Introducción a Hugging Face#
¿Qué es?#
Hugging Face es una empresa líder en la comunidad de código abierto en inteligencia artificial. Ofrece un sitio web que agrupa datasets, modelos y spaces (espacios), junto con varias bibliotecas, principalmente transformers, diffusers y datasets.
¿Por qué usar Hugging Face? Hugging Face proporciona acceso simplificado a modelos complejos de vanguardia. Permite utilizar estos modelos de manera rápida y eficiente. Además, es posible probar modelos a través de la categoría spaces del sitio y descargar datasets compartidos por la comunidad. En cierto modo, es el “GitHub” del deep learning.
¿Qué aprenderemos en este curso?#
Este curso es menos teórico que los anteriores, pero permite explorar modelos de alto rendimiento y descubrir las capacidades actuales del deep learning. Se inspira en los recursos disponibles en el sitio de Hugging Face y en el curso gratuito de deeplearning.ai titulado “Open Source Models with Hugging Face”. Te animo a consultarlo, ya que presenta numerosas aplicaciones en visión, audio y PNL (Procesamiento de Lenguaje Natural).
Plan del curso:
En esta introducción, presentamos el sitio de Hugging Face y sus tres categorías principales: Models (Modelos), Datasets (Conjuntos de datos) y Spaces (Espacios).
Los tres notebooks siguientes están dedicados al uso de la biblioteca transformers: el primero aborda modelos de visión, el segundo el PNL y el tercero el audio.
A continuación, un notebook se centra en la biblioteca diffusers, que permite utilizar modelos de difusión (como Stable Diffusion) para generar imágenes.
Finalmente, el último notebook presenta Gradio, una biblioteca que facilita la creación rápida de interfaces para demostraciones.
Sitio web de Hugging Face#
Spaces (Espacios)#
La categoría más interactiva y accesible es Spaces, que agrupa demostraciones de diferentes modelos.
A continuación, se muestra el aspecto de la página de inicio:
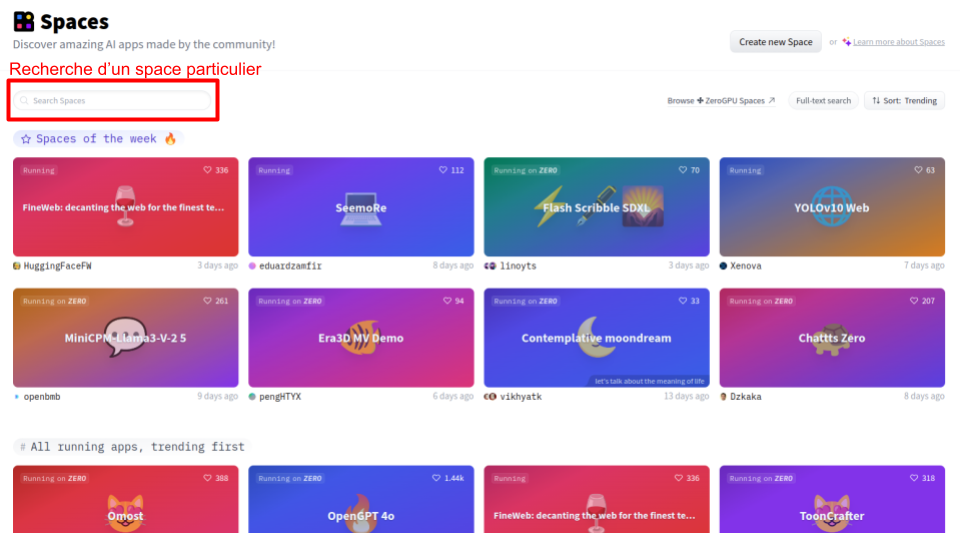
Las demostraciones (spaces) están clasificadas por uso y popularidad, pero puedes utilizar la función “Search spaces” para buscar un modelo específico que desees probar. También te recomiendo explorar regularmente los diferentes espacios, ya que esto permite mantenerse al día con las novedades en el campo del deep learning.
Si entrenas tu propio modelo, puedes compartirlo gratuitamente en un espacio mediante la herramienta “Create New Space”. Para ello, es necesario dominar los conceptos básicos de la biblioteca Gradio, que abordaremos en el último notebook de este curso.
Modelos#
A veces, un modelo que deseas probar no está disponible en los spaces o prefieres utilizarlo en tu propio código. En ese caso, debes acceder a la categoría Models del sitio. La página Models agrupa numerosos modelos de código abierto.
A continuación, se muestra el aspecto de la página:
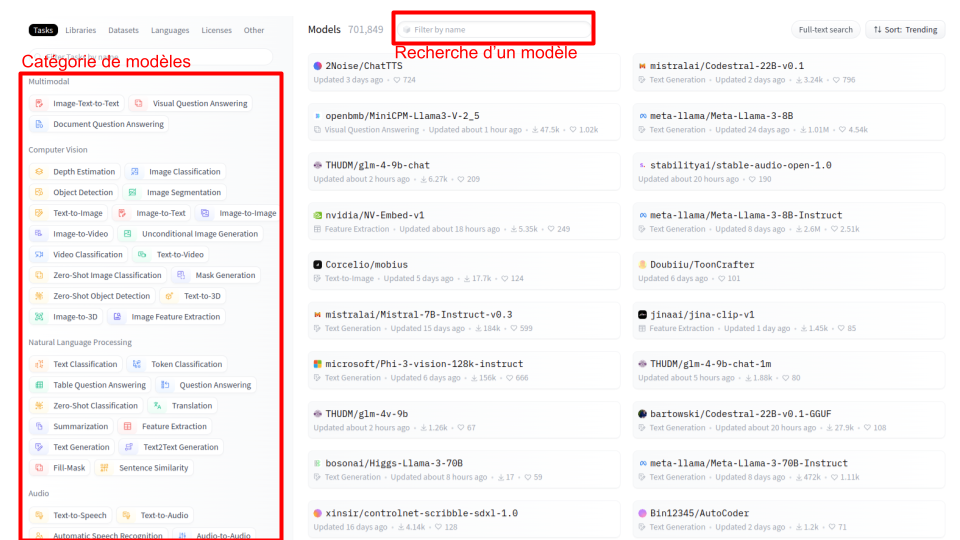
Esta página contiene mucha información. Puedes buscar un modelo específico por su nombre mediante la opción “Filter by name”. También puedes utilizar los filtros de la izquierda para buscar modelos por categoría.
Por ejemplo, supongamos que busco un modelo de “zero-shot object detection”, que permite detectar cualquier objeto en una imagen a partir de un prompt.
¿Qué es un prompt? Un prompt es una entrada que guía al modelo en su tarea. En PNL (Procesamiento de Lenguaje Natural), un prompt es simplemente la entrada del modelo, es decir, el texto ingresado por el usuario. Un prompt también puede ser una coordenada en una imagen (para tareas de segmentación) o incluso una imagen o un video. Sin embargo, en la mayoría de los casos, cuando hablamos de prompt, nos referimos a un texto añadido como entrada del modelo.
En el caso de “zero-shot object detection”, si quiero detectar plátanos en una imagen, la entrada del modelo será la imagen junto con el texto “banana”.
Para encontrar un modelo que se ajuste a mis necesidades, utilizo el filtro de la izquierda seleccionando la categoría “zero-shot object detection” y reviso los modelos sugeridos.
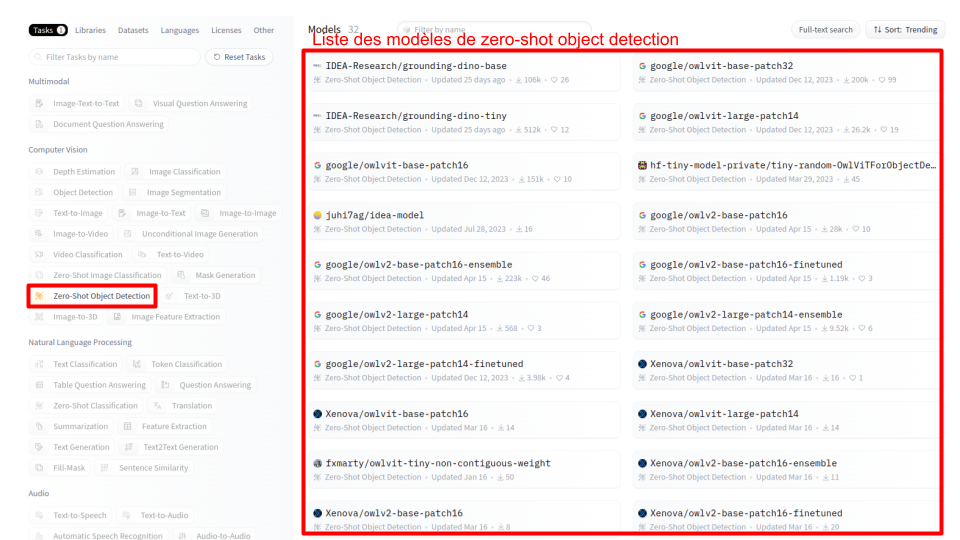
El modelo “IDEA-Research/grounding-dino-tiny” me parece adecuado. Lo selecciono y llego a la siguiente página:
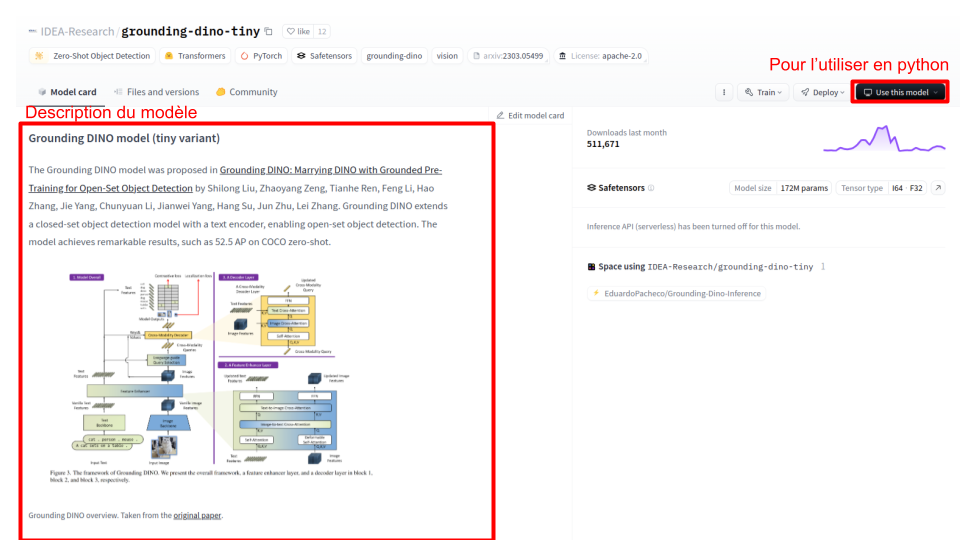
La model card (tarjeta del modelo) proporciona una descripción detallada del modelo (su funcionamiento, capacidades, etc.). Para obtener el código que permite utilizarlo directamente en Python (a través de la biblioteca transformers o diffusers, según el modelo elegido), puedes hacer clic en el botón Use this model.
A continuación, se muestra el código correspondiente para el modelo seleccionado:
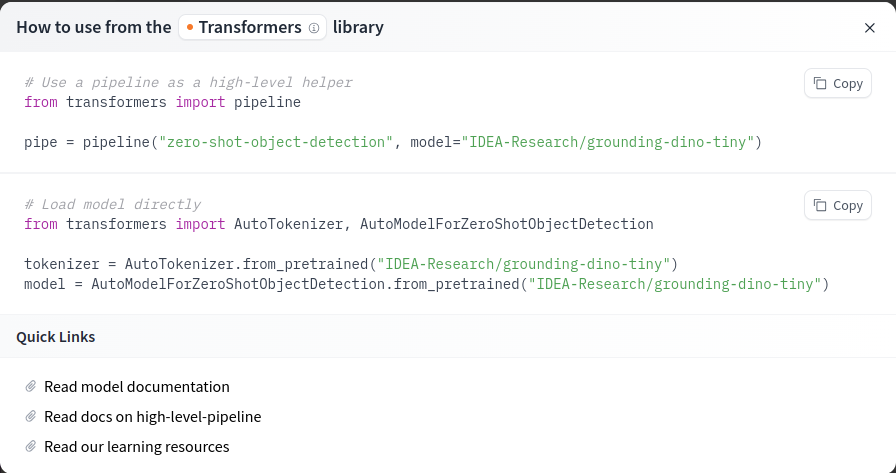
En los notebooks siguientes, veremos cómo utilizar este código para nuestra tarea.
Datasets (Conjuntos de datos)#
Si deseas entrenar tu propio modelo, es necesario contar con un dataset. Puedes optar por crearlo tú mismo, pero existen numerosos datasets de código abierto disponibles, especialmente en Hugging Face.
La página Datasets es similar a la página de Models, con funciones de filtrado y búsqueda:
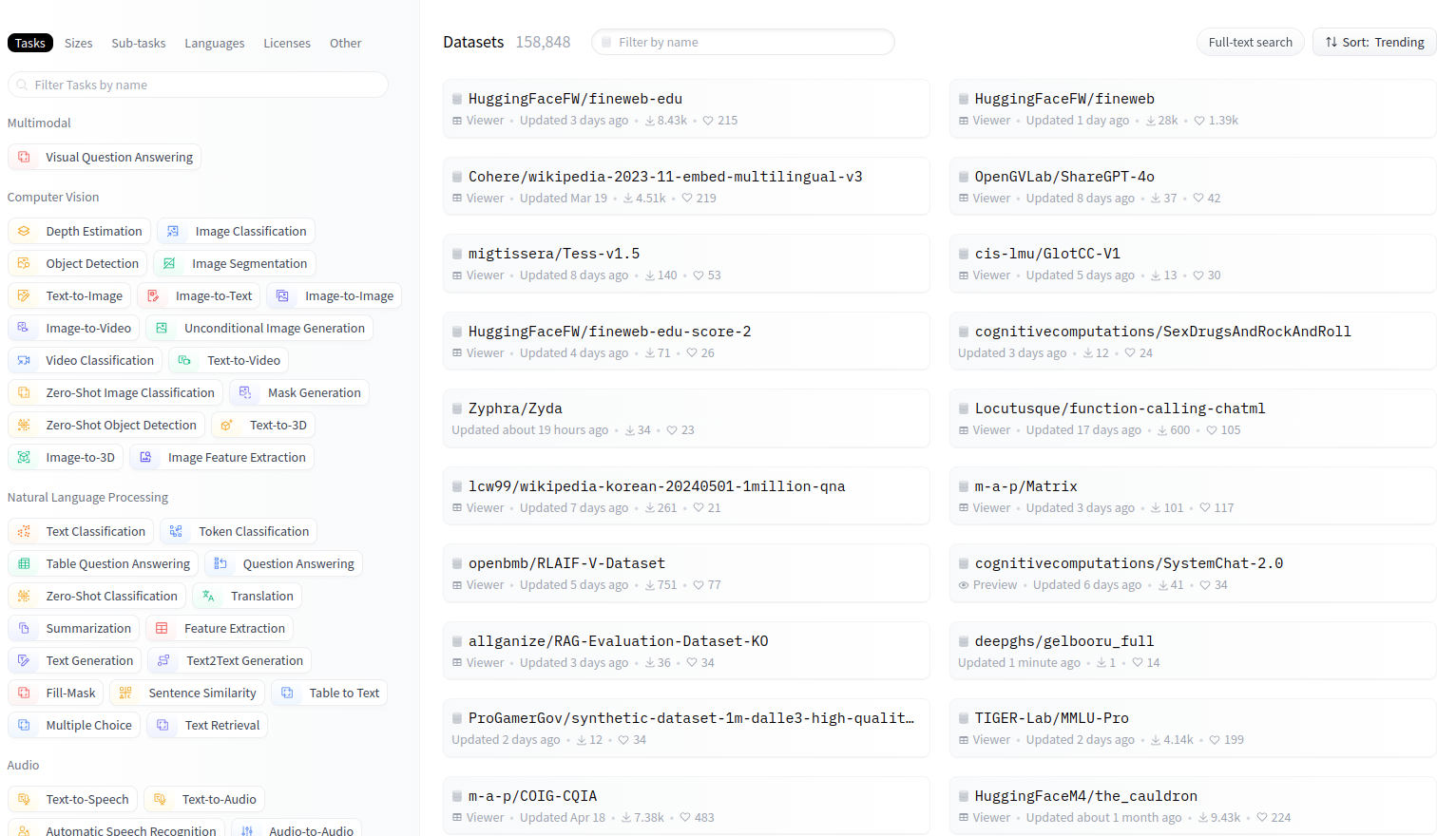
Puedes seleccionar un dataset y llegar a la siguiente página:
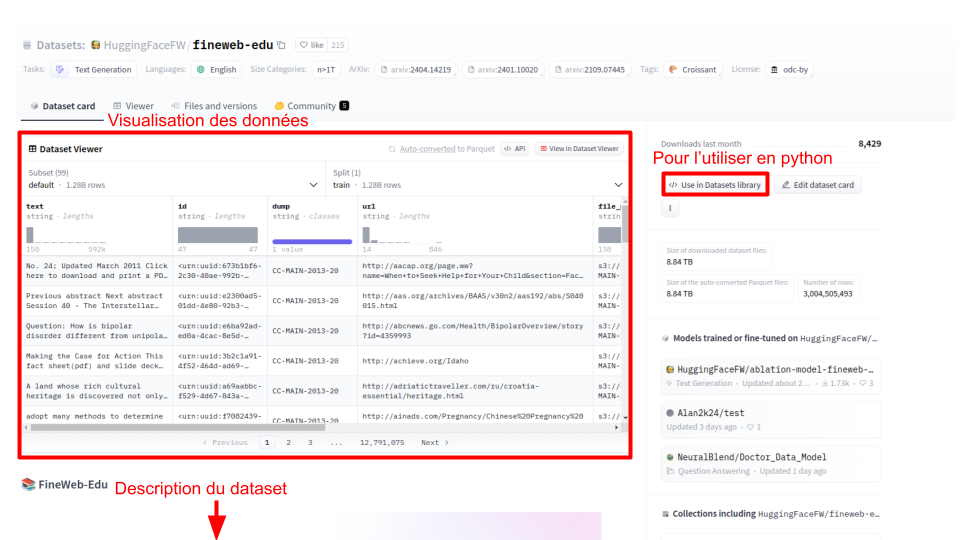
Al igual que con los modelos, la Dataset card (tarjeta del dataset) permite visualizar los datos del conjunto y obtener una descripción del mismo. Para utilizarlo directamente en Python, puedes hacer clic en Use in Datasets library para obtener el código correspondiente.
Otras categorías#
El sitio es más completo de lo que se muestra aquí, pero esta introducción no pretende ser exhaustiva. Te invito a explorar el sitio por tu cuenta para descubrir aspectos que te interesen. En los notebooks siguientes, presentaremos una visión general de los tipos de modelos disponibles y su uso en Python a través de Hugging Face.