La distillation des connaissances#
Le concept de distillation des connaissances a été introduit dans l’article Distilling the Knowledge in a Neural Network en 2015. L’idée est d’utiliser un modèle appelé teacher (un modèle profond déjà entraîné) pour transférer ses connaissances à un modèle plus petit appelé student.
Fonctionnement#
En pratique, le modèle student est entraîné sur deux objectifs :
Minimiser la distance entre sa prédiction et celle du teacher pour le même élément.
Minimiser la distance entre sa prédiction et le label de l’entrée.
Ces deux loss sont combinés avec un facteur de pondération \(\alpha\) que l’on peut choisir. Ainsi, le modèle student utilise à la fois le label de l’image et la prédiction du teacher (une distribution de probabilité).
Note : En pratique, pour la première partie du loss, on compare les logits avant l’application de la fonction softmax plutôt que les probabilités. Pour plus de clarté, on utilisera le terme “prédictions” au lieu de “logits”.

Pourquoi ça marche ?#
On peut se demander pourquoi cette méthode fonctionne mieux qu’un entraînement direct du student avec un loss classique prédiction/label. Plusieurs raisons expliquent cela :
Transfert des connaissances implicites : Utiliser les prédictions du teacher permet au student d’apprendre des connaissances implicites sur les données. La prédiction du teacher est une distribution de probabilités qui indique la similarité entre plusieurs classes, par exemple.
Conservation des relations complexes : Le teacher est très complexe et peut capturer des structures complexes dans les données, ce qui n’est pas forcément le cas pour un modèle plus petit entraîné de zéro. La distillation permet au student d’apprendre ces relations complexes plus simplement, tout en améliorant la vitesse et en réduisant l’utilisation mémoire (car c’est un modèle plus petit).
Stabilisation de l’entraînement : En pratique, l’entraînement est plus stable pour le student avec cette méthode de distillation.
Atténuation des problèmes d’annotations : Le teacher a appris à généraliser et peut prédire correctement, même s’il a été entraîné sur des images avec des labels incorrects. Dans le cadre de la distillation, la différence importante entre la sortie du teacher et le label donne une information supplémentaire au student sur la qualité de la donnée.
Applications pratiques#
En pratique, il est possible de transférer les connaissances d’un modèle performant à un modèle plus petit sans perte significative de qualité de prédiction. Cela est très utile pour réduire la taille des modèles, par exemple pour des applications embarquées ou des traitements sur CPU. Il est également possible de distiller plusieurs teachers dans un seul student. Dans certains cas, le student peut même surpasser chaque teacher individuellement.
C’est une technique utile à connaître pour de nombreuses situations.
Autres applications#
Depuis son invention, la distillation des connaissances a été adaptée à la résolution de divers problèmes. Nous en présentons deux ici : l’amélioration de la classification avec NoisyStudent et la détection d’anomalies non supervisée avec STPM.
Noisy Student : améliorer la classification#
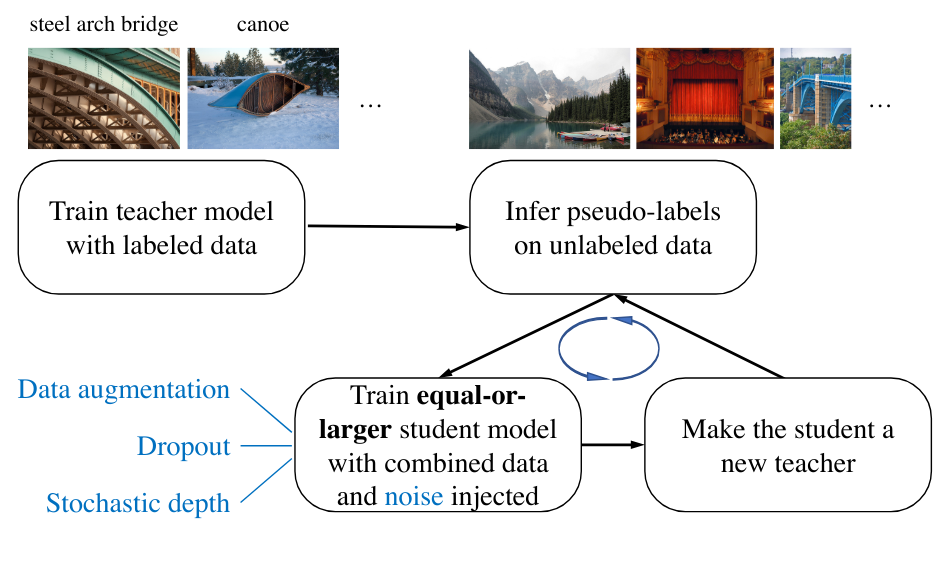
Pendant longtemps, la course à la performance sur le dataset ImageNet a été au cœur de la recherche en deep learning. L’objectif était d’améliorer constamment les performances sur ce dataset. En 2020, l’article Self-training with Noisy Student improves ImageNet classification propose d’utiliser la distillation pour entraîner un modèle student plus performant que le teacher à chaque itération.
Un modèle student est entraîné à partir de pseudo-labels générés par un modèle teacher (labels créés par le teacher sur des images non annotées). Lors de l’entraînement, du bruit est ajouté pour augmenter sa robustesse. Une fois le student entraîné, on l’utilise pour obtenir de nouveaux pseudo-labels et entraîner un autre student. On répète le processus plusieurs fois et on finit par obtenir un modèle bien plus performant que le teacher de base.
STPM : détection d’anomalies non supervisée#
Un exemple intéressant d’application de la distillation des connaissances est la détection d’anomalies non supervisée. L’article Student-Teacher Feature Pyramid Matching for Anomaly Detection adapte cette technique pour ce cas d’usage.
Dans ce cas, le modèle teacher et le modèle student ont la même architecture. Au lieu de se concentrer sur les prédictions, on s’intéresse aux feature maps des couches intermédiaires du réseau. Lors de l’entraînement, on dispose de données sans anomalies. Le modèle teacher est pré-entraîné sur ImageNet (par exemple) et est figé pendant l’entraînement. Le modèle student est initialisé aléatoirement et c’est lui qu’on entraîne. Plus précisément, on l’entraîne à reproduire les feature maps du teacher sur des données sans défauts. À la fin de l’entraînement, le student et le teacher auront des feature maps identiques sur un élément sans défaut.
Lors de la phase de test, on évalue le modèle sur des données sans défaut et des données avec défauts. Sur les données sans défaut, le student imite parfaitement le teacher, tandis que sur des données défectueuses, les feature maps du student et du teacher diffèrent. Cela permet de calculer un score de similarité, qui sert de score d’anomalie.

En pratique, cette méthode fait partie des plus performantes pour la détection d’anomalies non supervisée. C’est cette méthode que nous allons implémenter dans le notebook suivant.