Introduction aux transformers#
Dans le chapitre précédent, on a découvert plein d’applications de la library Transformers de Hugging Face. Comme son nom l’indique, cette library gère des modèles transformers. Mais alors, qu’est-ce qu’un modèle transformer ?
Le transformer, d’où ça vient ?#
Jusqu’en 2017, la plupart des réseaux de neurones pour le NLP utilisaient des RNN. En 2017, des chercheurs de Google ont publié un article qui a révolutionné le domaine du NLP, puis plus tard d’autres domaines du deep learning (vision, audio, etc.). Ils ont introduit l’architecture transformer dans leur papier “Attention Is All You Need”.
Voici à quoi ressemble l’architecture du transformer :
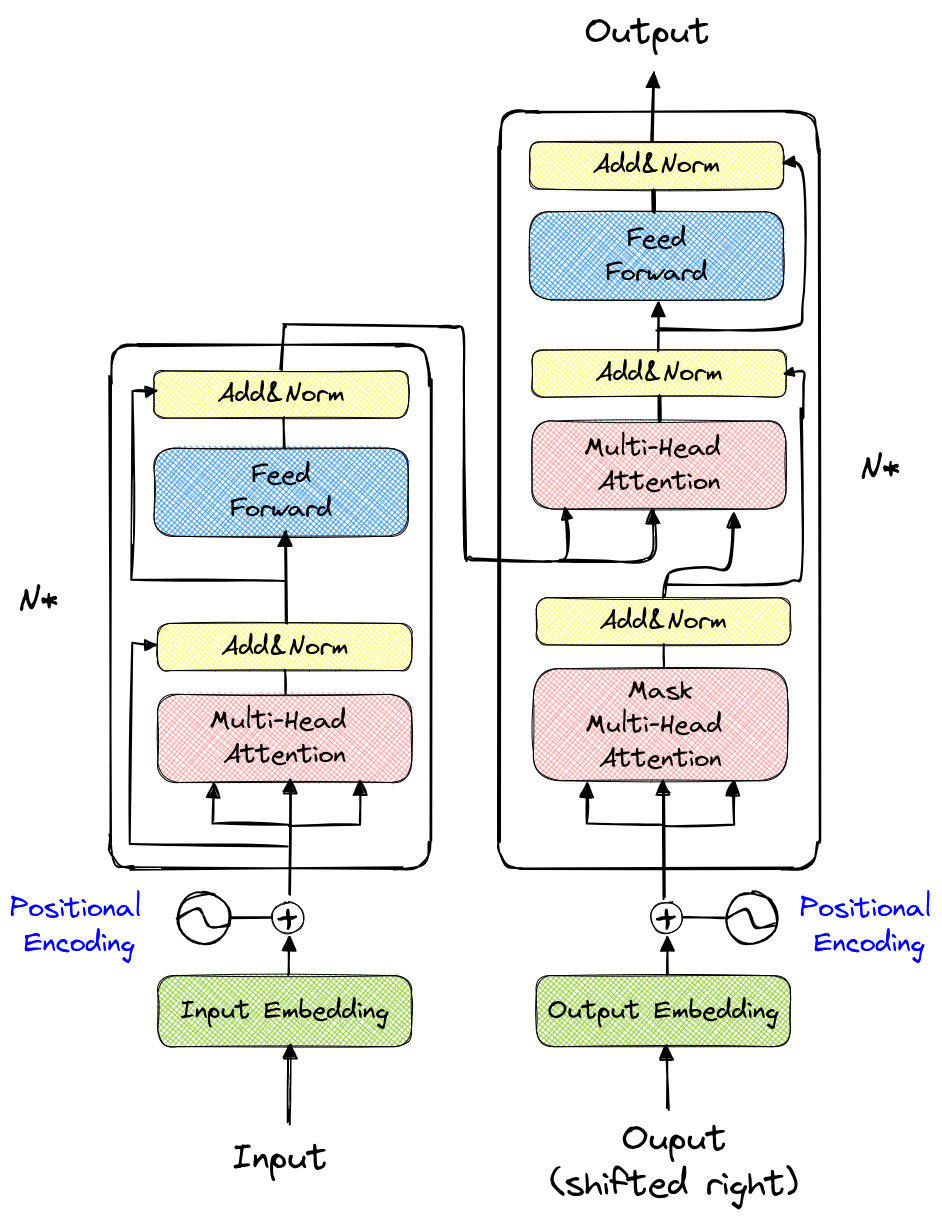
À première vue, ça semble bien compliqué. La partie de gauche s’appelle l’encodeur et celle de droite, le décodeur.
Contenu du cours#
Première partie : construisons GPT from scratch#
La première partie de ce cours s’inspire grandement de la vidéo “Let’s build GPT: from scratch, in code, spelled out.” d’Andrej Karpathy. On y implémente un modèle qui prédit le prochain caractère en se basant sur les caractères précédents (un peu comme dans le cours 5 sur le NLP). Cette partie va nous aider à comprendre l’intérêt de l’architecture transformer, surtout du côté du décodeur.
Dans cette partie, on va entraîner un modèle à écrire du “Molière” automatiquement.
Deuxième partie : Théorie et encodeur#
La deuxième partie aborde des concepts un peu plus mathématiques et présente aussi le décodeur de l’architecture transformer.
Troisième partie : ViT, BERT et autres architectures marquantes#
Cette troisième partie présente rapidement des adaptations de l’architecture transformer pour des tâches différentes de GPT.
Quatrième partie : Implémentation du Vision Transformer#
Dans la quatrième partie, on implémente le vision transformer à partir du papier An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale et on l’entraîne sur le dataset CIFAR-10.
Cinquième partie : Implémentation du Swin Transformer#
Cette cinquième et dernière partie propose une explication du papier Swin Transformer: Hierarchical Vision Transformer using Shifted Windows ainsi qu’une implémentation simplifiée.