La destilación de conocimientos#
El concepto de destilación de conocimientos fue introducido en el artículo Distilling the Knowledge in a Neural Network en 2015. La idea consiste en utilizar un modelo denominado teacher (un modelo profundo ya entrenado) para transferir sus conocimientos a un modelo más pequeño llamado student.
Funcionamiento#
En la práctica, el modelo student se entrena con dos objetivos:
Minimizar la distancia entre su predicción y la del teacher para el mismo elemento.
Minimizar la distancia entre su predicción y la etiqueta de la entrada.
Estas dos funciones de pérdida (loss) se combinan con un factor de ponderación \(\alpha\) que puede elegirse. Así, el modelo student utiliza tanto la etiqueta de la imagen como la predicción del teacher (una distribución de probabilidad).
Nota: En la práctica, para la primera parte de la función de pérdida (loss), se comparan los logits antes de aplicar la función softmax, en lugar de las probabilidades. Por claridad, utilizaremos el término “predicciones” en lugar de “logits”.

¿Por qué funciona?#
Podemos preguntarnos por qué este método funciona mejor que un entrenamiento directo del student con una función de pérdida (loss) clásica de predicción/etiqueta. Hay varias razones que lo explican:
Transferencia de conocimientos implícitos: Utilizar las predicciones del teacher permite al student aprender conocimientos implícitos sobre los datos. La predicción del teacher es una distribución de probabilidades que indica, por ejemplo, la similitud entre varias clases.
Conservación de relaciones complejas: El teacher es muy complejo y puede capturar estructuras complejas en los datos, algo que no necesariamente ocurre con un modelo más pequeño entrenado desde cero. La destilación permite al student aprender estas relaciones complejas de manera más sencilla, mejorando además la velocidad y reduciendo el uso de memoria (al ser un modelo más pequeño).
Estabilización del entrenamiento: En la práctica, el entrenamiento es más estable para el student con este método de destilación.
Atenuación de problemas de anotación: El teacher ha aprendido a generalizar y puede predecir correctamente incluso si fue entrenado con imágenes que tienen etiquetas incorrectas. En el contexto de la destilación, la diferencia significativa entre la salida del teacher y la etiqueta proporciona información adicional al student sobre la calidad del dato.
Aplicaciones prácticas#
En la práctica, es posible transferir los conocimientos de un modelo de alto rendimiento a un modelo más pequeño sin una pérdida significativa en la calidad de la predicción. Esto es muy útil para reducir el tamaño de los modelos, por ejemplo, en aplicaciones embebidas o procesamientos en CPU. También es posible destilar varios teachers en un solo student. En algunos casos, el student incluso puede superar a cada teacher individualmente.
Es una técnica útil que vale la pena conocer para muchas situaciones.
Otras aplicaciones#
Desde su invención, la destilación de conocimientos se ha adaptado para resolver diversos problemas. Aquí presentamos dos ejemplos: la mejora de la clasificación con NoisyStudent y la detección no supervisada de anomalías con STPM.
Noisy Student: mejorar la clasificación#
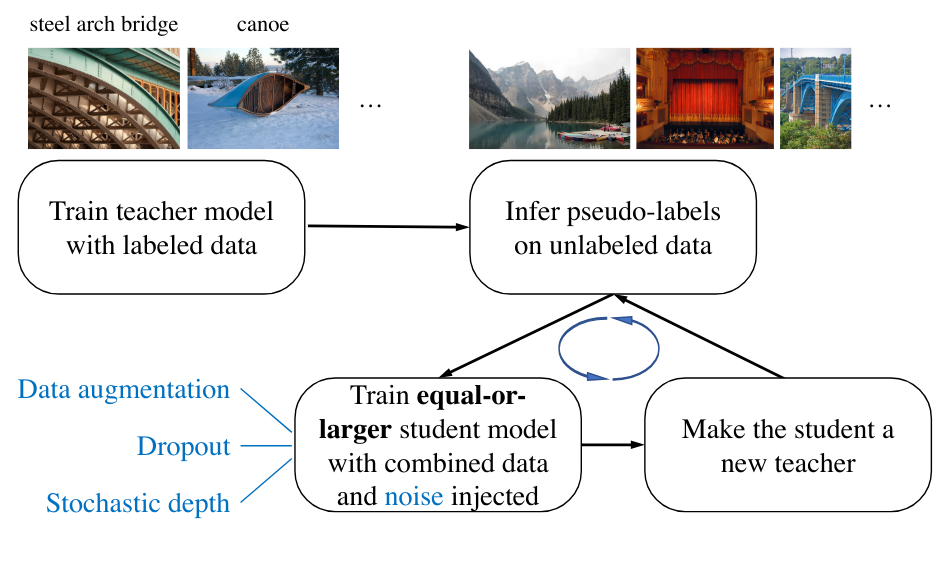
Durante mucho tiempo, la búsqueda de un mejor rendimiento en el conjunto de datos ImageNet ha sido central en la investigación de deep learning. El objetivo era mejorar constantemente el desempeño en este conjunto de datos. En 2020, el artículo Self-training with Noisy Student improves ImageNet classification propone utilizar la destilación para entrenar un modelo student más eficiente que el teacher en cada iteración.
Un modelo student se entrena a partir de pseudo-etiquetas generadas por un modelo teacher (etiquetas creadas por el teacher en imágenes no anotadas). Durante el entrenamiento, se añade ruido para aumentar su robustez. Una vez entrenado el student, se utiliza para obtener nuevas pseudo-etiquetas y entrenar a otro student. Este proceso se repite varias veces, obteniendo finalmente un modelo mucho más eficiente que el teacher original.
STPM: detección no supervisada de anomalías#
Un ejemplo interesante de aplicación de la destilación de conocimientos es la detección no supervisada de anomalías. El artículo Student-Teacher Feature Pyramid Matching for Anomaly Detection adapta esta técnica para este caso de uso.
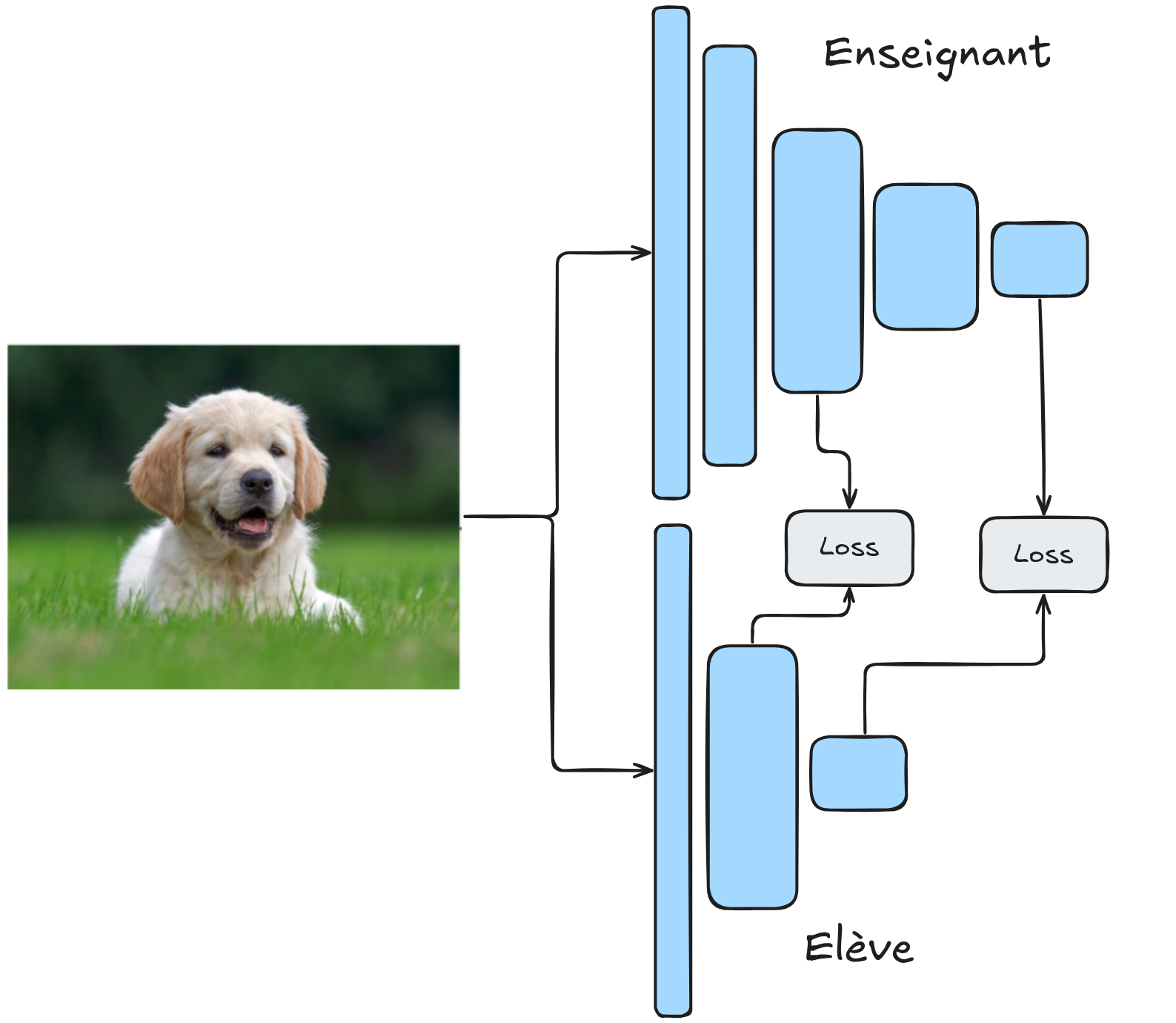
En este caso, el modelo teacher y el modelo student tienen la misma arquitectura. En lugar de centrarse en las predicciones, se analizan los feature maps de las capas intermedias de la red. Durante el entrenamiento, se disponen de datos sin anomalías. El modelo teacher está preentrenado en ImageNet (por ejemplo) y se mantiene fijo durante el entrenamiento. El modelo student se inicializa aleatoriamente y es el que se entrena. Más específicamente, se entrena para reproducir los feature maps del teacher en datos sin defectos. Al final del entrenamiento, el student y el teacher tendrán feature maps idénticos en un elemento sin defectos.
Durante la fase de prueba, se evalúa el modelo con datos sin defectos y con defectos. En los datos sin defectos, el student imita perfectamente al teacher, mientras que en datos defectuosos, los feature maps del student y del teacher difieren. Esto permite calcular una puntuación de similitud, que sirve como puntuación de anomalía.
En la práctica, este método es uno de los más eficientes para la detección no supervisada de anomalías. Este es el método que implementaremos en el siguiente notebook.