Long Short-Term Memory#
Dans le notebook précédent, on a présenté la couche classique d’un RNN. Depuis son invention, plein d’autres couches récurrentes ont été créées.
Ici, on va voir la couche LSTM (long short-term memory), une alternative à la couche RNN classique.
Qu’est-ce qu’une couche LSTM ?#
La couche LSTM est composée d’une memory unit avec 4 couches fully connected. Trois de ces couches servent à sélectionner les infos pertinentes des étapes précédentes : la forget gate, l’input gate et l’output gate.
forget gate : Supprime des infos de la mémoire
input gate : Insère des infos dans la mémoire
output gate : Utilise les infos stockées
La dernière couche fully connected génère une “information candidate” pour la mémoire de la couche LSTM.
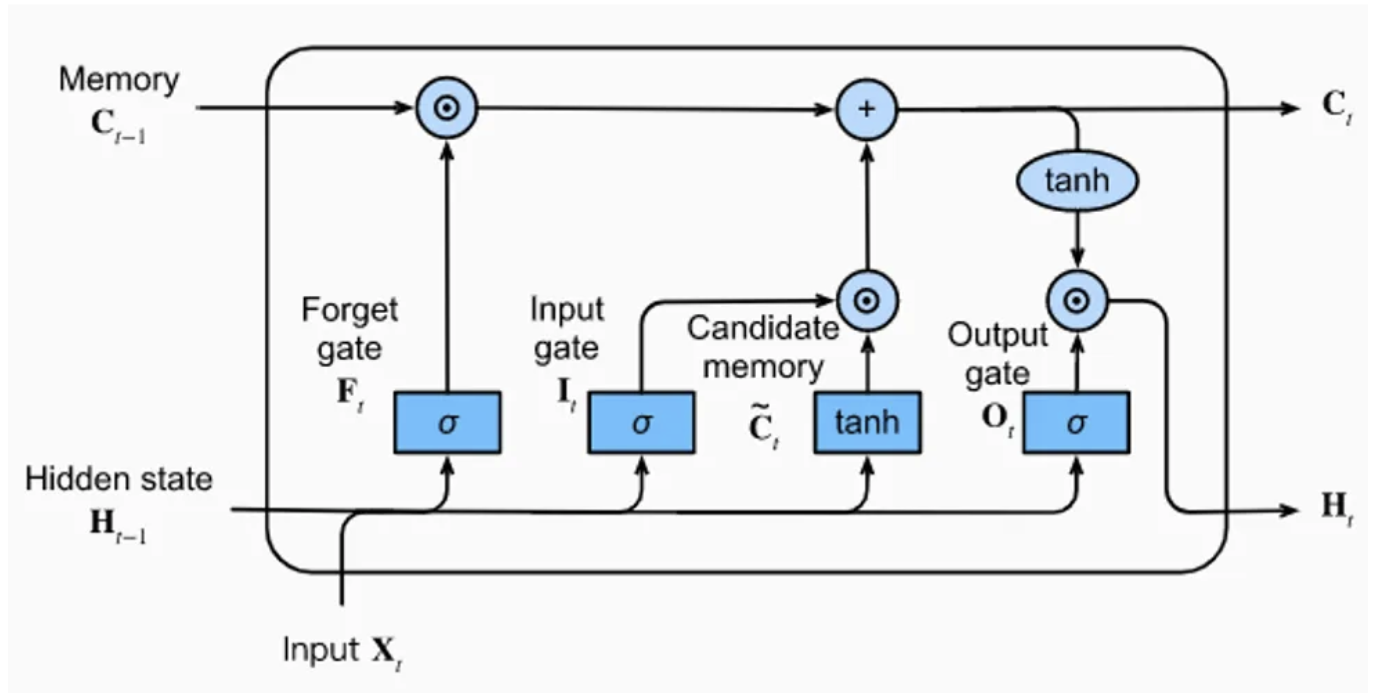
Figure tirée du blogpost.
Comme on voit sur la figure, la couche LSTM reçoit 3 vecteurs en entrée : \(H_{t-1}\), \(C_{t-1}\) et \(X_{t}\). Les deux premiers viennent directement du LSTM, et le troisième correspond à l’entrée au temps \(t\) (le caractère dans notre cas).
Pour simplifier : \(H_{t-1}\) contient la mémoire à court terme, et \(C_{t-1}\) la mémoire à long terme. Ça permet de garder les infos importantes sur un contexte large sans négliger le contexte local.
L’idée, c’est de résoudre le problème de propagation de l’info sur de longues séquences qu’on a dans les RNN classiques.
Pour creuser, vous pouvez lire l’article ou consulter le blogpost.
Implémentation PyTorch#
import torch
import torch.nn as nn
Dataset#
Pour créer le dataset, on utilise encore le fichier moliere.txt et on reprend le code du notebook précédent.
with open('moliere.txt', 'r', encoding='utf-8') as f:
text = f.read()
print("Nombre de caractères dans le dataset : ", len(text))
Nombre de caractères dans le dataset : 1687290
On réduit le nombre d’éléments pour un entraînement rapide (à décommenter si vous voulez tout entraîner).
text=text[:100000]
print("Nombre de caractères dans le dataset : ", len(text))
Nombre de caractères dans le dataset : 100000
chars = sorted(list(set(text)))
vocab_size = len(chars)
print(''.join(chars))
print("Nombre de caractères différents : ", vocab_size)
!'(),-.:;?ABCDEFGHIJLMNOPQRSTUVYabcdefghijlmnopqrstuvxyz«»ÇÈÉÊàâæçèéêîïôùû
Nombre de caractères différents : 76
stoi = { ch:i for i,ch in enumerate(chars) }
itos = { i:ch for i,ch in enumerate(chars) }
encode = lambda s: [stoi[c] for c in s] # encode : prend un string et output une liste d'entiers
decode = lambda l: ''.join([itos[i] for i in l]) # decode: prend une liste d'entiers et output un string
data = torch.tensor(encode(text), dtype=torch.long)
Séparation en train et test.
n = int(0.9*len(data)) # 90% pour le train et 10% pour le test
train_data = data[:n]
test = data[n:]
Création du modèle#
Pour créer le modèle, on utilise directement l’implémentation PyTorch de la couche LSTM. Contrairement aux couches linéaires ou convolutives, nn.LSTM permet de stacker plusieurs couches avec le paramètre num_layers. Si on veut les définir une par une, il faut utiliser nn.LSTMCell.
class lstm(nn.Module):
def __init__(self, vocab_size, hidden_size,num_layers=1):
super(lstm, self).__init__()
self.hidden_size = hidden_size
# On utilise un embedding pour transformer les entiers(caractères) en vecteurs
self.embedding = nn.Embedding(vocab_size, hidden_size)
# La couche LSTM peut prendre l'argument num_layers pour empiler plusieurs couches LSTM
self.lstm = nn.LSTM(hidden_size, hidden_size, num_layers=num_layers)
# Une dernière couche linéaire pour prédire le prochain caractère
self.fc = nn.Linear(hidden_size, vocab_size)
def forward(self, x, hidden):
x = self.embedding(x)
x, hidden = self.lstm(x, hidden)
x = self.fc(x)
return x, (hidden[0].detach(), hidden[1].detach())
def init_hidden(self, batch_size):
return (torch.zeros(1, batch_size, self.hidden_size), torch.zeros(1, batch_size, self.hidden_size))
Entraînement#
epochs = 20
lr=0.001
hidden_dim=128
seq_len=100
num_layers=1
model=lstm(vocab_size,hidden_dim,num_layers)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
La couche LSTM prend en entrée une séquence et renvoie une séquence de la même taille. Ça accélère l’entraînement car on peut traiter plusieurs exemples en même temps.
Note : On peut aussi accélérer l’entraînement en faisant un traitement en batch avec plusieurs séquences en parallèle.
for epoch in range(epochs):
state=None
running_loss = 0
n=0
data_ptr = torch.randint(100,(1,1)).item()
# On train sur des séquences de seq_len caractères et on break si on dépasse la taille du dataset
while True:
x = train_data[data_ptr : data_ptr+seq_len]
y = train_data[data_ptr+1 : data_ptr+seq_len+1]
optimizer.zero_grad()
y_pred,state = model.forward(x,state)
loss = criterion(y_pred, y)
running_loss += loss.item()
n+=1
loss.backward()
optimizer.step()
data_ptr+=seq_len
# Pour éviter de sortir de l'index du dataset
if data_ptr + seq_len + 1 > len(train_data):
break
print("Epoch: {0} \t Loss: {1:.8f}".format(epoch, running_loss/n))
Epoch: 0 Loss: 2.17804336
Epoch: 1 Loss: 1.76270216
Epoch: 2 Loss: 1.62740668
Epoch: 3 Loss: 1.54147145
Epoch: 4 Loss: 1.47995140
Epoch: 5 Loss: 1.43100239
Epoch: 6 Loss: 1.39074463
Epoch: 7 Loss: 1.35526441
Epoch: 8 Loss: 1.32519794
Epoch: 9 Loss: 1.29712536
Epoch: 10 Loss: 1.27268774
Epoch: 11 Loss: 1.24876227
Epoch: 12 Loss: 1.22720749
Epoch: 13 Loss: 1.20663312
Epoch: 14 Loss: 1.18768359
Epoch: 15 Loss: 1.16936996
Epoch: 16 Loss: 1.15179397
Epoch: 17 Loss: 1.13514291
Epoch: 18 Loss: 1.11997525
Epoch: 19 Loss: 1.10359089
On peut maintenant évaluer le loss sur les données de test.
state=None
running_loss = 0
n=0
data_ptr = torch.randint(100,(1,1)).item()
while True:
with torch.no_grad():
x = test[data_ptr : data_ptr+seq_len]
y = test[data_ptr+1 : data_ptr+seq_len+1]
y_pred,state = model.forward(x,state)
loss = criterion(y_pred, y)
running_loss += loss.item()
n+=1
data_ptr+=seq_len
if data_ptr + seq_len + 1 > len(test):
break
print("Loss de test: {0:.8f}".format(running_loss/n))
Loss de test: 1.51168611
Le modèle overfit pas mal… Essayez de corriger ça par vous-même.
Génération#
On va maintenant pouvoir tester la génération de texte !
import torch.nn.functional as F
moliere='.'
sequence_length=250
state=None
for i in range(sequence_length):
x = torch.tensor(encode(moliere[-1]), dtype=torch.long).squeeze()
y_pred,state = model.forward(x.unsqueeze(0),state)
probs=F.softmax(torch.squeeze(y_pred), dim=0)
sample=torch.multinomial(probs, 1)
moliere+=itos[sample.item()]
print(moliere)
.
Çà coeuse, et bon enfin l'avoir faire.
MASCARILLE.
En me donner d vous, Le pas.
MASCARILLE, à dans un pour sûte matinix! cette ma foi.
PANDOLFE.
Ma foi, tu te le sy sois touves d'arrête sa bien sans les bonheur.
MASCARILLE.
Moi, je me suis to
La génération est un peu mieux que pour le modèle RNN de base, mais pas encore convaincante. Vous pouvez essayer d’améliorer les performances en modifiant les paramètres (nombre de couches en série, hidden dim, etc.).