Introduction à la détection d’objets dans les images#
Le traitement d’images se divise en trois grandes catégories :
La classification : Détermine si un objet est présent sur l’image (exemple : une photo de chien ?).
La détection : Localise la position d’un objet sur l’image (exemple : où se trouve le chien ?).
La segmentation : Identifie les pixels appartenant à un objet (exemple : quels sont les pixels du chien ?).

Image extraite de ce site.
Dans le cours sur les CNN, nous avons abordé des problèmes de classification avec une architecture CNN classique terminée par une couche Fully Connected, ainsi que des problèmes de segmentation avec le modèle U-Net.
La détection d’objets est plus complexe à expliquer, donc ce cours se concentre sur les méthodes existantes et une description détaillée du modèle YOLO.
Nous allons d’abord expliquer les différences entre les deux principales catégories de détecteurs :
Méthodes en deux étapes (Two-Stage Detectors) : Elles regroupent la famille des RCNN (Region-based Convolutional Neural Networks).
Méthodes en une étape (Single-Stage Detectors) : Elles regroupent la famille des YOLO (You Only Look Once).
Two-Stage Detectors#
Comme son nom l’indique, le two-stage detector suit deux étapes pour détecter des objets :
Première étape : Proposition de régions (region proposal) où des objets d’intérêt pourraient se trouver.
Deuxième étape : Affinage de la détection, c’est-à-dire l’association de la classe de l’objet et la précision de la bounding box (si un objet est présent).
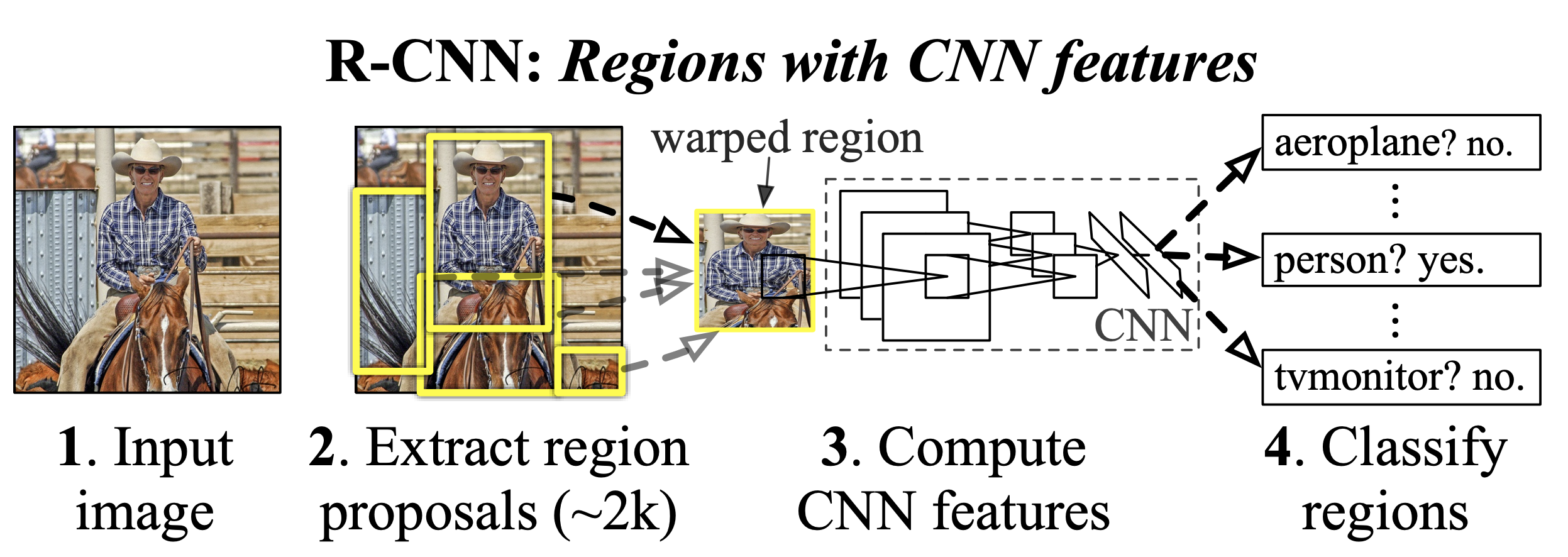
Image extraite de l’article.
En général, les two-stage detectors sont très précis et permettent des détections complexes, mais ils sont assez lents et ne permettent pas un traitement en temps réel.
Les réseaux two-stage les plus connus sont la famille des RCNN. Pour en savoir plus, consultez ce blogpost.
One-Stage Detectors#
Le one-stage detector ne nécessite qu’une seule étape pour générer les bounding box avec les labels correspondants. Le réseau divise l’image en une grille et prédit plusieurs bounding box et leurs probabilités pour chaque cellule de la grille.
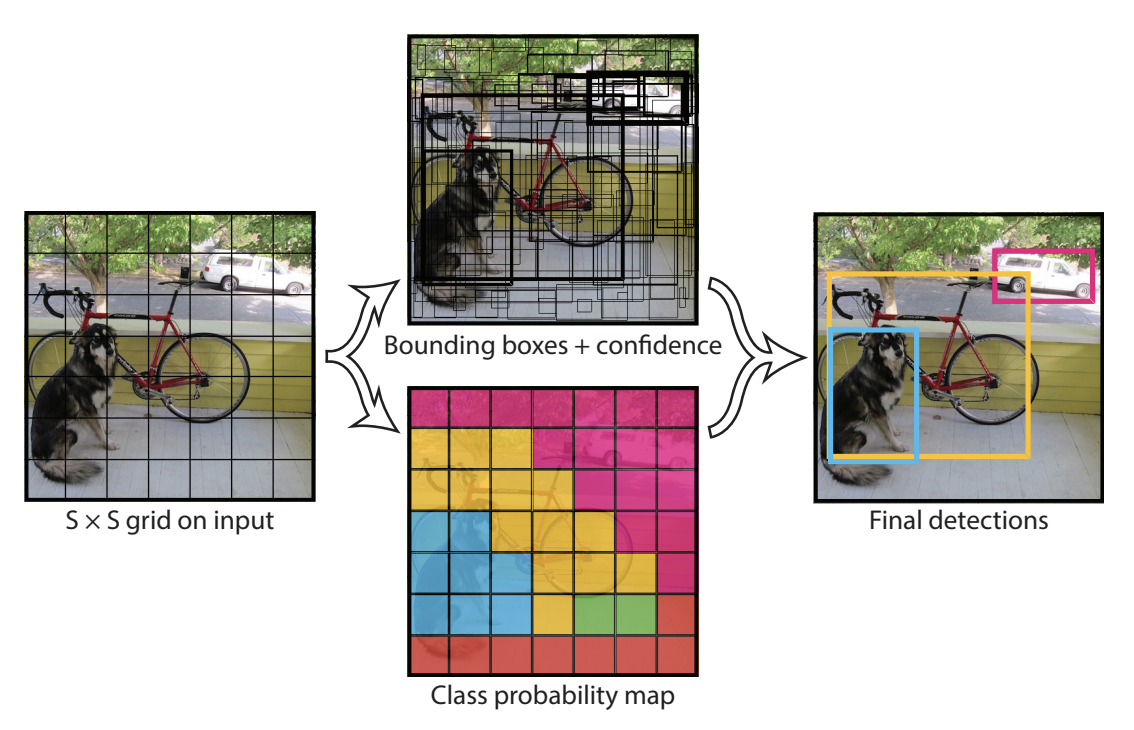
Figure extraite de l’article.
Les one-stage detectors sont généralement moins précis que les two-stage detectors, mais ils sont beaucoup plus rapides et permettent un traitement en temps réel. C’est la famille de détecteurs la plus utilisée aujourd’hui.
Non-Maximum Suppression et Ancres#
NMS (Non-Maximum Suppression)#
Lors de la détection d’objets avec notre modèle, l’architecture ne permet pas d’éviter que plusieurs bounding box se chevauchent sur le même objet. Avant de transmettre les détections à l’utilisateur, on souhaite avoir une seule détection par objet, la plus pertinente possible.
C’est là qu’intervient la non-maximum suppression. L’algorithme ne sera pas détaillé dans ce cours, mais vous pouvez consulter les ressources suivantes pour plus de détails : blogpost et site.

Ancres (Anchor boxes)#
Les ancres sont des bounding boxes prédéfinies placées sur une grille régulière couvrant l’image. Elles peuvent avoir différents ratios (longueur/hauteur) et des tailles variables pour couvrir un maximum de tailles d’objets possibles. Les ancres réduisent le nombre de positions à étudier pour le modèle. Avec les ancres, le modèle prédit le décalage par rapport à l’ancre pré-générée et la probabilité d’appartenance à un objet.
Cette méthode améliore la qualité des détections. Pour en savoir plus, consultez le blogpost.
En pratique, il y a souvent beaucoup d’ancres. La figure suivante montre 1% des ancres du modèle retinaNet :

Bonus : Détection d’objets avec l’architecture transformer#
Récemment, l’architecture du transformer a été adaptée pour la détection d’objets. Le modèle DETR utilise un modèle CNN pour extraire des caractéristiques visuelles. Ces features sont ensuite passées à travers un transformer encoder (avec un positional embedding) pour déterminer les relations spatiales entre les caractéristiques grâce au mécanisme d’attention. Un transformer decoder (différent de celui utilisé en NLP) prend en entrée la sortie de l’encoder (keys et values) et des embeddings de labels d’objets (queries), convertissant ces embeddings en prédictions. Enfin, une couche linéaire finale traite la sortie du décodeur pour prédire les labels et les bounding boxes.
Pour en savoir plus, consultez l’article ou ce blogpost.
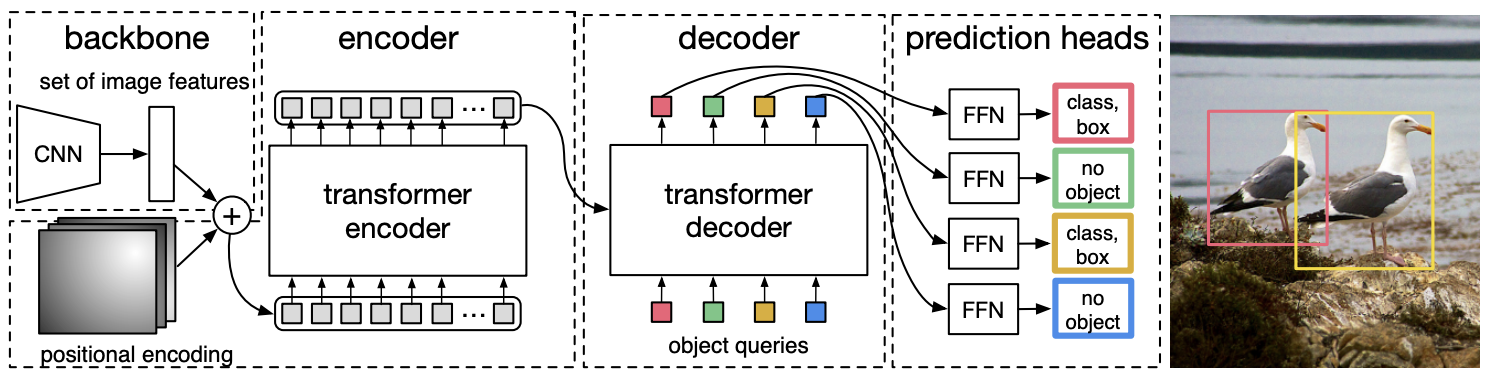
Cette méthode offre plusieurs avantages :
Pas besoin de NMS, d’ancres ou de region proposal, ce qui simplifie l’architecture et le pipeline d’entraînement.
Le modèle a une meilleure compréhension globale de la scène grâce au mécanisme d’attention.
Cependant, elle présente aussi quelques inconvénients :
Les transformers sont gourmands en calcul, donc ce modèle est moins rapide qu’un one-stage detector comme YOLO.
L’apprentissage est souvent plus long que pour un détecteur basé uniquement sur un CNN.
Note : Les transformers utilisés en vision ont souvent des temps d’entraînement plus longs que ceux des CNN. Une explication possible est que les CNN ont un biais qui les rend particulièrement adaptés aux images, nécessitant un temps d’entraînement plus court. Les transformers, étant des modèles généralistes sans biais, doivent apprendre depuis zéro.