Introduction à Hugging Face#
Qu’est-ce que c’est ?#
Hugging Face est une entreprise majeure dans la communauté open source en intelligence artificielle. Elle propose un site regroupant des datasets, des modèles et des “spaces”, ainsi que plusieurs bibliothèques (principalement transformers, diffusers et datasets).
Pourquoi utiliser Hugging Face ? Hugging Face offre un accès simplifié à des modèles complexes de pointe. Il permet d’utiliser ces modèles rapidement et efficacement. De plus, il est possible de tester des modèles via la catégorie “spaces” du site et de télécharger des datasets de la communauté. En quelque sorte, c’est le “github” du deep learning.
Que va-t-on apprendre dans ce cours ?#
Ce cours est moins théorique que les précédents, mais il permet d’explorer des modèles très performants et de découvrir les capacités actuelles du deep learning. Il s’inspire des ressources disponibles sur le site de Hugging Face et du cours gratuit sur deeplearning.ai intitulé “Open Source Models with Hugging Face”. Je vous encourage à consulter ce cours, qui présente de nombreuses applications en vision, audio et NLP.
Voici le plan du cours :
Dans cette introduction, nous présentons le site de Hugging Face et ses trois principales catégories : Models, Datasets et Spaces.
Les trois notebooks suivants sont consacrés à l’utilisation de la bibliothèque transformers : le premier aborde les modèles de vision, le second le NLP et le troisième l’audio.
Ensuite, un notebook est dédié à la bibliothèque diffusers, qui permet d’utiliser des modèles de diffusion (comme Stable Diffusion) pour générer des images.
Enfin, le dernier notebook présente Gradio, une bibliothèque permettant de créer rapidement des interfaces pour des démonstrations.
Site de Hugging Face#
Spaces#
La catégorie la plus ludique et la plus accessible est Spaces, qui regroupe des démonstrations de différents modèles.
Voici à quoi ressemble la page d’accueil :
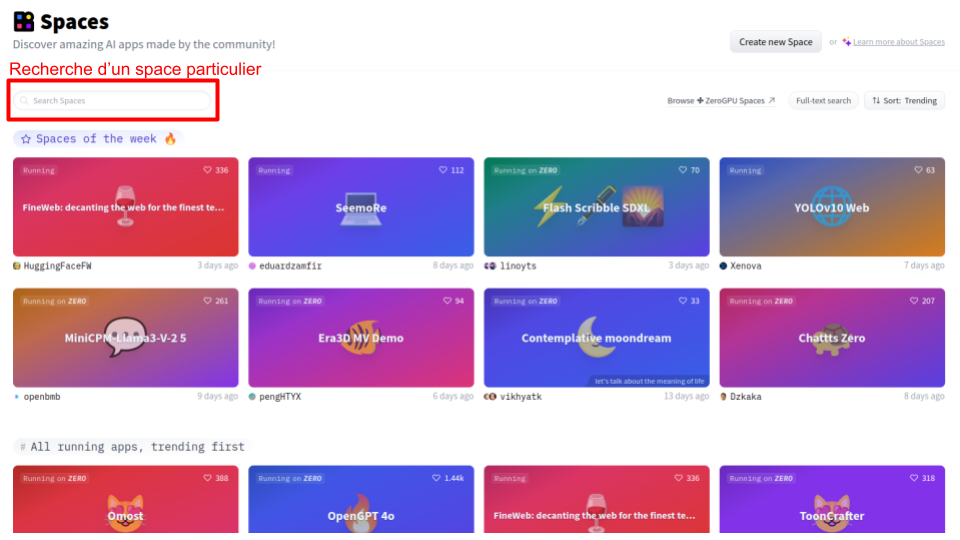
Les démonstrations (spaces) sont classées par utilisation et par popularité, mais vous pouvez utiliser la fonction “Search spaces” pour rechercher un modèle spécifique que vous souhaitez tester. Je vous conseille également de parcourir régulièrement les différents espaces, cela permet de se tenir informé des nouveautés dans le domaine du deep learning.
Si vous entraînez vous-même un modèle, vous pouvez le partager gratuitement dans un espace via l’outil “Create New Space”. Pour cela, il faut maîtriser les bases de la bibliothèque Gradio, que nous aborderons dans le dernier notebook de ce cours.
Models#
Parfois, un modèle que vous souhaitez tester n’est pas disponible dans les espaces ou vous préférez l’utiliser dans votre propre code. Dans ce cas, il faut passer par la catégorie Models du site. La page Models regroupe de nombreux modèles open-source.
Voici à quoi ressemble la page :
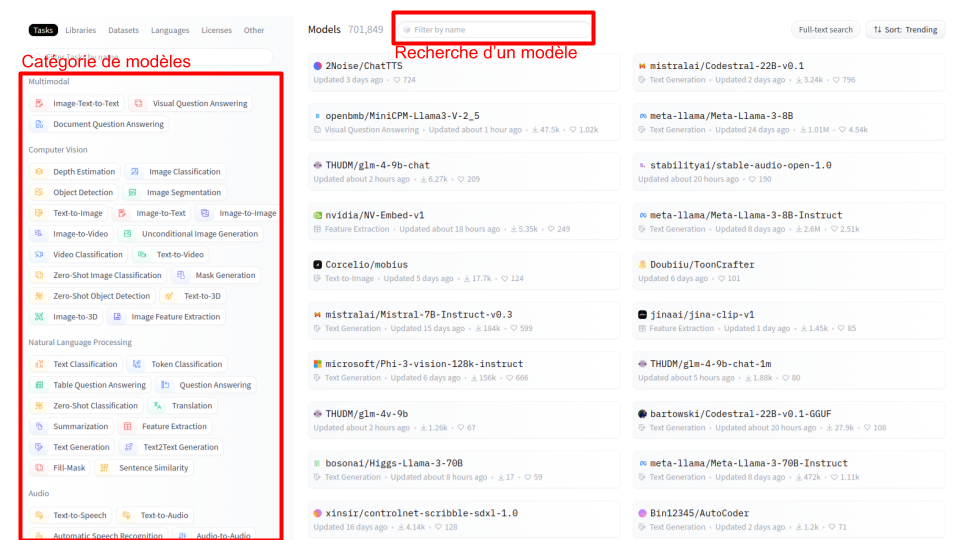
Cette page contient beaucoup d’informations. Vous pouvez rechercher un modèle spécifique par son nom via “Filter by name”. Vous pouvez également utiliser les filtres à gauche pour rechercher des modèles par catégorie.
Par exemple, imaginons que je cherche un modèle de “zero-shot object detection”, qui permet de détecter n’importe quel objet sur une image à partir d’un prompt.
Prompt, qu’est-ce que c’est ? : Un prompt est une entrée qui guide le modèle dans sa tâche. En NLP, un prompt est simplement l’entrée du modèle, c’est-à-dire le texte saisi par l’utilisateur. Un prompt peut également être une coordonnée sur une image (pour une tâche de segmentation) ou même une image ou une vidéo. La plupart du temps, lorsqu’on parle de prompt, il s’agit d’un ajout de texte en entrée du modèle. Dans le cas du “zero-shot object detection”, si je cherche à détecter des bananes sur une image, l’entrée du modèle sera l’image et le texte “banana”.
Pour trouver un modèle qui pourrait me convenir, j’utilise le filtrage de gauche en sélectionnant la catégorie “zero-shot object detection” et je consulte les modèles proposés.
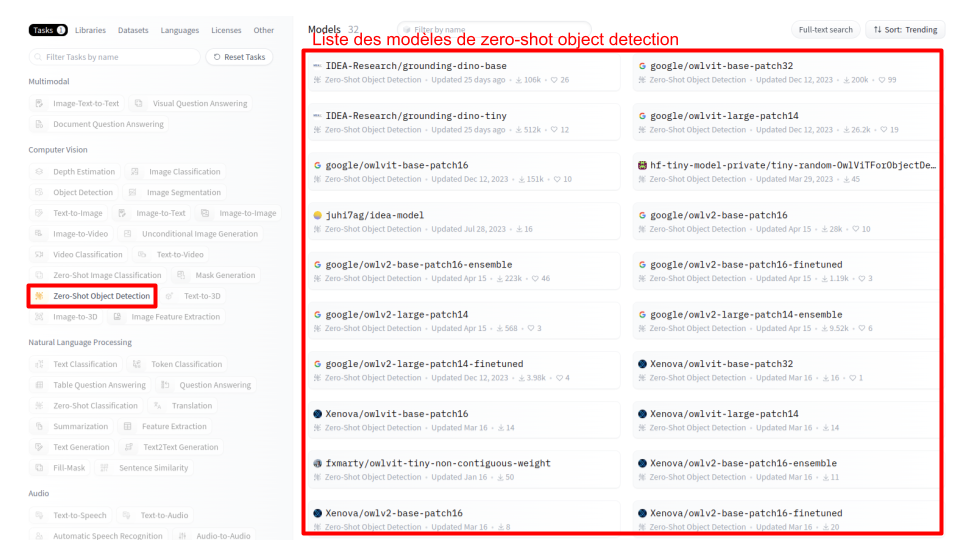
Le modèle “IDEA-Research/grounding-dino-tiny” me semble bien, je le sélectionne et j’arrive sur la page suivante :
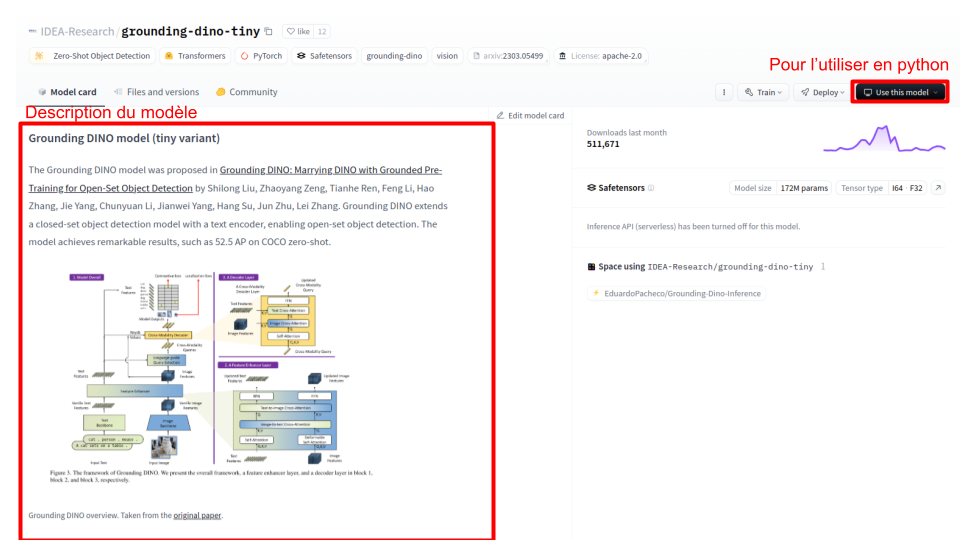
La model card fournit une description précise du modèle (son fonctionnement, ses capacités, etc.). Pour obtenir le code permettant de l’utiliser directement en Python (via la bibliothèque transformers ou diffusers selon le modèle choisi), vous pouvez utiliser le bouton Use this model.
Pour le modèle choisi, voici le code correspondant :
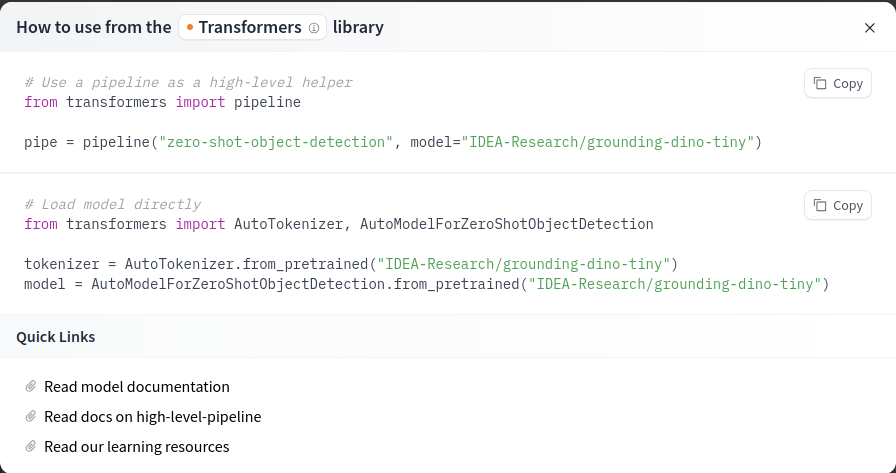
Dans les notebooks suivants, nous verrons comment utiliser ce code pour notre tâche.
Datasets#
Si vous souhaitez entraîner votre propre modèle, il est nécessaire d’avoir un dataset. Vous pouvez choisir de le créer vous-même, mais il existe de nombreux datasets open-source que l’on peut notamment trouver sur Hugging Face.
La page Datasets ressemble à la page Models, avec des fonctions de filtrage et de recherche :
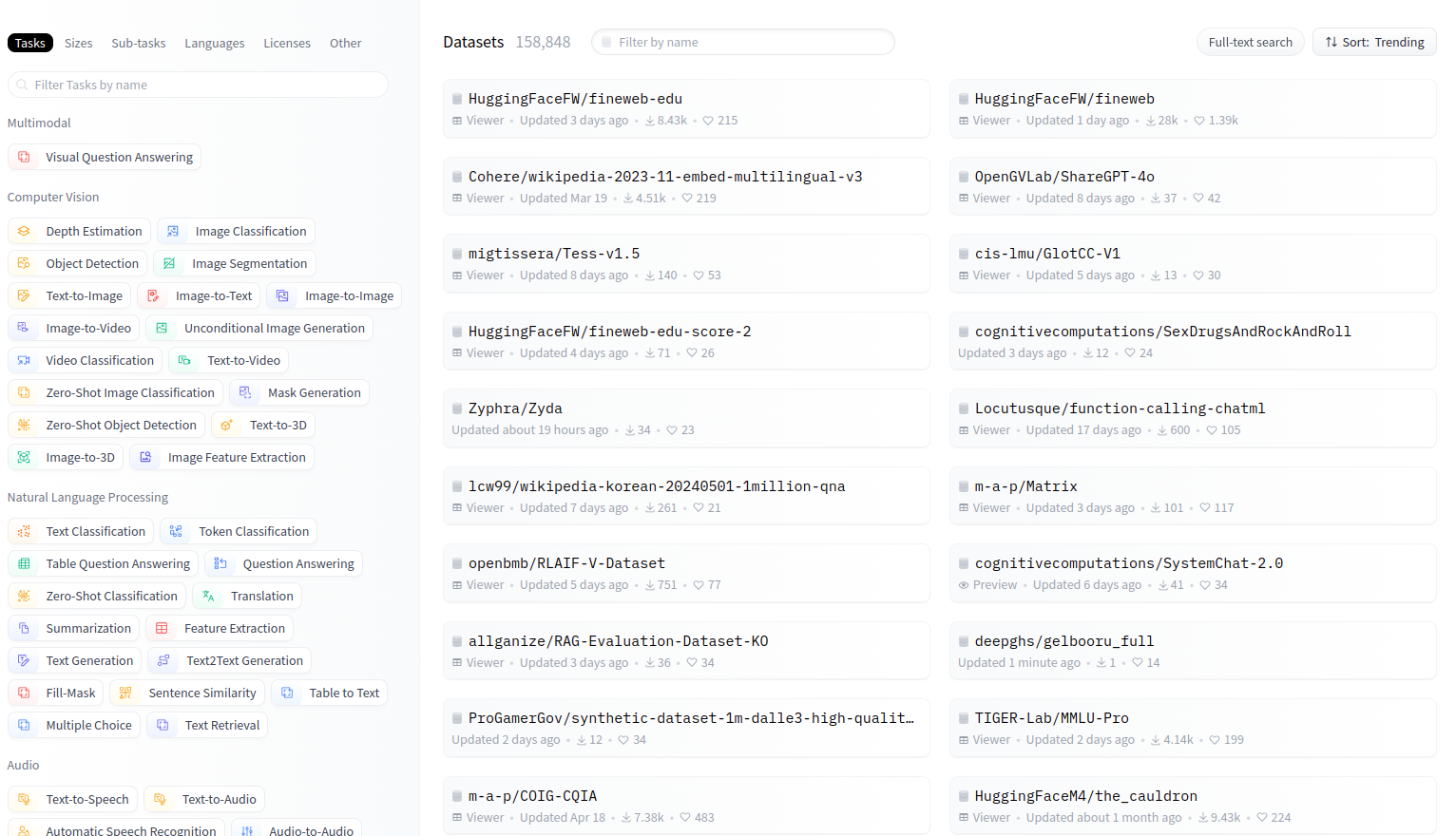
Vous pouvez sélectionner un dataset et arriver sur la page suivante :
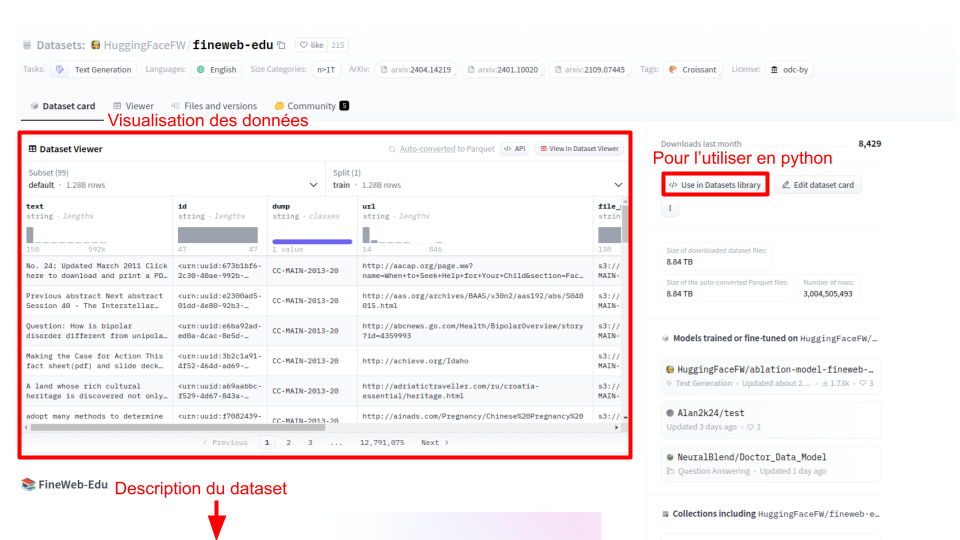
Comme pour les modèles, la Dataset card permet de visualiser les données du dataset et d’avoir une description de celui-ci. Pour l’utiliser directement en Python, vous pouvez utiliser Use in Datasets library pour obtenir le code Python correspondant.
Autres catégories#
Le site est plus complet que cela, mais cette introduction ne vise pas à être exhaustive. Je vous invite à naviguer par vous-même sur le site pour découvrir des choses qui vous intéressent. Dans les notebooks suivants, nous présenterons une vue d’ensemble des types de modèles disponibles et leur utilisation en Python via Hugging Face.