, il faut surtout qu’il soit performant sur les données de test.
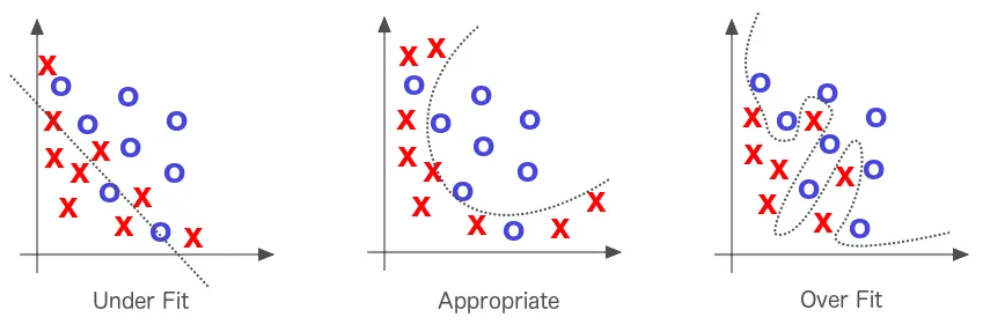
La cross-validation est une technique qui permet de détecter plus facilement l’overfitting et d’ajuster précisément les hyperparamètres pour lutter contre ce problème.
Avantages et intérêts de la validation croisée#
La validation croisée a plusieurs avantages :
On détecte l’overfitting plus facilement et on peut régler les hyperparamètres en conséquence.
Dans un cadre scientifique, évaluer les modèles avec la cross validation permet une évaluation plus fiable et supprime en partie la chance (que l’on pourrait avoir lorsque l’on sépare aléatoirement nos données d’entraînement et de validation).
Si vous pouvez vous le permettre (suffisamment de temps et de ressources de calcul), je vous invite à utiliser la cross validation systématiquement.
Comment fonctionne la validation croisée ?#
La technique de cross-validation peut être décomposée en 3 phases :
On partitionne notre dataset en un nombre de sous-ensembles choisi.
On écarte un des sous-ensembles et on entraîne le modèle sur le reste des sous-ensembles.
On teste finalement le modèle sur le sous-ensemble que l’on avait écarté pour l’entraînement.
On répète les deux derniers points jusqu’à ce que tous les sous-ensembles aient été évalués. Si on sépare notre dataset en 10 sous-ensembles, alors il faudra entraîner le modèle 10 fois. Une fois que tous les entraînements sont terminés, on peut évaluer le modèle en prenant la moyenne de ses performances sur les différents entraînements.
Il existe 3 types de validation croisée qui sont assez proches les uns des autres : le k-fold cross validation, le stratified k-fold cross validation et le leave one out cross validation (LOOCV).
Validation croisée k-fold#
La k-fold cross validation est la version la plus classique. On divise notre dataset en k sous-ensembles. On entraîne k modèles à chaque fois avec un sous-ensemble différent de validation et on fait la moyenne des scores pour évaluer le modèle de manière générale.
Comment choisir le paramètre k : En général, on choisit k de sorte à ce que les sous-ensembles soient suffisamment importants pour représenter statistiquement le dataset original. Le choix de k dépend aussi du temps et des ressources disponibles, car plus k est grand, plus on doit faire d’entraînements.
En général, k=10 est une bonne valeur.
Validation croisée k-fold stratifiée#
Cette méthode est presque identique à la k-fold cross validation de base, mais on ajoute une contrainte. On spécifie que chaque sous-ensemble doit avoir la même distribution de classes. Cela permet de juger chaque sous-ensemble sur un pied d’égalité en termes de performance relative à chaque classe.
Validation croisée leave-one-out#
Encore une fois, cette méthode est très proche de la k-fold cross validation classique, puisqu’il s’agit simplement de cette méthode avec k=n (n étant la taille du dataset). À chaque fois, on entraîne le modèle sur toutes les données sauf une. Cela revient à entraîner le modèle n fois, ce qui peut vite être coûteux en temps et en ressources. L’avantage de cette méthode est qu’on peut entraîner le modèle sur presque toutes les données du dataset. En pratique, cette méthode ne s’utilise pas beaucoup, sauf dans des cas où l’on fait un finetuning sur peu de données (et à ce moment-là, elle est très intéressante).