Réseaux convolutifs#
Intuition#
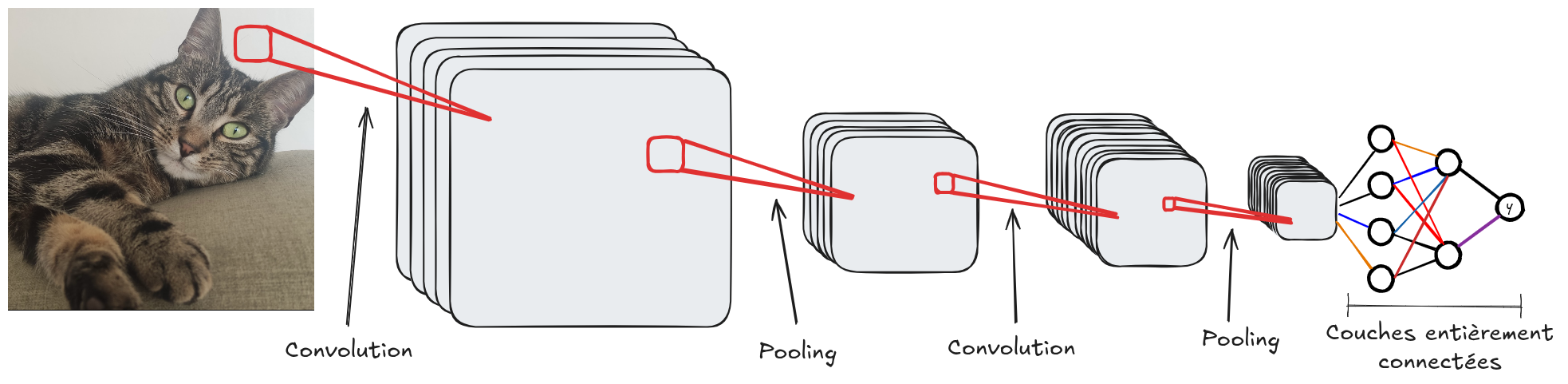
Comme les réseaux fully connected, les réseaux convolutifs sont composés de plusieurs couches. L’idée est d’augmenter le nombre de filtres (canaux) en profondeur tout en réduisant la résolution spatiale des FeatureMaps. Cela permet d’augmenter l’abstraction : les premières couches détectent surtout les contours, tandis que les couches profondes captent des informations plus contextuelles.
Pour un problème de classification (comme MNIST), les dernières couches sont souvent des couches entièrement connectées pour adapter la sortie des convolutions au nombre de classes.
Un réseau convolutif est généralement composé de couches de convolution, d’activation (ReLU, sigmoid, tanH, etc.) et de pooling. La couche de convolution ajuste le nombre de filtres et ajoute des paramètres entraînables. La couche d’activation rend le réseau non linéaire, et la couche de pooling réduit la résolution spatiale de l’image.
Voici l’architecture classique d’un réseau convolutif :
Champ réceptif#
Comme vu précédemment, une seule couche de convolution permet seulement une interaction locale entre les pixels (avec un filtre de \(3 \times 3\), chaque pixel n’est influencé que par ses voisins). Cela pose problème pour détecter des éléments couvrant toute l’image.
Cependant, empiler plusieurs couches de convolution augmente la zone d’influence d’un pixel.
L’image suivante illustre ce principe :
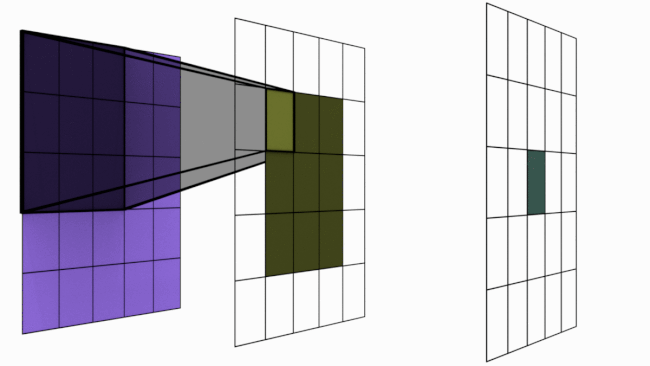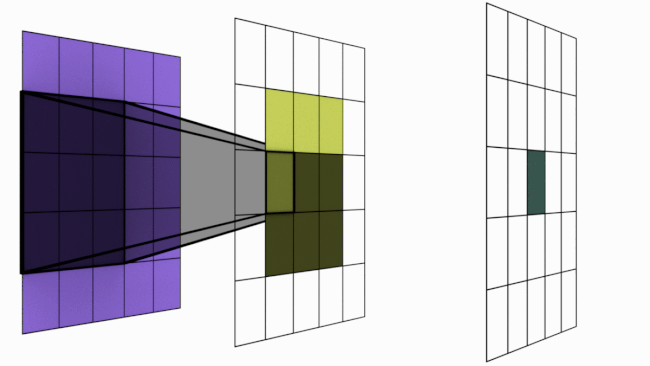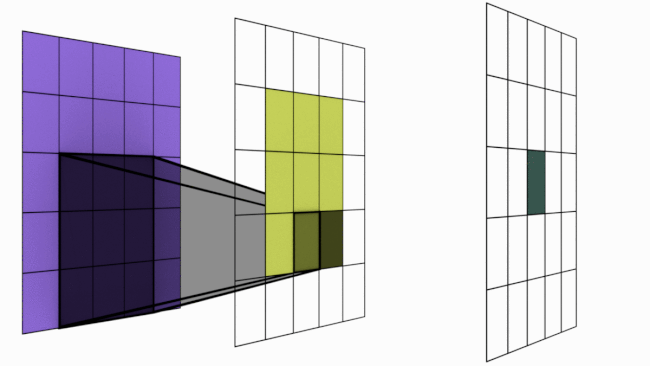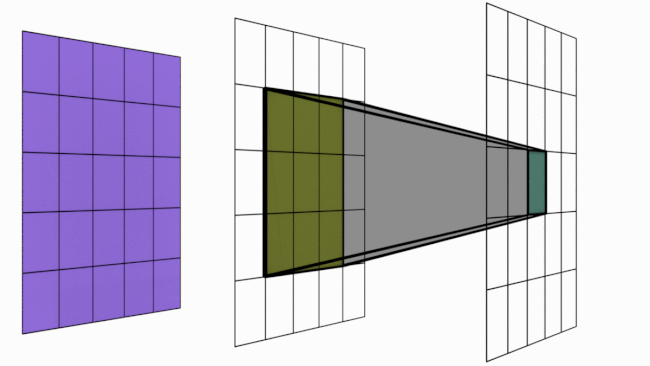
Figure extraite de blogpost.
Plus formellement, le champ réceptif d’un pixel se calcule avec la formule :
\(R_{Eff}=R_{Init} + (k-1)*S\)
Où \(R_{Eff}\) est le champ réceptif de la couche de sortie, \(R_{Init}\) le champ initial, \(k\) la taille du noyau et \(S\) le stride.
Lors de l’implémentation de réseaux convolutifs, il faut vérifier ce paramètre pour s’assurer que le réseau analyse bien toutes les interactions entre pixels. Plus l’image d’entrée est grande, plus le champ réceptif doit être large.
Précision : Les outils vus précédemment pour améliorer les modèles (comme BatchNorm et Dropout) s’appliquent aussi aux réseaux convolutifs.
Visualisation de ce que le réseau apprend#
Pour comprendre le fonctionnement d’un réseau convolutif et le rôle de chaque couche, on peut visualiser les activations des FeatureMaps en fonction de la profondeur.
Voici une visualisation selon la profondeur du réseau :
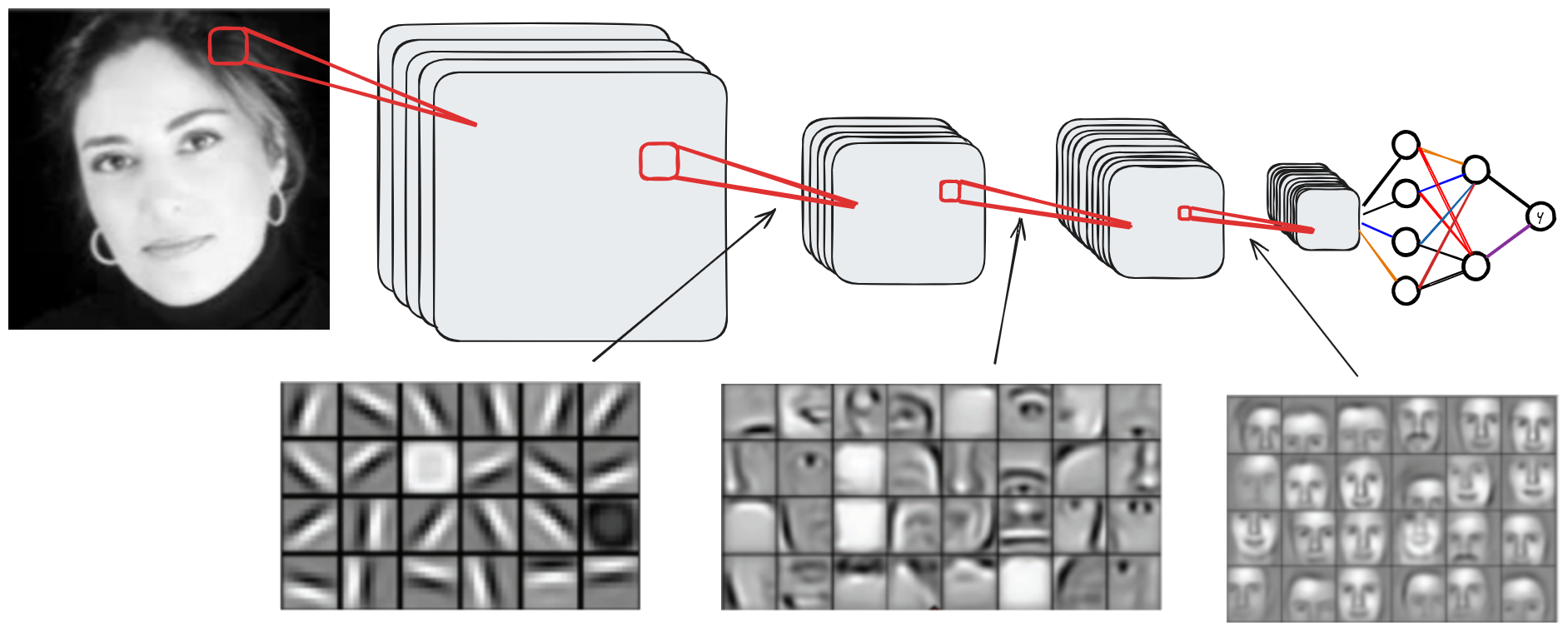
Comme on le voit, les couches peu profondes captent surtout les informations locales (contours, formes basiques), tandis que les couches profondes contiennent des informations contextuelles. Les couches intermédiaires contiennent des informations couvrant une partie importante de l’image.