Fine-Tuning des LLM#
Dans ce cours, nous allons étudier en détail l’article BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, déjà mentionné dans le cours 7 sur les transformers.
La plupart des LLM (comme GPT et BERT) sont pré-entraînés sur des tâches de prédiction de mots (prédiction du prochain mot ou prédiction de mots masqués). Ensuite, ils sont finetunés sur des tâches plus spécifiques. Sans finetuning, ces modèles ne sont généralement pas très utiles.
Note : Le finetuning d’un LLM implique de réentraîner tous ses paramètres. En revanche, pour les modèles de vision comme les CNN, on réentraîne souvent seulement une partie des couches (parfois uniquement la dernière).
Différences entre BERT et GPT#
Dans le cours sur les transformers, nous avons présenté GPT et l’avons implémenté. GPT est unidirectionnel : pour prédire un token, il n’utilise que les tokens précédents. Cependant, cette approche n’est pas optimale pour de nombreuses tâches, car on a souvent besoin du contexte complet de la phrase.
BERT propose une alternative avec un transformer bidirectionnel, qui utilise le contexte des deux côtés pour la prédiction. Son architecture permet un finetuning sur deux types de tâches :
Prédiction au niveau de la phrase (sentence-level prediction) : On prédit la classe de toute la phrase (par exemple, pour l’analyse de sentiment).
Prédiction au niveau des tokens (token-level prediction) : On prédit la classe de chaque token (par exemple, pour la reconnaissance d’entités nommées).
Contrairement à GPT, l’architecture de BERT repose sur le bloc encodeur du transformer, et non sur le bloc décodeur (voir cours 7 pour rappel).
Tokens et embeddings#
Tout d’abord, notons que le token [CLS] est ajouté au début de chaque séquence d’entrée. Son utilisation sera expliquée plus tard dans la partie sur le finetuning du modèle.
Lors du pré-entraînement, BERT prend en entrée deux séquences de tokens, séparées par un token [SEP]. En plus de cette séparation, un segment embedding est ajouté à chaque token embedding pour indiquer la phrase d’origine (1 ou 2). Comme pour GPT, un position embedding est également ajouté à chaque token embedding.
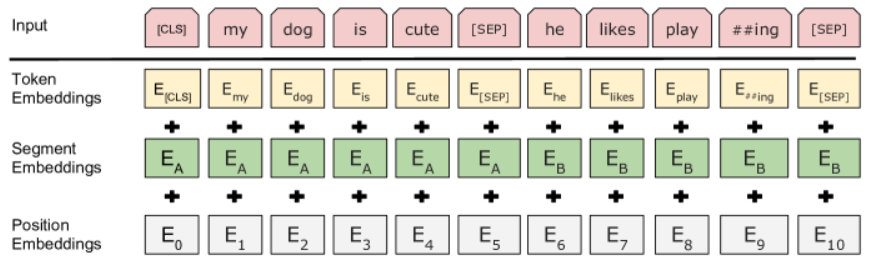
Note : Le terme “phrase” ne doit pas être compris au sens linguistique, mais plutôt comme une séquence de tokens qui se suivent.
Pré-entraînement de BERT#
Tâche 1 : Prédiction des mots masqués#
Pour GPT, l’entraînement consistait à masquer les tokens futurs (le token à prédire et ceux à droite). Cependant, comme BERT est bidirectionnel, cette méthode n’est pas applicable.
À la place, les auteurs proposent de masquer aléatoirement 15% des tokens et d’entraîner le modèle à prédire ces mots. BERT est alors appelé un Masked Language Model (MLM). L’idée est de remplacer ces tokens par des tokens [MSK].
Lors du finetuning, il n’y a pas de tokens [MSK]. Pour compenser cela, les auteurs suggèrent de ne pas convertir tous les 15% de tokens en [MSK], mais de procéder comme suit :
80% des tokens sont convertis en [MSK].
10% sont remplacés par un autre token aléatoire.
10% restent inchangés.
Cette technique améliore l’efficacité du finetuning.
Note : Attention à ne pas confondre le terme masked. Le Masked Language Model (MLM) n’utilise pas de couche masked self-attention, contrairement à GPT (qui n’est pas un MLM).
Note 2 : Un parallèle intéressant peut être établi entre BERT et un denoising autoencoder. En effet, BERT corrompt le texte d’entrée en masquant certains tokens et tente de prédire le texte original. De même, un denoising autoencoder corrompt une image en ajoutant du bruit et tente de prédire l’image originale. L’idée est similaire, mais en pratique, il y a une différence : les denoising autoencoders reconstruisent toute l’image, tandis que BERT se contente de prédire les tokens manquants sans toucher aux autres tokens de l’entrée.
Tâche 2 : Prédiction de la prochaine phrase#
De nombreuses tâches de NLP reposent sur les relations entre deux phrases. Ces relations ne sont pas directement capturées par le language modeling, d’où l’intérêt d’ajouter un objectif spécifique pour les comprendre.
Pour cela, BERT ajoute une prédiction binaire de next sentence prediction. On prend une phrase A et une phrase B, séparées par un token [SEP]. 50% du temps, les phrases A et B se suivent dans le texte original, et 50% du temps, ce n’est pas le cas. BERT doit alors prédire si ces phrases se suivent.
Cet ajout d’objectif d’entraînement est très bénéfique, notamment pour le finetuning de BERT sur des tâches de réponse aux questions, par exemple.
Données utilisées pour l’entraînement#
L’article indique également les données utilisées pour l’entraînement. Cette information est de plus en plus rare de nos jours.
BERT a été entraîné sur deux ensembles de données :
BooksCorpus (800 millions de mots) : Un dataset contenant environ 7000 livres.
English Wikipedia (2500 millions de mots) : Un dataset contenant les textes de la version anglaise de Wikipedia (uniquement le texte, sans les listes, etc.).
Finetuning de BERT#
Le finetuning de BERT est assez simple. On utilise les entrées et sorties de la tâche souhaitée et on réentraîne tous les paramètres du modèle.
Il existe deux grandes familles de tâches :
Prédiction au niveau de la phrase (sentence-level prediction) : Pour ces tâches, on utilise le token [CLS] pour extraire la classification de la phrase. Le token [CLS] permet au modèle de fonctionner quelle que soit la taille de la phrase d’entrée (dans la limite du contexte), sans biais lié au choix du token. Sans le token [CLS], on serait obligé d’utiliser l’une de ces deux méthodes :
Connecter tous les embeddings de sortie à une couche fully connected pour obtenir la prédiction (mais cela ne fonctionnerait pas pour une taille de séquence arbitraire).
Prédire à partir de l’embedding d’un token choisi au hasard (mais cela pourrait biaiser le résultat en fonction du token sélectionné).
Prédiction au niveau des tokens (token-level prediction) : Pour cette tâche, on prédit une classe pour chaque embedding de token, car on souhaite un label par token.
Note : Le finetuning de BERT ou d’un autre LLM est beaucoup moins coûteux que le pré-entraînement du modèle. Une fois qu’on a un modèle pré-entraîné, on peut le réutiliser sur un grand nombre de tâches à moindre coût.