Introducción a la detección de objetos en imágenes#
El procesamiento de imágenes se divide en tres grandes categorías:
Clasificación: Determina si un objeto está presente en la imagen (ejemplo: ¿es una foto de un perro?).
Detección: Localiza la posición de un objeto en la imagen (ejemplo: ¿dónde está el perro?).
Segmentación: Identifica los píxeles que pertenecen a un objeto (ejemplo: ¿cuáles son los píxeles del perro?).

Imagen extraída de este sitio.
En el curso sobre CNN, abordamos problemas de clasificación con una arquitectura CNN clásica terminada en una capa Fully Connected, así como problemas de segmentación con el modelo U-Net.
La detección de objetos es más compleja de explicar, por lo que este curso se centra en los métodos existentes y en una descripción detallada del modelo YOLO.
Primero, explicaremos las diferencias entre las dos categorías principales de detectores:
Métodos de dos etapas (Two-Stage Detectors): Incluyen la familia de RCNN (Region-based Convolutional Neural Networks).
Métodos de una etapa (Single-Stage Detectors): Incluyen la familia de YOLO (You Only Look Once).
Detectores de dos etapas#
Como su nombre indica, el detector de dos etapas sigue dos pasos para detectar objetos:
Primer paso: Propuesta de regiones (region proposal), donde podrían encontrarse objetos de interés.
Segundo paso: Afinamiento de la detección, es decir, la asociación de la clase del objeto y la precisión de la bounding box (si hay un objeto presente).
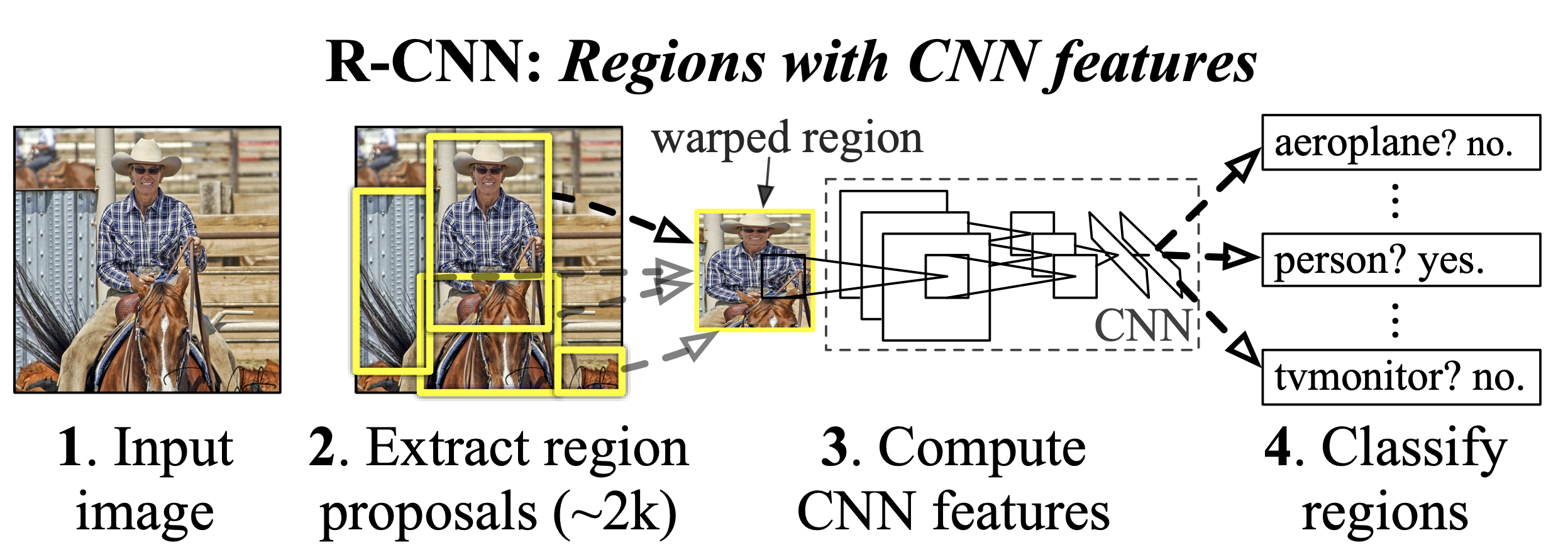
Imagen extraída del artículo.
En general, los detectores de dos etapas son muy precisos y permiten detecciones complejas, pero son bastante lentos y no permiten un procesamiento en tiempo real.
Los modelos two-stage más conocidos son la familia RCNN. Para más información, consulta este artículo.
Detectores de una etapa#
El detector de una etapa solo requiere un paso para generar las bounding box con sus etiquetas correspondientes. La red divide la imagen en una cuadrícula y predice múltiples bounding box y sus probabilidades para cada celda de la cuadrícula.
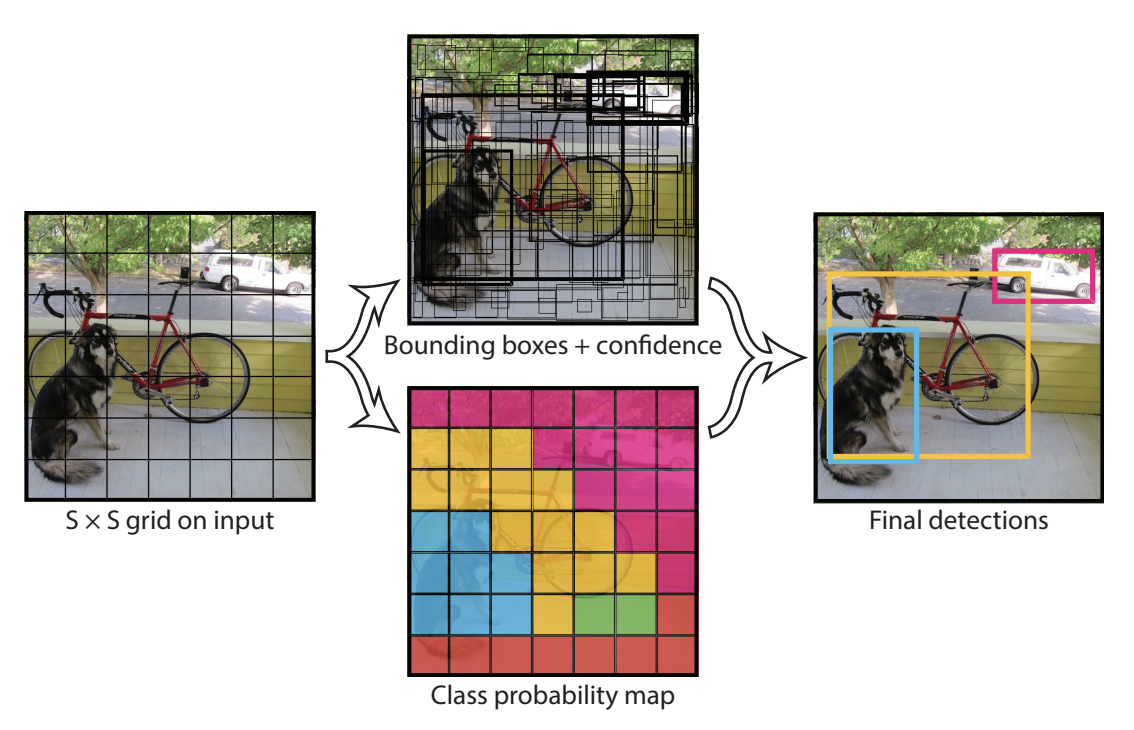
Figura extraída del artículo.
Los detectores de una etapa suelen ser menos precisos que los detectores de dos etapas, pero son mucho más rápidos y permiten un procesamiento en tiempo real. Actualmente, son la familia de detectores más utilizada.
Non-Maximum Suppression (NMS) y Anchor Boxes#
NMS (Non-Maximum Suppression)#
Durante la detección de objetos con nuestro modelo, la arquitectura no evita que varias bounding box se superpongan sobre el mismo objeto. Antes de enviar las detecciones al usuario, queremos tener una sola detección por objeto, la más relevante posible.
Aquí es donde interviene el Non-Maximum Suppression (NMS). El algoritmo no se detallarán en este curso, pero puedes consultar los siguientes recursos para más información: artículo y sitio.

Anchor Boxes#
Las anchor boxes son bounding boxes predefinidas colocadas en una cuadrícula regular que cubre la imagen. Pueden tener diferentes proporciones (ancho/alto) y tamaños variables para abarcar la mayor cantidad posible de tamaños de objetos. Las anchor boxes reducen el número de posiciones que el modelo debe analizar. Con ellas, el modelo predice el desplazamiento respecto a la anchor box pregenerada y la probabilidad de que pertenezca a un objeto.
Este método mejora la calidad de las detecciones. Para más información, consulta este artículo.
En la práctica, suele haber muchas anchor boxes. La siguiente figura muestra el 1% de las anchor boxes del modelo RetinaNet:

Bonus: Detección de objetos con la arquitectura transformer#
Recientemente, la arquitectura transformer se ha adaptado para la detección de objetos. El modelo DETR utiliza un modelo CNN para extraer características visuales. Estas características se pasan a través de un transformer encoder (con un positional embedding) para determinar las relaciones espaciales entre las características mediante el mecanismo de atención. Un transformer decoder (diferente al utilizado en NLP) toma como entrada la salida del encoder (keys y values) y los embeddings de las etiquetas de los objetos (queries), convirtiendo estos embeddings en predicciones. Finalmente, una capa lineal final procesa la salida del decodificador para predecir las etiquetas y las bounding boxes.
Para más información, consulta el artículo o este blog.

Este método ofrece varias ventajas:
No requiere NMS, anchor boxes ni region proposal, lo que simplifica la arquitectura y el proceso de entrenamiento.
El modelo tiene una mejor comprensión global de la escena gracias al mecanismo de atención.
Sin embargo, también presenta algunos inconvenientes:
Los transformers requieren muchos recursos computacionales, por lo que este modelo es más lento que un detector de una etapa como YOLO.
El entrenamiento suele ser más largo que en un detector basado únicamente en CNN.
Nota: Los transformers utilizados en visión suelen tener tiempos de entrenamiento más largos que los CNN. Una posible explicación es que los CNN tienen un sesgo que los hace especialmente adecuados para imágenes, requiriendo menos tiempo de entrenamiento. Los transformers, al ser modelos generalistas sin sesgo, deben aprender desde cero.