Ajuste fino (Fine-Tuning) de los LLM#
En este curso, estudiaremos en detalle el artículo BERT: Pre-entrenamiento de Transformadores Bidireccionales Profundos para la Comprensión del Lenguaje, ya mencionado en el curso 7 sobre transformadores.
La mayoría de los LLM (como GPT y BERT) se pre-entrenan en tareas de predicción de palabras (predicción de la siguiente palabra o predicción de palabras enmascaradas). Luego, se ajustan finamente para tareas más específicas. Sin este ajuste fino, estos modelos generalmente no son muy útiles.
Nota: El ajuste fino de un LLM implica reentrenar todos sus parámetros. En cambio, para los modelos de visión como las CNN, a menudo solo se reentrena una parte de las capas (a veces solo la última).
Diferencias entre BERT y GPT#
En el curso sobre transformadores, presentamos GPT e implementamos un ejemplo. GPT es unidireccional: para predecir un token, solo utiliza los tokens anteriores. Sin embargo, este enfoque no es óptimo para muchas tareas, ya que a menudo se necesita el contexto completo de la oración.
BERT propone una alternativa con un transformador bidireccional, que utiliza el contexto de ambos lados para la predicción. Su arquitectura permite un ajuste fino para dos tipos de tareas:
Predicción a nivel de oración (sentence-level prediction): Se predice la clase de toda la oración (por ejemplo, para el análisis de sentimiento).
Predicción a nivel de tokens (token-level prediction): Se predice la clase de cada token (por ejemplo, para el reconocimiento de entidades nombradas).
A diferencia de GPT, la arquitectura de BERT se basa en el bloque codificador (encoder) del transformador, y no en el bloque decodificador (ver curso 7 para recordar).
Tokens y embeddings#
En primer lugar, cabe señalar que el token [CLS] se añade al inicio de cada secuencia de entrada. Su uso se explicará más adelante en la sección sobre el ajuste fino del modelo.
Durante el pre-entrenamiento, BERT toma como entrada dos secuencias de tokens, separadas por un token [SEP]. Además de esta separación, se añade un embedding de segmento a cada embedding de token para indicar la frase de origen (1 o 2). Al igual que en GPT, también se añade un embedding de posición a cada embedding de token.
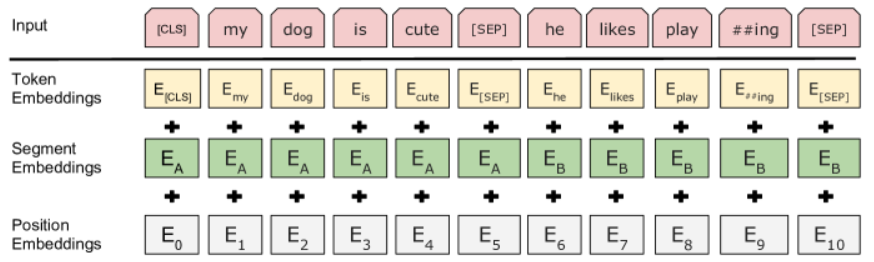
Nota: El término “frase” no debe entenderse en el sentido lingüístico, sino más bien como una secuencia de tokens que se suceden.
Pre-entrenamiento de BERT#
Tarea 1: Predicción de palabras enmascaradas#
Para GPT, el entrenamiento consistía en enmascarar los tokens futuros (el token a predecir y los que están a la derecha). Sin embargo, como BERT es bidireccional, este método no es aplicable.
En su lugar, los autores proponen enmascarar aleatoriamente el 15% de los tokens y entrenar al modelo para predecir estas palabras. BERT se denomina entonces Modelo de Lenguaje Enmascarado (Masked Language Model, MLM). La idea es reemplazar estos tokens por tokens [MASK].
Durante el ajuste fino, no hay tokens [MASK]. Para compensar esto, los autores sugieren no convertir todos los tokens del 15% en [MASK], sino proceder de la siguiente manera:
80% de los tokens se convierten en
[MASK].10% se reemplazan por otro token aleatorio.
10% permanecen sin cambios.
Esta técnica mejora la eficacia del ajuste fino.
Nota: Cuidado con no confundir el término masked. El Masked Language Model (MLM) no utiliza una capa de masked self-attention, a diferencia de GPT (que no es un MLM).
Nota 2: Se puede establecer un paralelo interesante entre BERT y un autoencoder desruidoso (denoising autoencoder). Efectivamente, BERT corrompe el texto de entrada enmascarando ciertos tokens e intenta predecir el texto original. Del mismo modo, un denoising autoencoder corrompe una imagen añadiendo ruido e intenta predecir la imagen original. La idea es similar, pero en la práctica hay una diferencia: los denoising autoencoders reconstruyen toda la imagen, mientras que BERT solo predice los tokens faltantes sin modificar los demás tokens de la entrada.
Tarea 2: Predicción de la siguiente frase#
Muchas tareas de PLN dependen de las relaciones entre dos frases. Estas relaciones no son capturadas directamente por el modelado de lenguaje (language modeling), de ahí el interés de añadir un objetivo específico para comprenderlas.
Para ello, BERT añade una predicción binaria de next sentence prediction (predicción de la siguiente frase). Se toman una frase A y una frase B, separadas por un token [SEP]. El 50% del tiempo, las frases A y B se suceden en el texto original, y el otro 50% no es así. BERT debe entonces predecir si estas frases se suceden.
Esta adición de objetivos de entrenamiento es muy beneficiosa, especialmente para el ajuste fino de BERT en tareas como la respuesta a preguntas.
Datos utilizados para el entrenamiento#
El artículo también indica los datos utilizados para el entrenamiento. Esta información es cada vez más rara en la actualidad.
BERT se entrenó con dos conjuntos de datos:
BooksCorpus (800 millones de palabras): Un conjunto de datos que contiene aproximadamente 7000 libros.
Wikipedia en inglés (2500 millones de palabras): Un conjunto de datos que contiene los textos de la versión en inglés de Wikipedia (solo el texto, sin listas, etc.).
Ajuste fino de BERT#
El ajuste fino de BERT es bastante sencillo. Se utilizan las entradas y salidas de la tarea deseada y se reentrenan todos los parámetros del modelo.
Existen dos grandes familias de tareas:
Predicción a nivel de oración (sentence-level prediction): Para estas tareas, se utiliza el token
[CLS]para extraer la clasificación de la oración. El token[CLS]permite que el modelo funcione independientemente del tamaño de la oración de entrada (dentro del límite del contexto), sin sesgos relacionados con la elección del token. Sin el token[CLS], se tendría que utilizar uno de estos dos métodos:Conectar todos los embeddings de salida a una capa totalmente conectada (fully connected) para obtener la predicción (pero esto no funcionaría para un tamaño de secuencia arbitrario).
Predecir a partir del embedding de un token elegido al azar (pero esto podría sesgar el resultado según el token seleccionado).
Predicción a nivel de tokens (token-level prediction): Para esta tarea, se predice una clase para cada embedding de token, ya que se desea una etiqueta por token.
Nota: El ajuste fino de BERT u otro LLM es mucho menos costoso que el pre-entrenamiento del modelo. Una vez que se tiene un modelo pre-entrenado, se puede reutilizar en un gran número de tareas con un coste reducido.