Redes convolucionales#
Intuición#
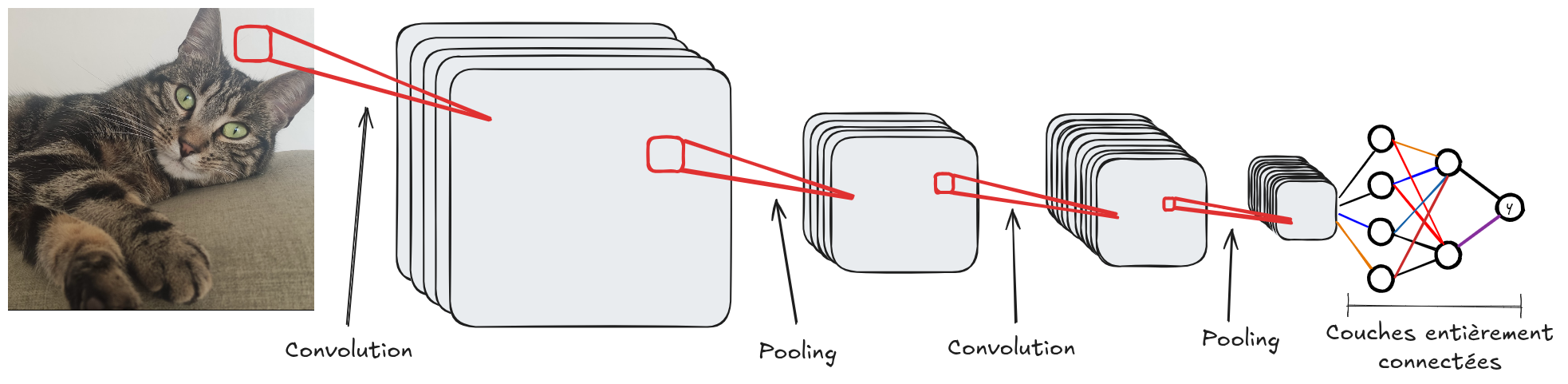
Al igual que las redes completamente conectadas, las redes convolucionales están compuestas por múltiples capas. La idea es aumentar el número de filtros (canales) en profundidad mientras se reduce la resolución espacial de los mapas de características. Esto permite incrementar el nivel de abstracción: las primeras capas detectan principalmente contornos, mientras que las capas más profundas captan información más contextual.
En problemas de clasificación (como MNIST), las últimas capas suelen ser capas completamente conectadas para adaptar la salida de las convoluciones al número de clases.
Una red convolucional generalmente está compuesta por capas de convolución, activación (ReLU, sigmoide, tanH, etc.) y pooling. La capa de convolución ajusta el número de filtros y añade parámetros entrenables. La capa de activación introduce no linealidad en la red, y la capa de pooling reduce la resolución espacial de la imagen.
A continuación, se muestra la arquitectura clásica de una red convolucional:
Campo receptivo#
Como se vio anteriormente, una sola capa de convolución solo permite una interacción local entre píxeles (con un filtro de \(3 \times 3\), cada píxel solo está influenciado por sus vecinos). Esto plantea un problema para detectar elementos que abarcan toda la imagen.
Sin embargo, apilar varias capas de convolución aumenta la zona de influencia de un píxel.
La siguiente imagen ilustra este principio:
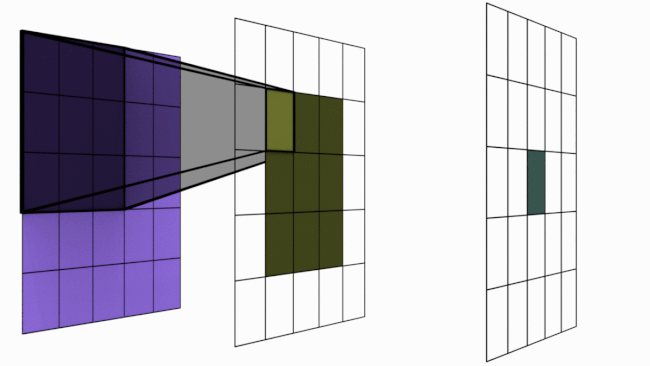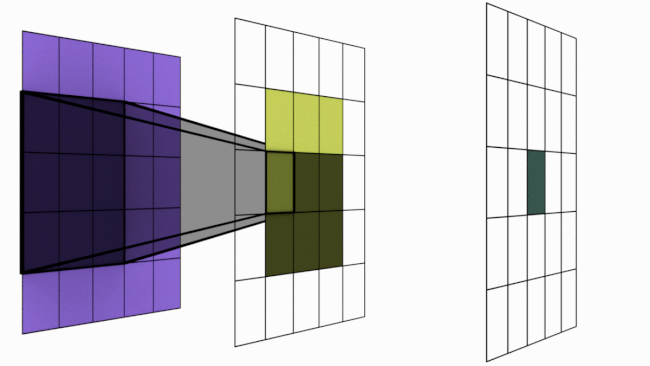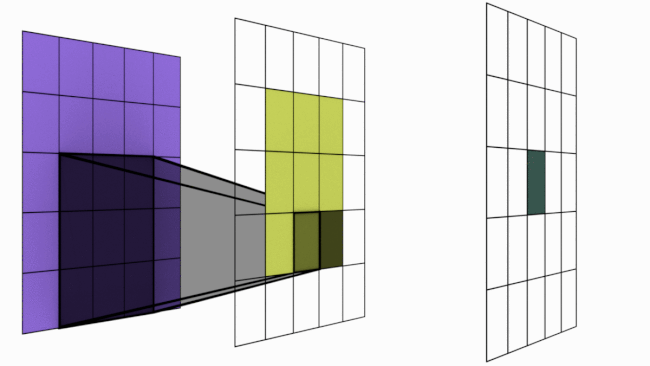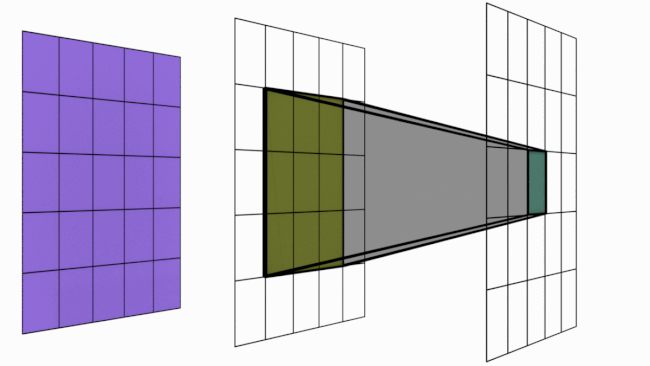
Figura extraída de artículo.
Más formalmente, el campo receptivo de un píxel se calcula con la siguiente fórmula:
\(R_{Eff} = R_{Init} + (k - 1) \cdot S\)
Donde \(R_{Eff}\) es el campo receptivo de la capa de salida, \(R_{Init}\) el campo inicial, \(k\) el tamaño del núcleo y \(S\) el stride (paso).
Al implementar redes convolucionales, es necesario verificar este parámetro para asegurarse de que la red analice correctamente todas las interacciones entre píxeles. Cuanto más grande sea la imagen de entrada, más amplio debe ser el campo receptivo.
Precisión: Las herramientas vistas anteriormente para mejorar los modelos (como BatchNorm y Dropout) también se aplican a las redes convolucionales.
Visualización de lo que aprende la red#
Para comprender el funcionamiento de una red convolucional y el rol de cada capa, podemos visualizar las activaciones de los mapas de características según la profundidad.
A continuación, se muestra una visualización según la profundidad de la red:
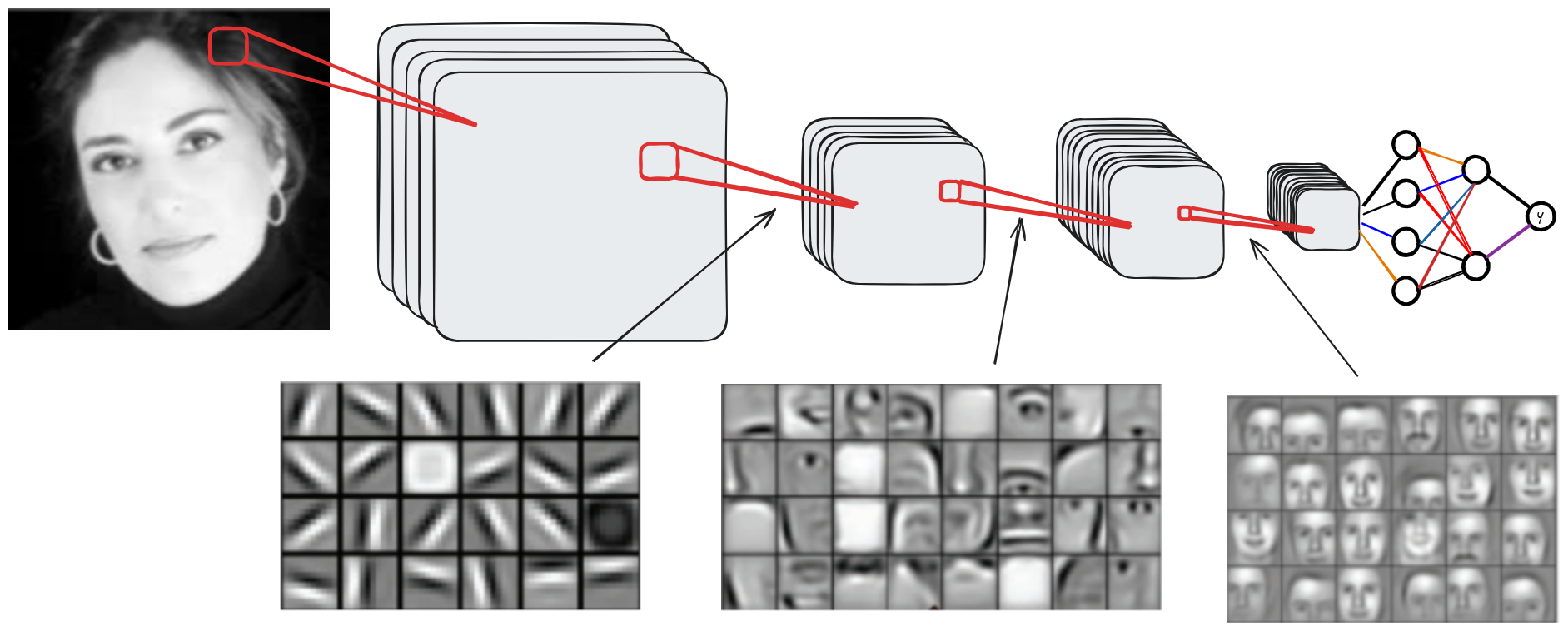
Como se observa, las capas menos profundas captan principalmente información local (contornos, formas básicas), mientras que las capas más profundas contienen información contextual. Las capas intermedias contienen información que abarca una parte significativa de la imagen.