YOLO en détail#
Dans ce notebook, on va explorer en détail le fonctionnement du modèle YOLO.
Détection d’objets#
Histoire de la détection d’objets#
Peu après la publication du célèbre papier qui a popularisé le deep learning, les chercheurs en traitement d’images se sont mis à développer des modèles de deep learning.
Comme expliqué dans le notebook précédent, il existe trois grandes catégories d’algorithmes de traitement d’images : la classification, la détection et la segmentation.
La classification est assez simple à mettre en œuvre avec un modèle de deep learning profond, à condition d’avoir les ressources nécessaires. En revanche, la détection demande plus d’ingéniosité.
En 2014, un groupe de chercheurs a proposé le papier Rich feature hierarchies for accurate object detection and semantic segmentation, plus connu sous le nom de R-CNN. Ce papier, très influent, introduit une architecture en deux étapes pour la détection d’objets et offre des performances remarquables. Le principal problème de cette approche est son temps de traitement trop lent, qui ne permet pas une détection en temps réel. De nombreuses méthodes ont tenté de résoudre ce problème en proposant des architectures différentes, comme fast R-CNN, faster R-CNN et mask R-CNN. Ces méthodes améliorent considérablement le R-CNN de base, mais elles ne suffisent pas pour une détection en temps réel dans la plupart des cas.
En 2015, un article a provoqué un bouleversement majeur dans le domaine de la détection d’objets. Ce papier est You Only Look Once: Unified, Real-Time Object Detection.
You Only Look Once#
Les approches précédentes utilisaient une proposition de régions suivie d’une classification. En d’autres termes, elles exploitaient des classifieurs puissants pour la détection d’objets.
Le papier You Only Look Once (YOLO) propose de prédire les bounding box et les probabilités d’appartenance à une classe directement grâce à un unique réseau de neurones. Cette architecture est beaucoup plus rapide et permet d’atteindre des vitesses de traitement allant jusqu’à 45 images par seconde.
C’est une révolution dans le domaine de la détection d’objets !
Mais alors, comment ça marche ?
YOLO : Comment ça marche ?#
Cette partie décrit l’architecture de YOLO en s’inspirant du blogpost. Je vous invite à le consulter. Les images utilisées sont tirées du blogpost ou du papier original.
Séparation en grille#
Le principe de base de YOLO est de diviser l’image en plus petites parties à l’aide d’une grille de dimension \(S \times S\) comme ceci :

La cellule contenant le centre d’un objet (par exemple un chien ou un vélo) est responsable de sa détection (pour le calcul du loss). Chaque cellule de la grille prédit \(B\) bounding boxes (paramétrable, 2 dans le papier original) et un score de confiance pour chacune. La bounding box prédite contient les valeurs \(x,y,w,h,c\), où \((x,y)\) est la position du centre dans la grille, \((w,h)\) sont les dimensions de la box en pourcentage de l’image entière et \(c\) est la confiance du modèle (probabilité).
Pour calculer la précision de notre bounding box lors de l’entraînement (composante du loss), on utilise l’intersection over union, définie comme :
\(\frac{pred_{box}\cap label_{box}}{pred_{box} \cup label_{box}}\)

En plus de prédire la bounding box et la confiance, chaque cellule prédit aussi la classe de l’objet. Cette classe est représentée par un vecteur one_hot (qui contient uniquement des 0 sauf un 1 dans la bonne classe) dans les annotations. Il est important de noter que chaque cellule peut prédire plusieurs bounding boxes mais une seule classe. C’est une des limitations de l’algorithme : si plusieurs objets sont dans la même cellule, le modèle ne pourra pas les prédire correctement.
Maintenant qu’on a toutes les informations, on peut calculer la dimension de sortie du réseau. On a \(S \times S\) cellules, chaque cellule prédit \(B\) bounding boxes et \(C\) probabilités (avec \(C\) le nombre de classes).
La prédiction du modèle est donc de taille : \(S \times S \times (C + B \times 5)\).
Cela nous amène à la figure suivante :
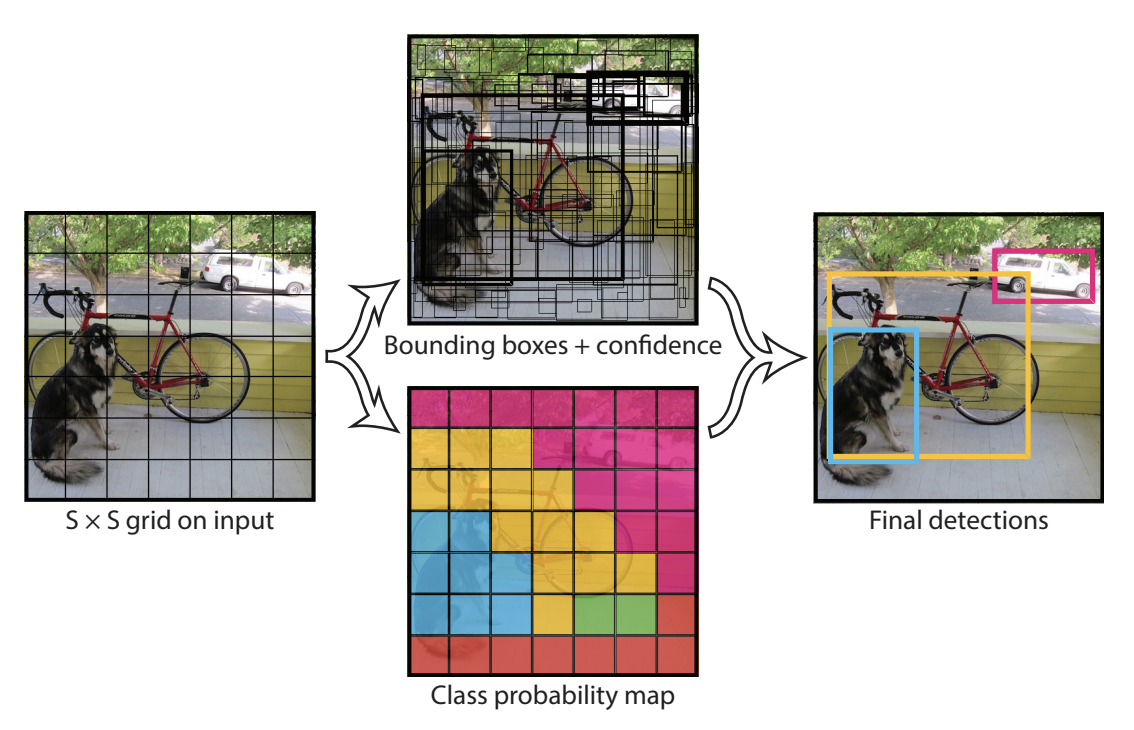
La figure du centre en haut montre les bounding boxes prédites par le modèle (celles avec un trait plus épais ont des scores de confiance élevés). La figure du centre en bas montre la classe prédite dans chaque cellule (en bleu la classe chien, en jaune la classe vélo et en rose la classe voiture).
Architecture du modèle#
L’architecture du modèle YOLO, en termes d’agencement des couches, est aussi particulière. Elle comprend trois composants principaux : head, neck et backbone.
Backbone : C’est la partie la plus importante du réseau, composée d’une série de convolutions pour détecter les features les plus importantes. Cette partie est souvent pré-entraînée sur un dataset de classification.
Neck and Head : Ces couches traitent l’output des couches de convolutions pour produire une prédiction de taille \(S \times S \times (C + B \times 5)\).
Dans le papier original de YOLO, la grille est de taille 7x7, il y a 20 classes (Pascal VOC) et on prédit deux bounding boxes par cellule. Cela donne une prédiction de taille :
\(7 \times 7 \times (20 + 2 \times 5) = 1470\)
Entraînement du modèle#
Les valeurs d’entraînement du modèle (taille d’image, epochs, nombre de couches, batch_size, etc.) sont détaillées dans le papier original et nous n’allons pas entrer dans les détails ici.
En revanche, il est intéressant de s’attarder un peu sur la fonction de loss. L’idée logique de base serait d’utiliser simplement le loss MSE entre nos prédictions et les labels. Cependant, ça ne fonctionne pas tel quel car le modèle donnerait une importance similaire à la qualité de la localisation et à la précision de la prédiction. En pratique, on utilise une pondération sur les loss \(\lambda_{coord}\) et \(\lambda_{noobj}\). Les valeurs du papier original sont définies à 5 pour \(\lambda_{coord}\) et 0.5 pour \(\lambda_{noobj}\). À noter que \(\lambda_{noobj}\) est utilisé uniquement sur les cellules où il n’y a pas d’objets pour éviter que son score de confiance, proche de 0, n’impacte trop les cellules contenant des objets.
Limitations de YOLO#
Nous avons déjà évoqué sa principale limitation : ne prédire qu’un nombre limité de bounding boxes par cellule et ne pas permettre la détection d’objets de différentes catégories dans la même cellule. Cela pose problème lorsque l’on veut détecter des personnes dans une foule, par exemple.
Amélioration de YOLO#
Nous avons vu que YOLO est un modèle très performant et rapide pour la détection d’objets dans les images. C’est pourquoi, de nombreux chercheurs ont cherché à l’améliorer en proposant diverses optimisations. Aujourd’hui encore, de nouvelles versions de YOLO sortent régulièrement.
Cette partie présente chronologiquement les différentes versions de YOLO.
YOLOv2 (2017) - aussi connu sous le nom de YOLO9000#
Papier : YOLO9000: Better, Faster, Stronger
Innovations :
Introduction de l’idée d’ancres (anchors) pour améliorer la précision des prédictions de boîte.
Passage de la résolution d’entrée de 224x224 à 416x416 pour améliorer la détection d’objets de petite taille.
YOLOv3 (2018)#
Papier : YOLOv3: An Incremental Improvement
Innovations :
Utilisation d’un modèle plus profond avec une architecture Darknet-53, un réseau de neurones convolutifs résiduel.
Détection multi-échelle, avec des prédictions faites à trois niveaux de granularité différents (feature maps de différentes tailles).
YOLOv4 (2020)#
Papier : YOLOv4: Optimal Speed and Accuracy of Object Detection
Innovations :
Utilisation du backbone CSPDarknet53 pour une meilleure performance.
Améliorations des têtes de détection avec PANet (Path Aggregation Network) pour améliorer les flux d’informations.
Introduction du concept de Mosaic Data Augmentation pour enrichir la diversité des données d’entraînement.
Ajout de diverses techniques modernes comme DropBlock, Mish activation, et SPP (Spatial Pyramid Pooling).
YOLOv5 (2020)#
Développé par Ultralytics
Innovations :
Pas de papier officiel, mais des améliorations pratiques dans l’implémentation et la performance.
Modèle plus léger et plus facile à entraîner avec une meilleure gestion des dépendances.
YOLOv6 (2022)#
Innovations :
Nouveau backbone YOLOv6S, optimisé pour les performances en temps réel.
Techniques avancées de réduction de la latence.
Améliorations dans les méthodes d’augmentation des données et l’optimisation des hyperparamètres.
YOLOv7 (2022)#
Papier : YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
Innovations :
Intégration de bag of freebies pour améliorer la précision sans augmenter le temps d’inférence.
Architecture optimisée pour un compromis optimal entre vitesse et précision.
Ajout de diverses techniques de régularisation pour améliorer la performance générale.
YOLOv8 (2023)#
Développé par Ultralytics
Innovations :
Encore plus optimisé pour les performances en temps réel et l’intégration mobile.
Architecture flexible permettant des ajustements pour divers cas d’utilisation, y compris la détection, la segmentation et la classification.
YOLO-World (2024)#
Papier : YOLO-World: Real-Time Open-Vocabulary Object Detection
Innovations :
Utilisation d’un transformer encoder pour le texte permettant la détection open-vocabulary.