Introducción al PLN#
¿Qué es el PLN?#
El PLN (Procesamiento de Lenguaje Natural, por sus siglas en inglés Natural Language Processing) es un campo clave en el aprendizaje automático. Abarca diversas tareas relacionadas con el texto, como la traducción automática, la comprensión de textos, los sistemas de preguntas y respuestas, entre otros.
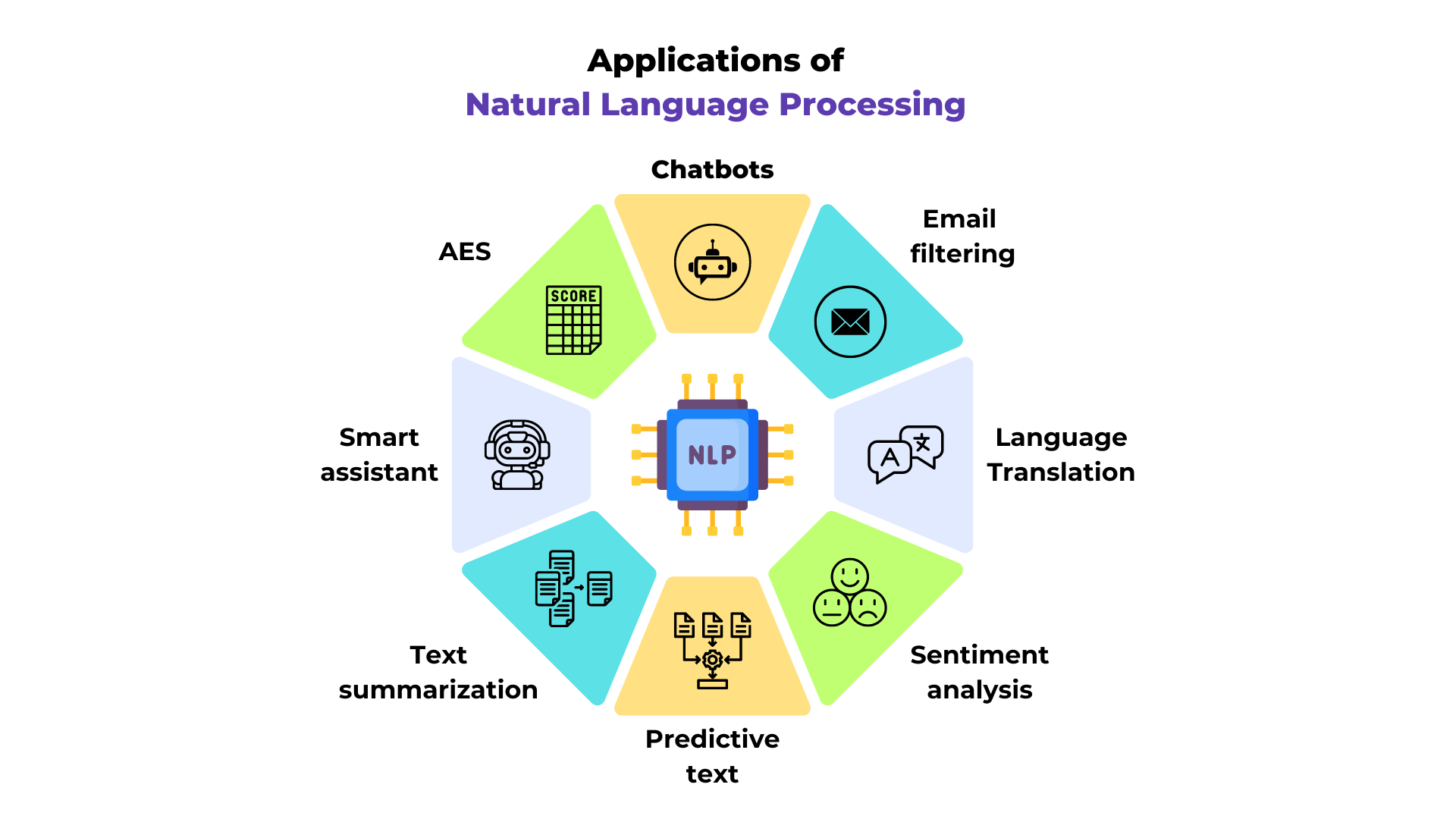
Figura extraída del artículo.
El PLN destaca en el deep learning porque procesa datos discretos (como el texto), que suelen leerse de izquierda a derecha.
Contenido del curso#
Este curso se centra en la predicción del siguiente token, comenzando por la predicción del siguiente carácter para simplificar. Este problema es la base de los modelos de lenguaje (como GPT, Llama, Gemini, etc.).
El objetivo es predecir la siguiente palabra en función de las palabras anteriores, utilizando un contexto más o menos extenso según el método y la capacidad del modelo. El contexto se define por el número de tokens (palabras o unidades de texto) usados para la predicción.
¿Qué es un token? Un token es una unidad básica de entrada para el modelo. Puede ser:
Un carácter (ej:
'a'),Un grupo de caracteres (ej:
'ch'),Una palabra completa (ej:
'hola').
Antes de procesarse, cada token se convierte en un vector numérico (embedding) que el modelo puede interpretar.
Inspiración del curso#
Este curso está ampliamente inspirado en la serie de videos de Andrej Karpathy (repositorio en GitHub), especialmente en sus lecciones “building makemore”. Aquí presentamos una versión escrita y en español de estos contenidos. Recomendación: Ver esta serie de videos, ya que es uno de los mejores cursos sobre modelos de lenguaje disponibles actualmente (y es gratuito).
El curso está estructurado en varios notebooks, con modelos de dificultad progresiva. La idea es entender las limitaciones de cada modelo antes de avanzar a uno más complejo.
Temario del curso:
Clase 1: Modelos de bigramas (método clásico y redes neuronales).
Clase 2: Predicción de la siguiente palabra con una red fully connected.
Clase 3: WaveNet (arquitectura jerárquica).
Clase 4: RNN (redes neuronales recurrentes con arquitectura secuencial).
Clase 5: LSTM (red recurrente “mejorada”).
Nota: La Clase 7 sobre transformers aborda el mismo problema de generación del siguiente carácter, pero con una arquitectura transformer y un dataset más complejo.
Obtención del dataset prenoms.txt#
En este curso, utilizamos un dataset de nombres propios con aproximadamente 30,000 de los nombres más comunes en Francia desde 1900 (datos del INSEE). El archivo prenoms.txt ya está incluido en la carpeta, por lo que no es necesario ejecutar el código a continuación.
Si deseas generarlo tú mismo, primero debes descargar el archivo nat2022.csv desde el sitio web del INSEE.
import pandas as pd
# Chargement du fichier CSV
df = pd.read_csv('nat2022.csv', sep=';')
# On enlève la catégorie '_PRENOMS_RARES' qui regroupe les prénoms peu fréquents
df_filtered = df[df['preusuel'] != '_PRENOMS_RARES']
# Pour compter, on fait la somme des nombres de naissances pour chaque prénom
df_grouped = df_filtered.groupby('preusuel', as_index=False)['nombre'].sum()
# On va trier les prénoms par popularité
df_sorted = df_grouped.sort_values(by='nombre', ascending=False)
# On extrait les 30 000 prénoms les plus populaires
top_prenoms = df_sorted['preusuel'].head(30000).values
with open('prenoms.txt', 'w', encoding='utf-8') as file:
for prenom in top_prenoms:
file.write(f"{prenom}\n")
En el siguiente notebook, analizaremos el dataset (caracteres únicos, distribución, etc.).