Quantization¶
Les modèles de Deep Learning sont de plus en plus puissants et également de plus en plus gros. Si l'on regarde le cas des LLM, les meilleurs LLM ont maintenant plusieurs centaines de milliards de paramètres Llama 3.1 (pour les LLMs Open-Source). Avec un simple GPU, c'est impossible de charger un modèle aussi gros. Même avec le plus gros GPU du marché (H100 qui possède 80 giga de VRAM), il faut plusieurs GPU pour l'inférence et encore plus pour l'entraînement.
En pratique, on sait qu'un nombre supérieur de paramètres est correlé avec une meilleure performance. On ne veut donc pas diminuer la taille des modèles. Ce que l'on voudrait, c'est réduire l'espace mémoire que le modèle occupe.
Ce cours s'inspire fortement du blogpost et du blogpost. Les images utilisées sont également extraites de ces deux blogposts.
Comment représenter les nombres sur un ordinateur ?¶
Pour répresenter les nombres flottants sur un ordinateur, on utilise un certain nombre de bits. La norme IEEE_754 décrit comment les bits peuvent représenter un nombre. Cela se fait via 3 parties : le signe, l'exposant et la mantisse.
Voici un exemple de la répresentation FP16 (16 bits) :
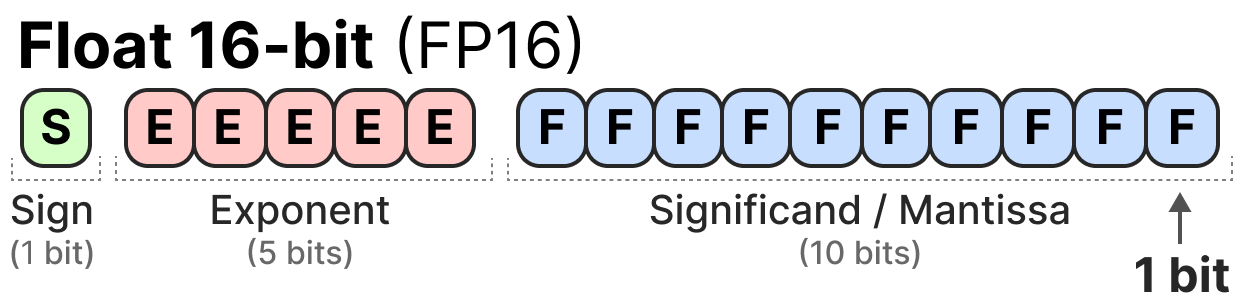
Le signe permet de déterminer * roulement de tambour * le signe du nombre, l'exposant va donner les chiffres avant la virgule et la mantisse les chiffres après la virgule. Voici un exemple en image de la manière de convertir la representation FP16 en chiffre.

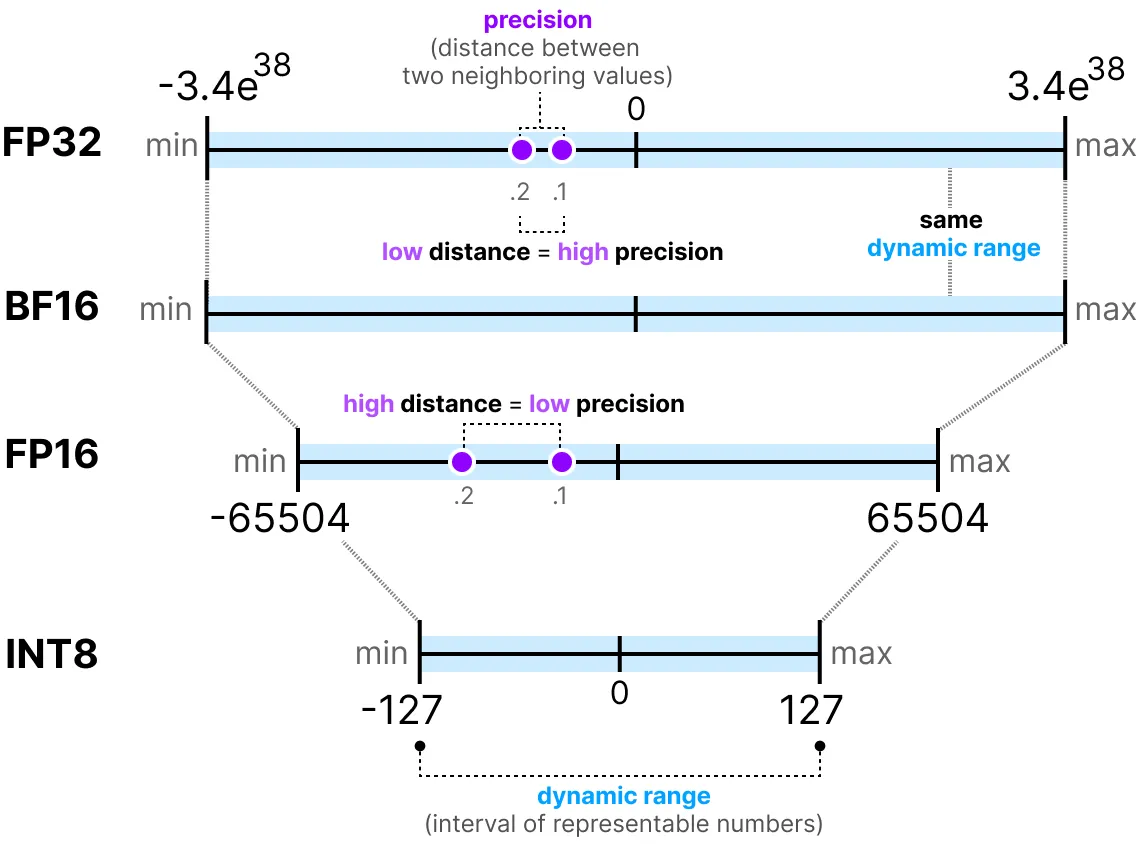
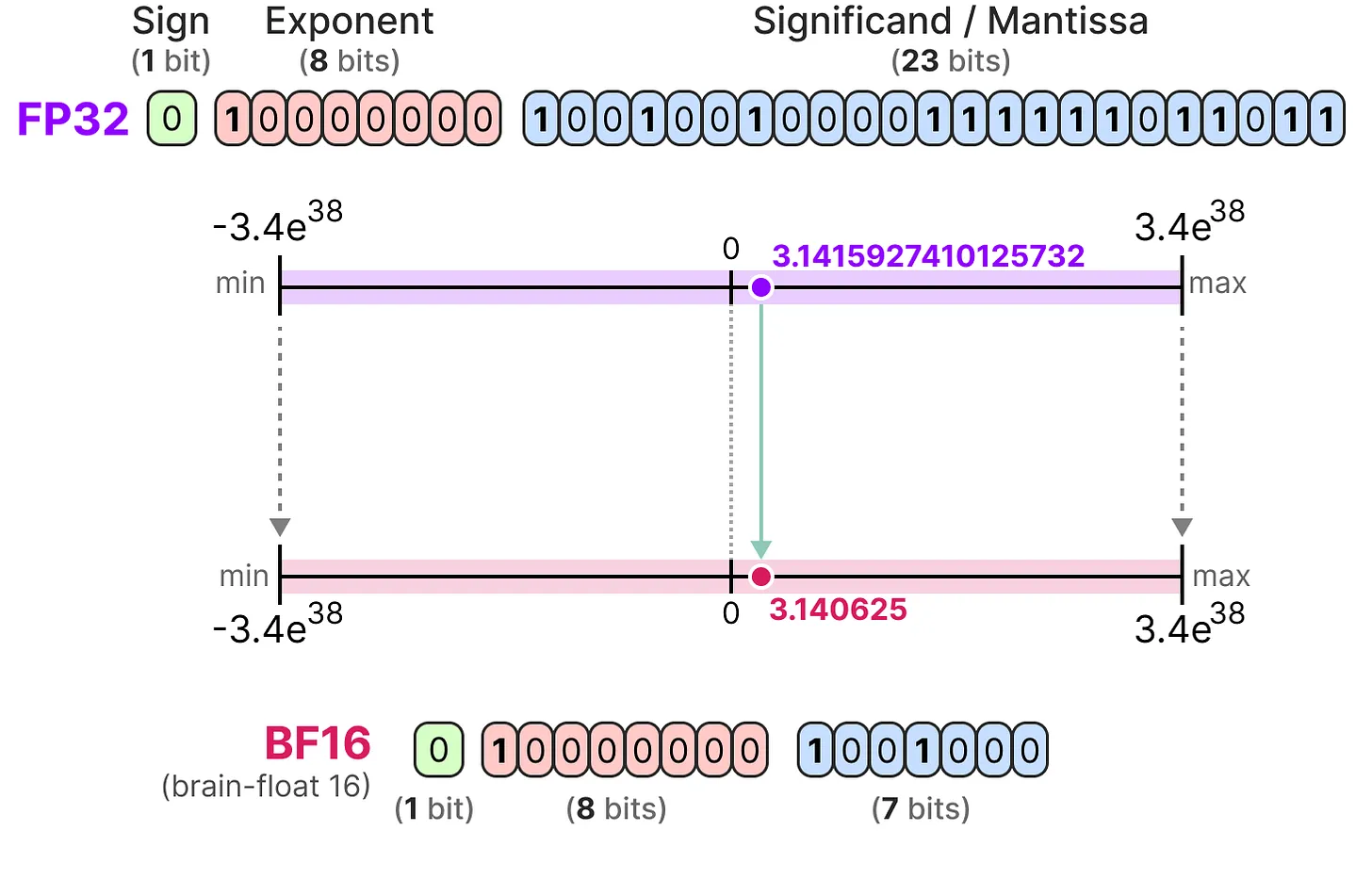
De manière générale, plus on utilise de bits pour representer une valeur, plus cette valeur peut être précise ou sur une grande plage de valeur. Par exemple, on peut comparer la précision FP16 et FP32 :

Une dernière chose importante à savoir. Il y a deux façon de juger une réprésentation. D'une part, la dynamic range qui donne la plage des valeurs que l'on peut représenter et la precision qui décrit l'écart entre deux valeurs voisines.
Plus l'exposant est important, plus la dynamic range est grande et plus la mantisse est importante, plus la precision est grande (donc 2 valeurs voisines sont proches).
En deep learning, on préfere souvent utiliser la répresentation BF16 au lieu de FP16. La représentation BF16 a un exposant plus important mais une précision plus faible.
La figure suivante illustre les différences :
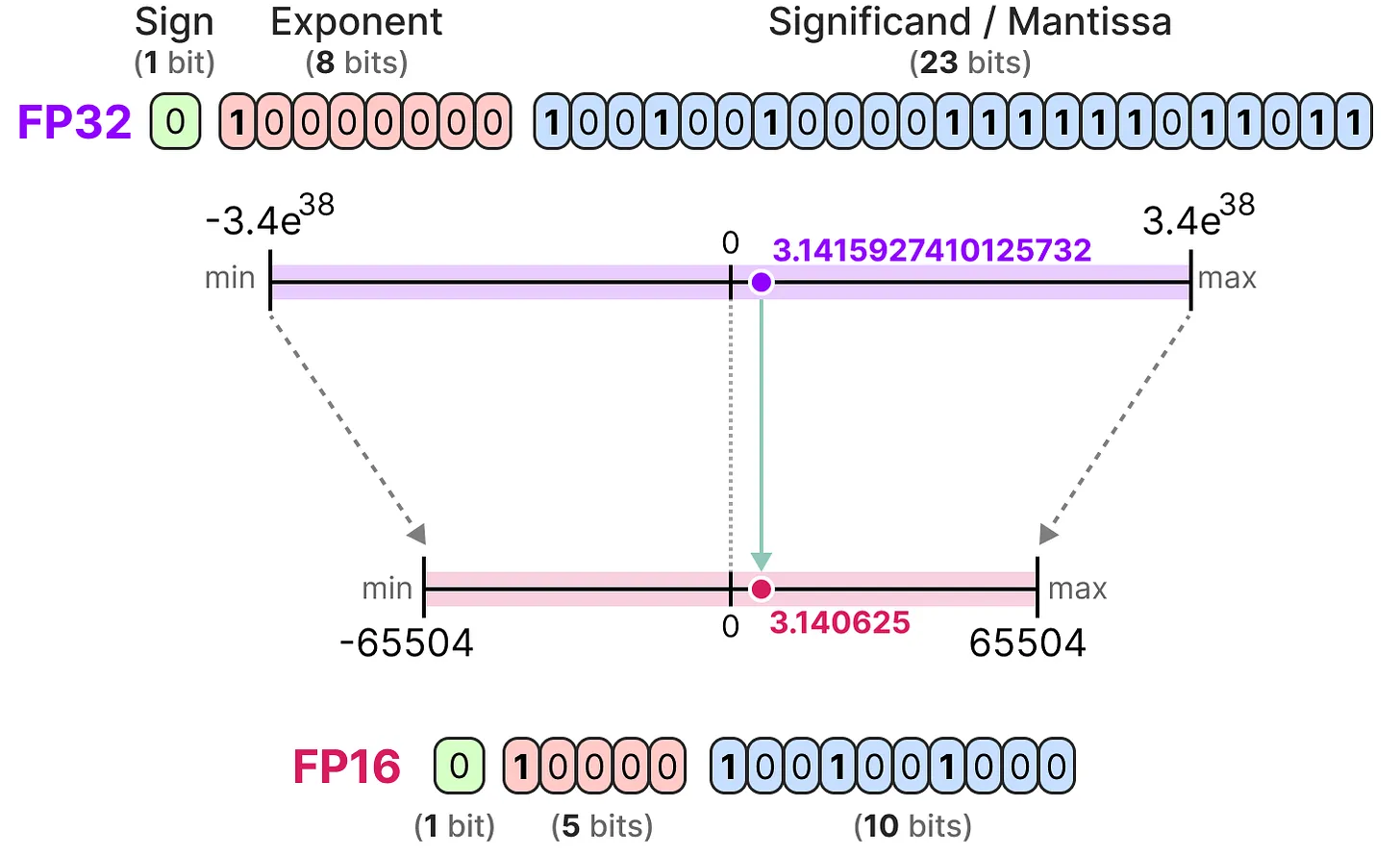
Maitenant que l'on comprend les notions de précision des nombres flottants, on peut calculer la place que prend un modèle en mémoire en fonction de la précision. En FP32, un nombre est représenté par 32 bits ce qui correspond à 4 octets (un octet vaut 8 bits pour rappel). Pour obtenir l'utilisation mémoire d'un modèle, on peut faire le calcul suivant :
$memory= \frac{n_{bits}}{8}*n_{params}$
Prenons l'exemple d'un modèle de 70 milliards de paramètres à plusieurs niveau de précision : double(FP64), full-precision(FP32) et half-precision(FP16).
Pour FP64 : $\frac{64}{8} \times 70B = 560GB$
Pour FP32 : $\frac{32}{8} \times 70B = 280GB$
Pour FP16 : $\frac{16}{8} \times 70B = 140GB$
On se rend bien compte que c'est nécessaire de trouver une manière de réduire la taille des modèles. Ici, même le modèle en half-precision occupe 140GB ce qui correspond à 2 GPU H100.
Note : Ici, on parle de la précision pour faire l'inférence. Pour l'entraînement, comme il faut garder les activations en mémoire pour la descente du gradient, on se retrouve avec beaucoup plus de paramètres (voir partie sur QLoRA plus loin dans le cours).
Introduction à la quantization¶
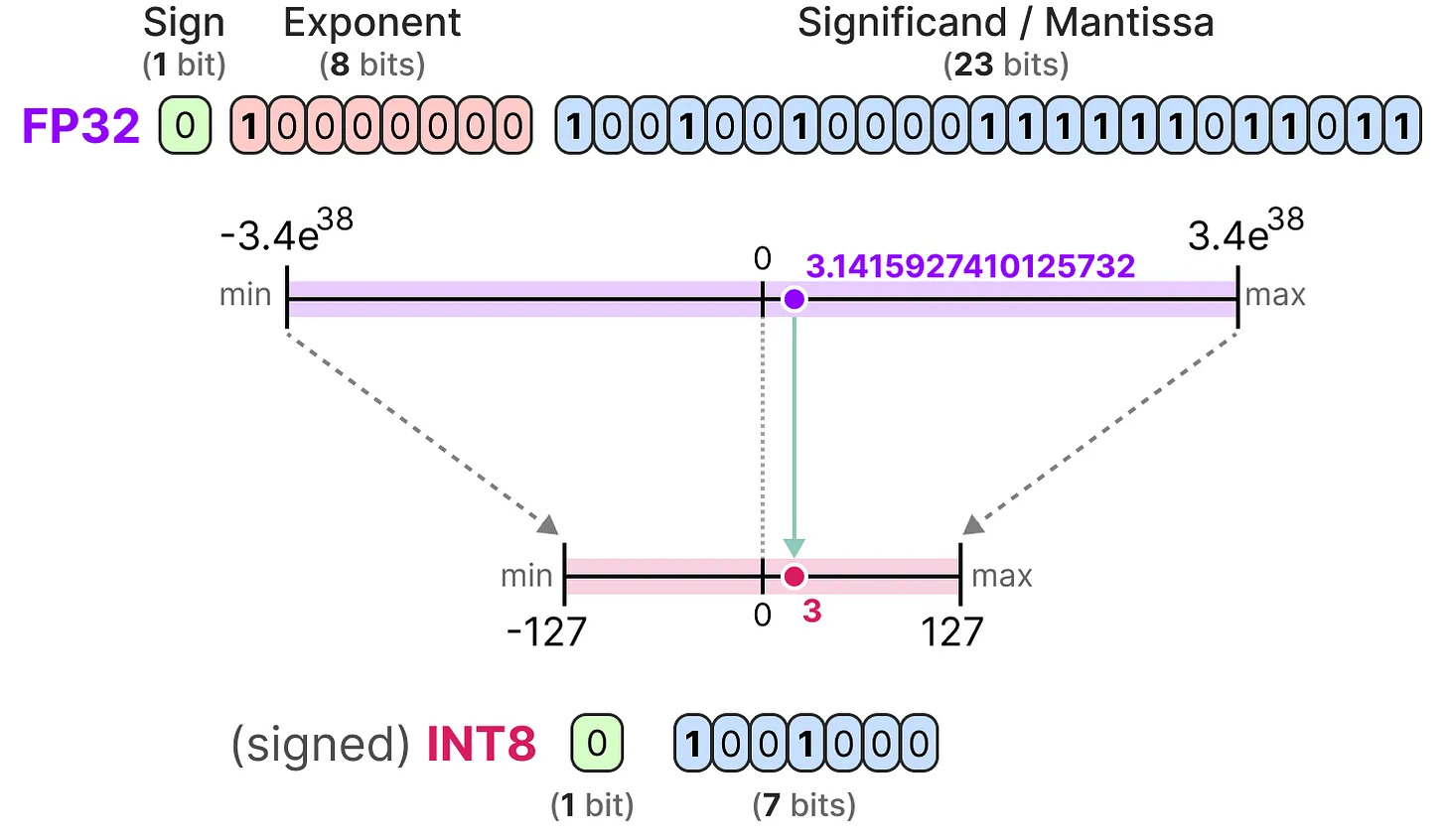
Le but de la quantization est de réduire la précision d'un modèle en passant d'une précision riche comme FP32 à une précision plus faible comme INT8.
Note : INT8 est la façon de représenter les entiers de -127 à 127 sur 8 bits.
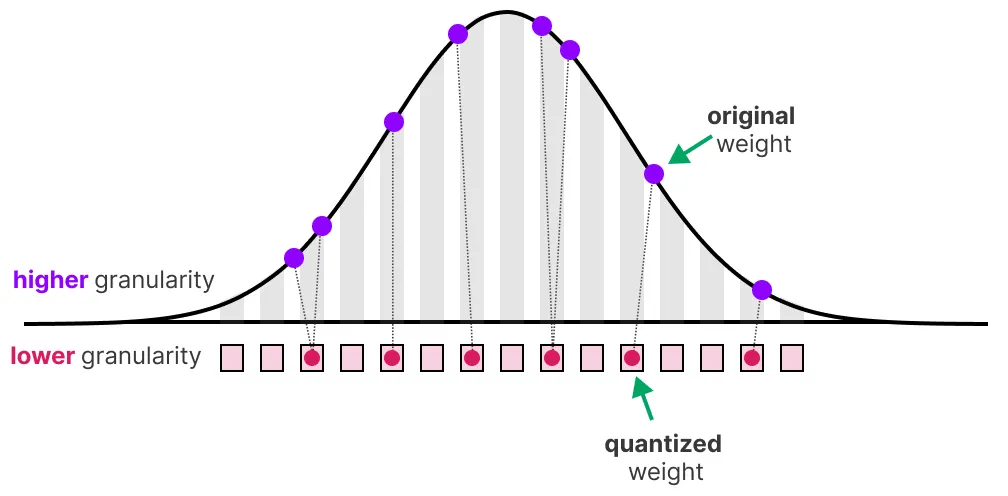
Bien sûr, en diminuant le nombre de bits pour représenter les valeurs, on a une perte de précision.
Pour illustrer cela, on peut regarder sur une image :

On remarque un "grain" dans l'image ce qui est dû à un manque de couleurs disponibles pour représenter l'image.
Ce que l'on voudrait, c'est réduire le nombre de bits pour représenter l'image en gardant au maximum la précision de l'image de base.
Il existe plusieurs manière de faire de la quantization : la quantization symétrique et la quantization asymétrique.
Point rapide sur les précisions communes¶
FP16 : La precision et la dynamic range diminuent par rapport à FP32.
BF16 : La precision diminue fortement mais la dynamic range reste la même par rapport à FP32.
INT8 : On passe à une représentation en entier.
Quantization symétrique¶
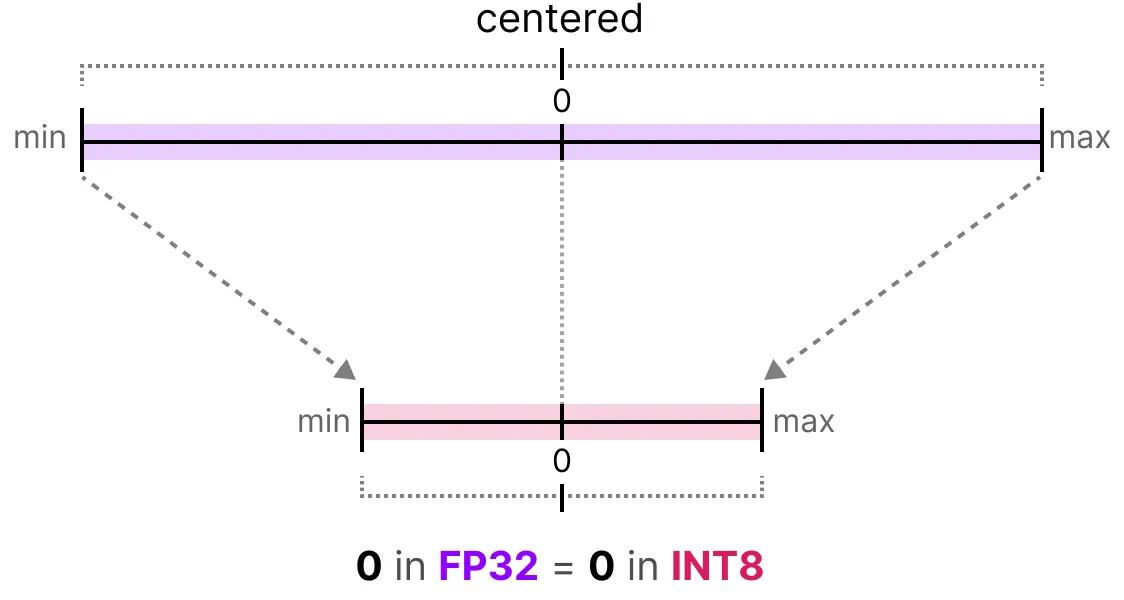
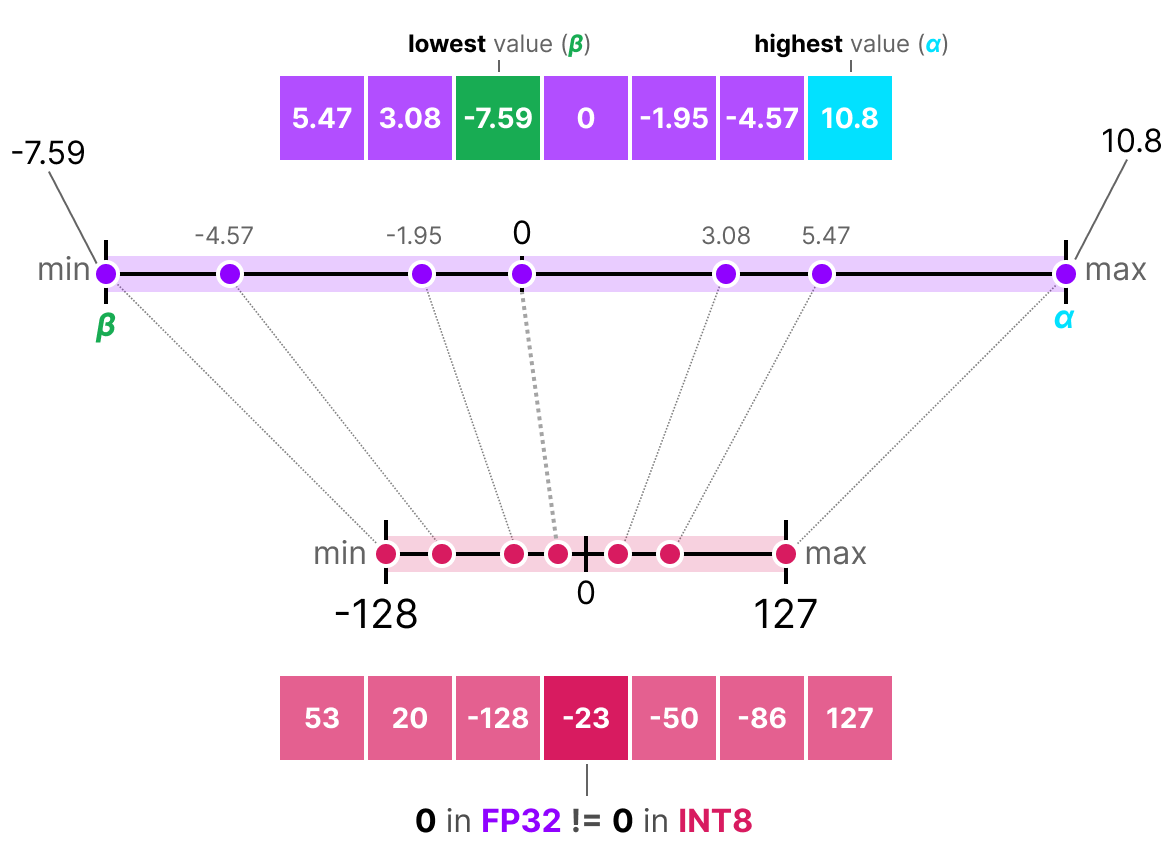
Dans le cas de la quantization symétrique, la plage de valeurs de nos flottants d'origine est mappé de manière symétrique sur la plage de valeur de quantization. C'est à dire que le 0 dans les flottants est mappé sur le 0 dans la précision de quantization.
Une des manières la plus commune et également la plus simple de réaliser cette opération est d'utiliser la méthode absmax (absolute maximum quantization). On prend la valeur maximale (en valeur absolue) et on réalise le mapping par rapport à cette valeur :
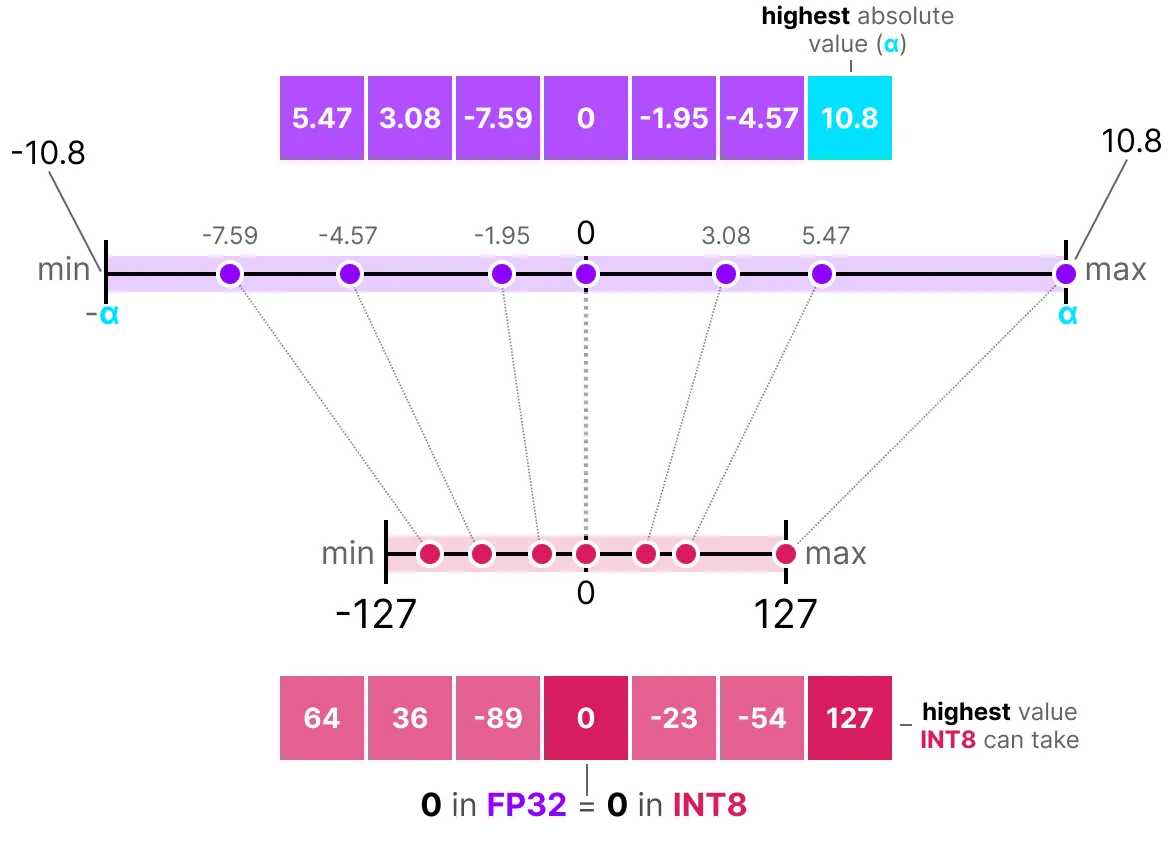
La formule est assez basique : Considérons $b$ le nombre d'octets que l'on veut quantize, $\alpha$ la plus grande valeur absolue.
Alors on peut calculer le scale factor de la manière suivante :
$s=\frac{2^{b-1}-1}{\alpha}$
On peut alors effectuer la quantization de $x$ comme ceci :
$x_{quantized}=round(s \times x)$
Pour déquantizer et retrouver une valeur FP32, on peut faire comme cela :
$x_{dequantized}=\frac{x_{quantized}}{s}$
Bien entendu, la valeur dequantizé ne sera pas équivalente à la valeur avant quantization :
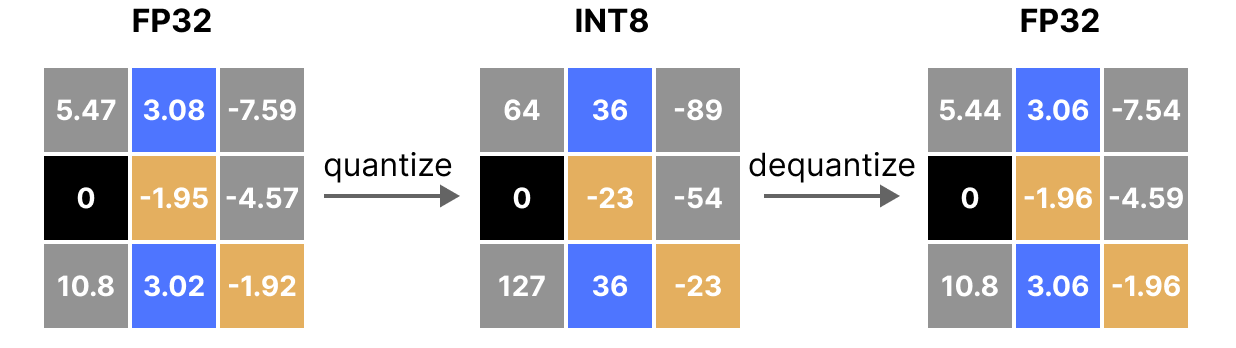
et on peut quantifier les erreurs de quantization :
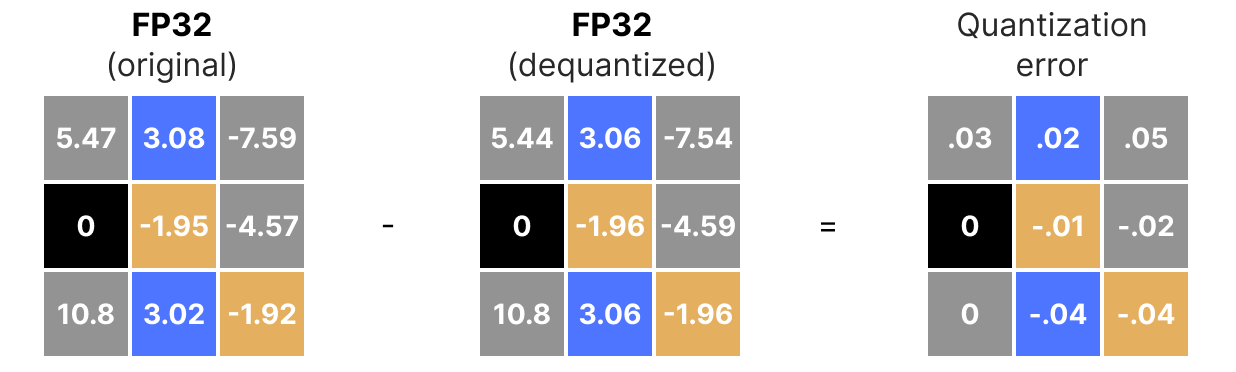
Quantization asymétrique¶
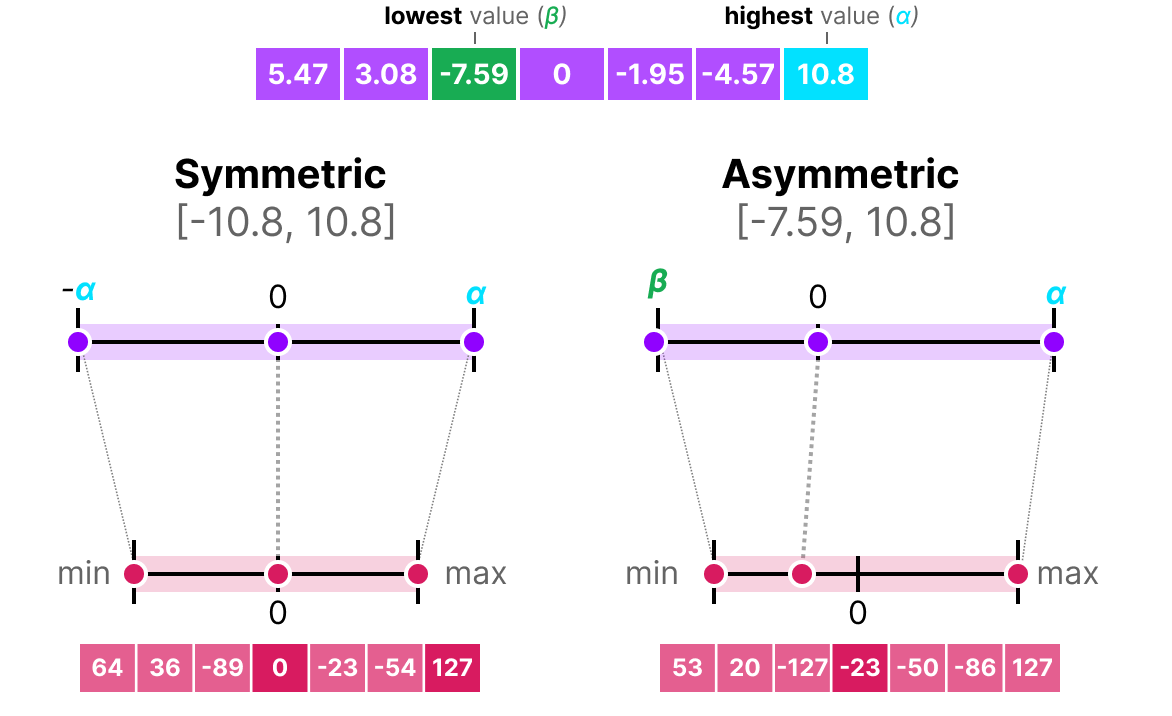
A l'inverse de la quantization symétrique, la quantization asymétrique n'est pas symétrique autour de 0. Au lieu de ça, on map le minimum $\beta$ et le maximum $\alpha$ de la range des flottants d'origine sur le minimum et le maximum de la range quantizé.
La méthode la plus commune pour cela est appelé zero-point quantization.
Avec cette méthode, le 0 a changé de position et c'est pourquoi cette méthode est appelé asymétrique.
Comme le 0 a été deplacé, on a besoin de calculer la position du 0 (zero-point) pour effectuer le mapping linéaire.
On peut quantizer de la manière suivante :
$s=\frac{128 - - 127}{\alpha- \beta}$
On calcule le zero-point :
$z=round(-s \times \beta)-2^{b-1}$
et :
$x_{quantized}=round(s \times x + z)$
Pour déquantizer, on peut alors appliquer la formule suivante :
$x_{dequantized}=\frac{x_{quantized}-z}{s}$
Les deux méthodes ont leurs avantages et inconvénients, on peut les comparer en regardant le comportement sur un $x$ quelconque :
Clipping et modification de range¶
Les méthodes que nous avons présenté présentent un défaut majeur. Ces méthodes ne sont pas du tout robustes aux outliers. Imaginons que notre vecteur $x$ contient les valeurs suivante : [-0.59, -0.21, -0.07, 0.13, 0.28, 0.57, 256]. Si l'on fait notre mapping habituel, on va obtenir des valeurs identiques pour tous les éléments sauf l'outlier (256) :
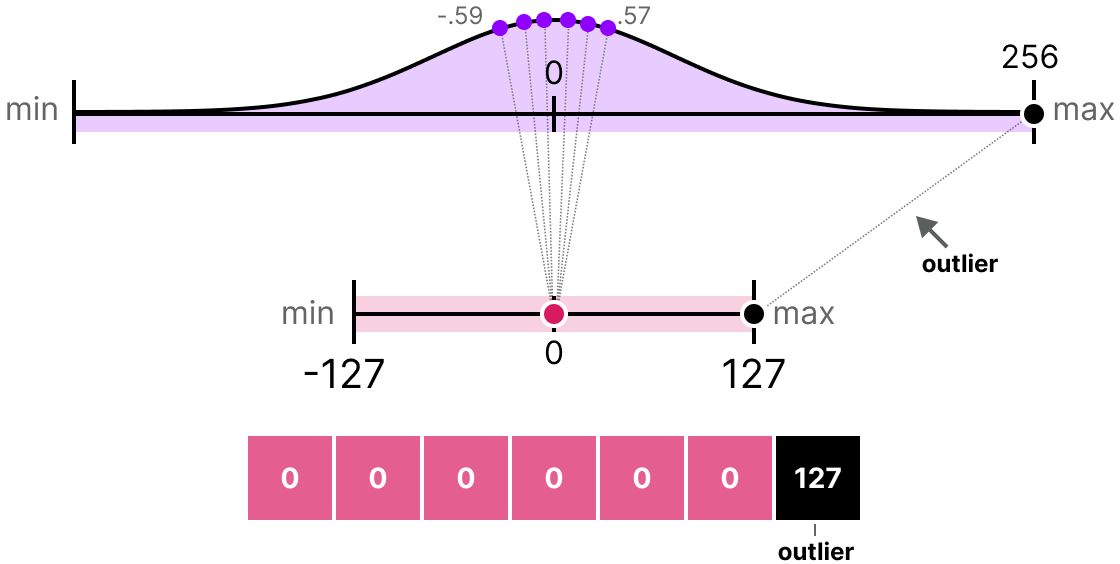
C'est très problématique car la perte d'information est colossale.
En pratique, on peut décider de clip certaines valeurs pour diminuer la range dans l'espace des flottants (avant d'appliquer la quantization). Par exemple, on pourrait décider de limiter les valeurs dans la plage [-5,5] et toutes les valeurs en dehors de cette plage seront mappé aux valeurs maximales ou minimales de quantization (127 ou -127 pour INT8) :
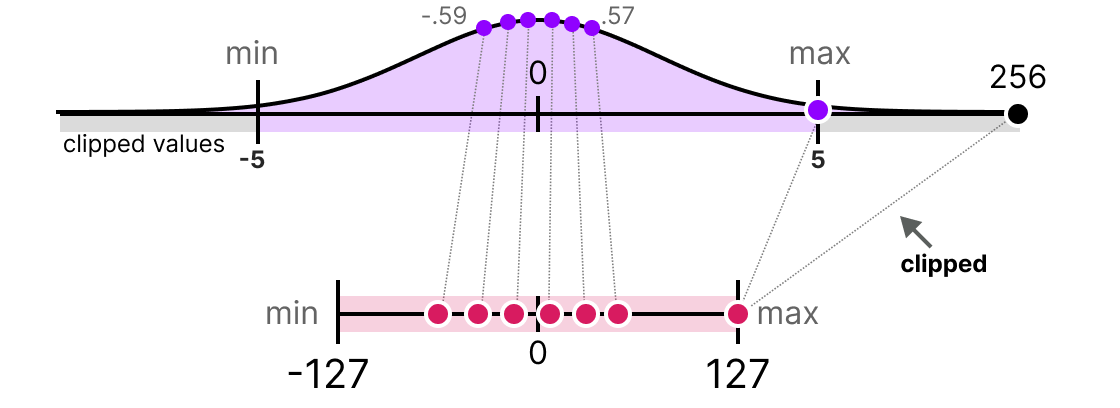
En faisant cela, on diminue grandement l'erreur sur les non-outliers mais on l'augmente pour les outliers (ce qui peut également être problématique).
Calibration¶
Dans la partie précédente, on a utilisé arbitrairement une plage de valeur de [-5,5]. La sélection de cette plage de valeur n'est pas aléatoire et est determinée par une méthode que l'on appelle calibration. L'idée est de trouver une plage de valeur qui minimise l'erreur l'erreur de quantization pour l'ensemble des valeurs. Les méthodes de calibration utilisées sont différentes selon le type de paramètres que l'on cherche à quantizer.
Calibration pour les poids et les biais :
Les poids et les biais sont des valeurs statiques (fixes après l'entraînement du modèle). Ce sont des valeurs que l'on connait avant de faire l'inférence.
Souvent, comme il y a beaucoup plus de poids que de biais, on va conserver la précision de base sur les biais et effectuer la quantization uniquement sur les poids.
Pour les poids, il y a plusieurs méthodes de calibration possibles :
- On peut choisir manuellement un pourçentage de la plage d'entrée
- On peut optimiser la distance MSE entre les poids de base et les poids quantizés
- On peut minimiser l'entropie (avec le KL-divergence) entre les poids de base et les poids quantizés
La méthode avec pourçentage est similaire à la méthode que nous avons utilisé précedemment. Les deux autres méthodes sont plus rigoureuses et efficaces.
Calibration pour les activations :
A l'inverse des poids et des biais, les activations sont dépendantes de la valeur d'entrée du modèle. Il est donc très compliqué de les quantizer efficacement. Ces valeurs sont mises à jour après chaque couche et on peut connaître leurs valeurs uniquement pendant l'inférence lorsque la couche du modèle traite les valeurs.
Cela nous amène à la partie suivante qui traite de deux méthodes différentes pour la quantization des activations (et également des poids).
Ces méthodes sont :
- La post-training quantization (PTQ) : la quantization intervient après l'entraînement du modèle
- La quantization aware training (QAT) : la quantization se fait pendant l'entraînement ou le fine-tuning du modèle.
Post-Training Quantization (PTQ)¶
Une des manières les plus fréquentes de faire de la quantization est de le faire après l'entraînement du modèle. D'un point de vue pratique, c'est assez logique car cela ne nécessite pas d'entraîner ou de fine-tune le modèle.
La quantization des poids est effectuée en utilisant soit la quantization symétrique ou asymétrique.
Pour les activations, ce n'est pas pareil puisqu'on ne connait pas la plage de valeurs prises par la distribution des activations.
On a deux formes de quantization pour les activations :
- La dynamic quantization
- La static quantization
Dynamic quantization¶
Dans la quantization dynamique, on collecte les activations après que la donnée soit passée dans une couche. La distribution de la couche est ensuite quantizé en calculant le zeropoint et le scale factor.
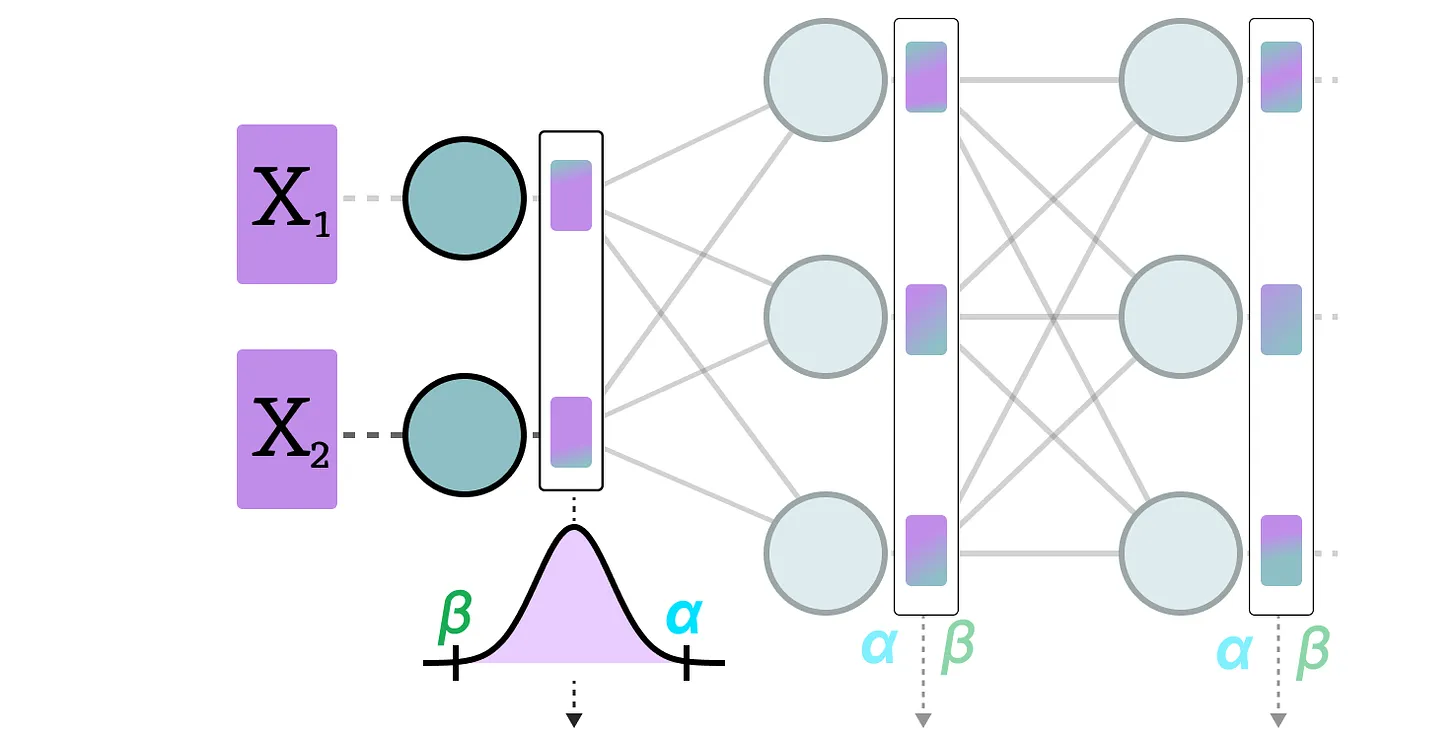
Dans ce processus, chaque couche ses propres valeurs de zeropoint et de scale factor et donc la quantization n'est pas la même.
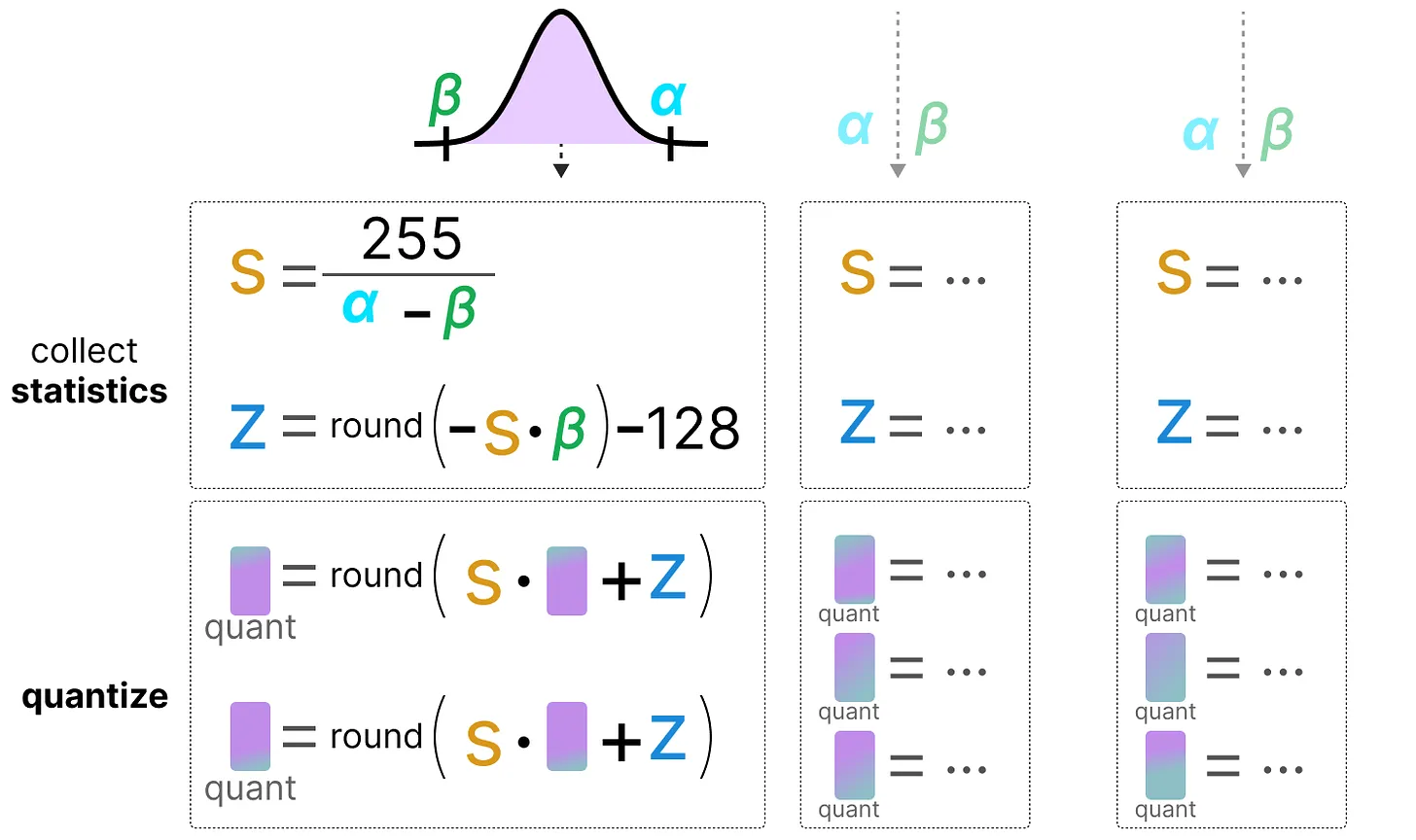
Note : Ce processus de quantization a lieu pendant l'inférence.
Static quantization¶
A l'inverse de la dynamic quantization, la static quantization ne calcule pas le zeropoint et le scale factor pendant l'inférence. En effet, dans la méthode de static quantization, les valeurs de zeropoint et scale factor sont calculés avant l'inférence à l'aide d'un dataset de calibration. Ce dataset est supposé être representatif des données et permet de calculer les distributions potentiels prises par les activations.
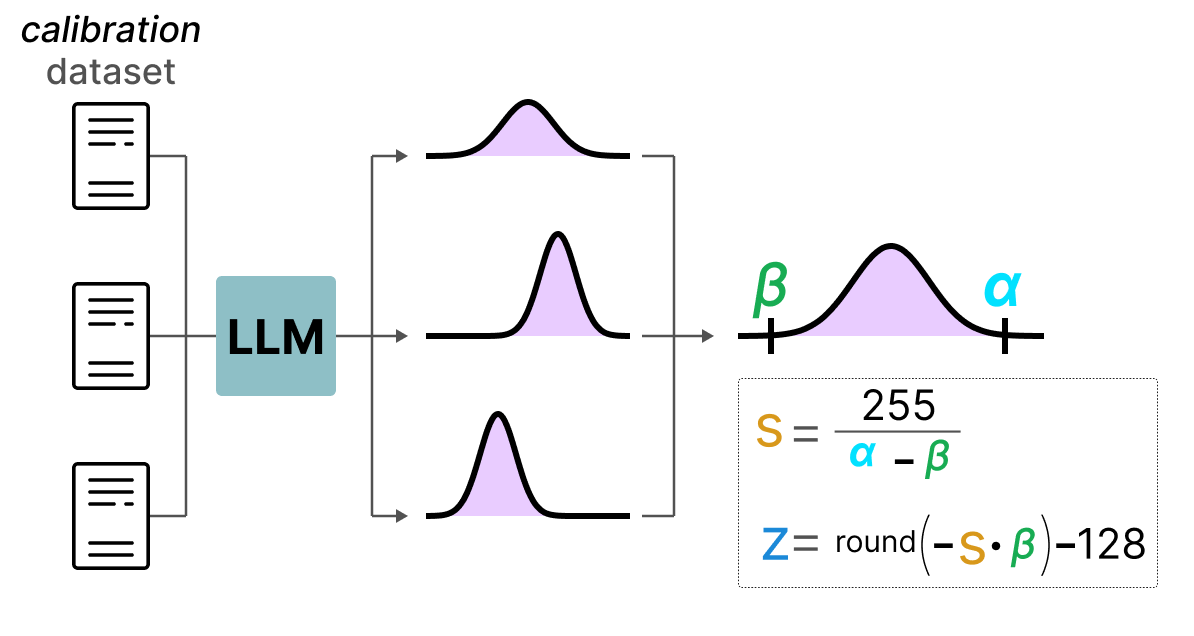
Après avoir collecté les valeurs des activations sur l'ensemble du dataset de calibration, on peut les utiliser pour calculer le scale factor et le zeropoint qui seront ensuite utilisé pour toutes les activations.
Différence entre dynamic et static quantization¶
En général, la dynamic quantization est un peu plus précise car elle calcule les valeurs de scale factor et de zeropoint pour chaque couche mais ce processus a également tendance à ralentir le temps d'inférence.
A l'inverse, la static quantization est moins précise mais plus rapide.
PTQ : la quantization en 4-bit¶
Dans l'idéal, on aimerait pousser la quantization au maximum, c'est-à-dire 4 bits au lieu de 8 bits. En pratique, ce n'est pas facile car cela augmente drastiquement l'erreur si l'on emploie simplement les méthodes que l'on a vu jusqu'à présent.
Il y a cependant quelques méthodes permettant de réduire le nombre de bits jusqu'à 2 bits (il est recommandé de rester à 4 bits).
Parmi ces méthodes, on en retrouve deux principales :
- GPTQ (utilise seulement le GPU)
- GGUF (peut également utilisé le CPU en partie)
GPTQ¶
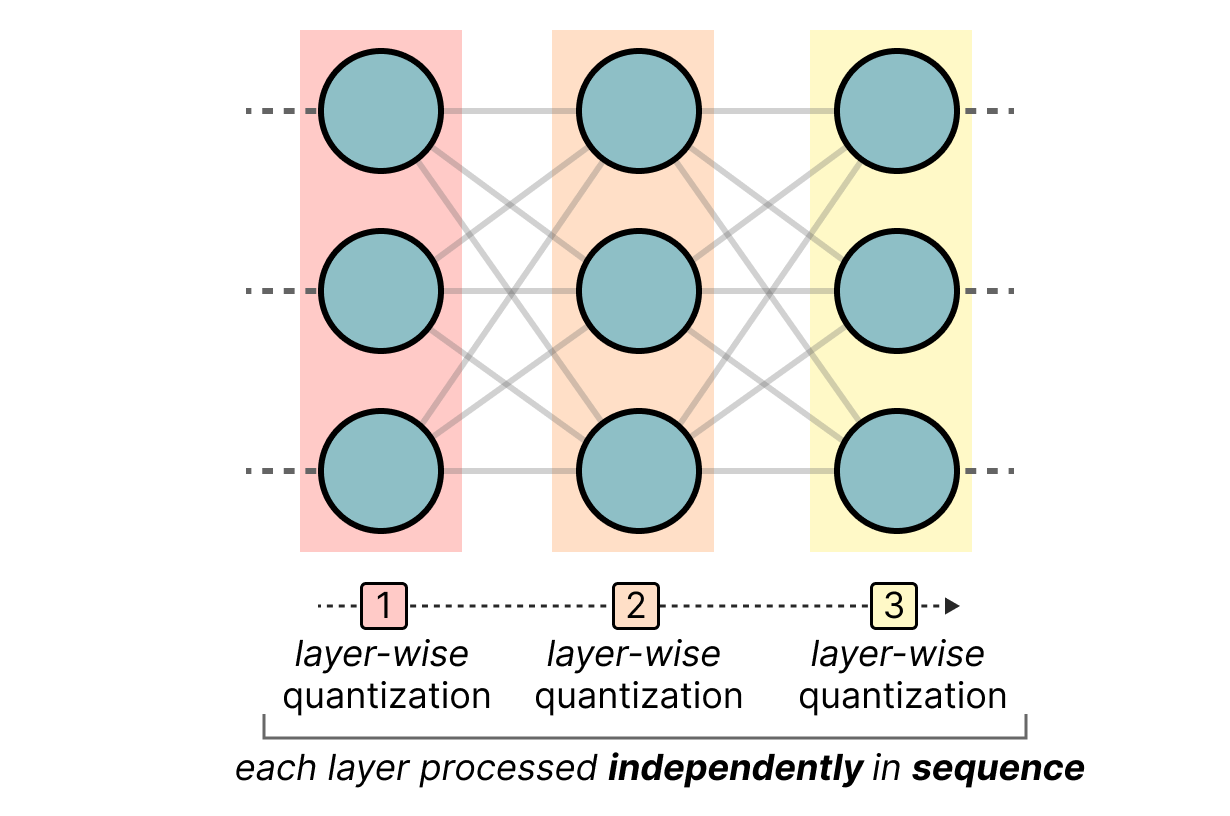
GPTQ est probablement la méthode la plus utilisée pour la quantization 4-bits. L'idée est d'utiliser la quantization asymétrique sur chaque couche indépendamment :
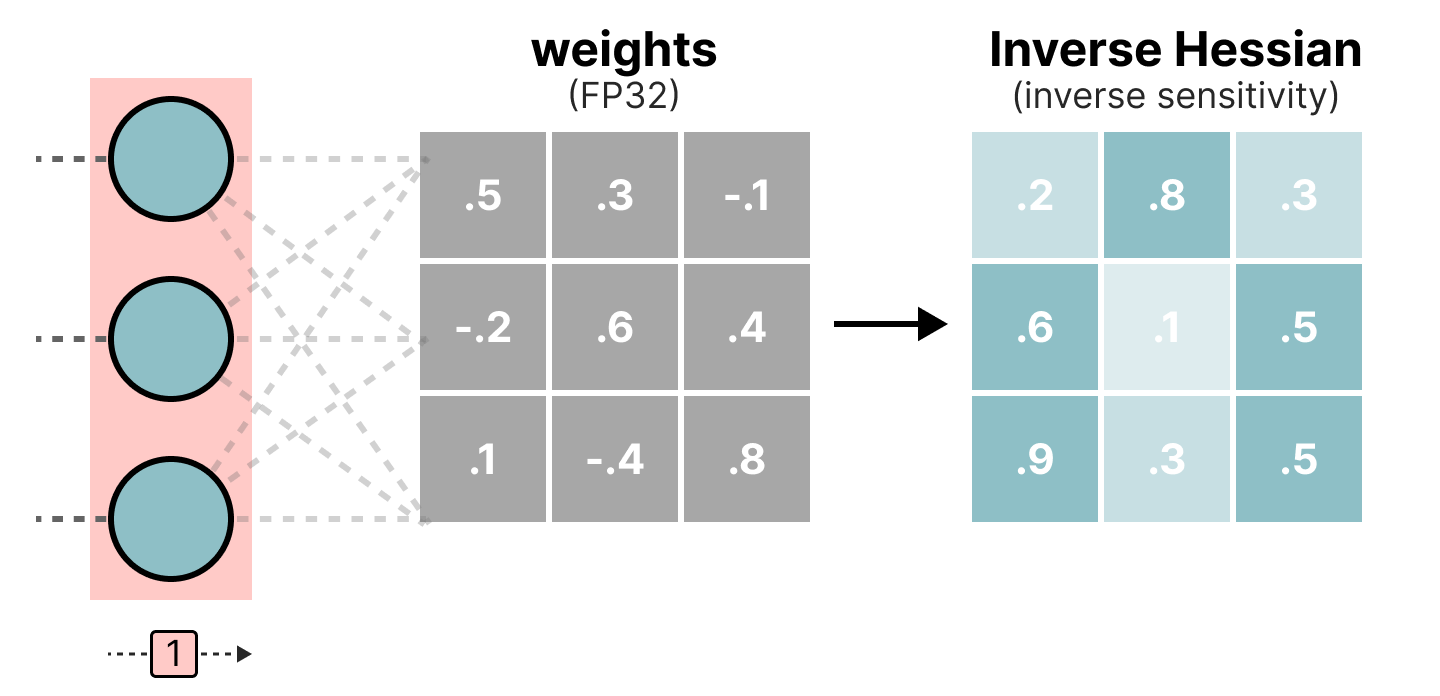
Pendant le processus de quantization, les poids sont convertis en l'inverse de la matrice Hessian (dérivée seconde de la fonction de loss) ce qui nous permet de savoir si la sortie du modèle est sensible aux changements de chaque poids. De manière simplifié, cela permet de calculer l'importance de chaque poids dans une couche. Les poids associés à de petites valeurs dans la Hessian sont les plus importants car un changement de ces poids va affecter le modèle significativement.
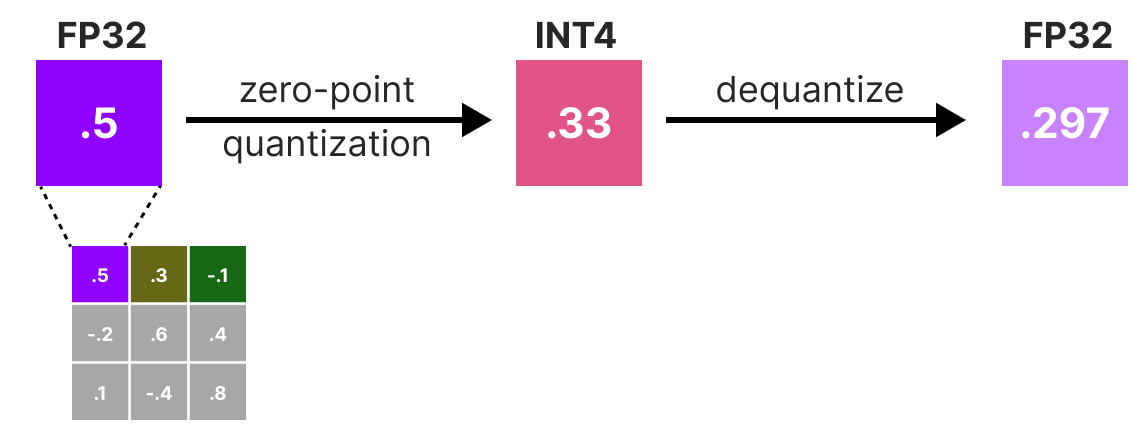
On va ensuite quantizer puis dequantizer les poids pour obtenir notre quantization error. Cette erreur nous permet pondérer l'erreur de quantization par rapport à la vraie erreur et à la matrice Hessian.
L'erreur pondérée est calculée comme ceci :
$q=\frac{x_1-y_1}{h_1}$ où $x_1$ est la valeur avant quantization, $y_1$ est la valeur après quantization/dequantization et $h_1$ est la valeur correspondante dans la matrice Hessian.
Ensuite, nous redistribuons cette erreur de quantification pondérée sur les autres poids de la ligne. Cela permet de maintenir la fonction globale et la sortie du réseau. Par exemple, pour $x_2$:
$x_2=x_2 + q \times h_2$
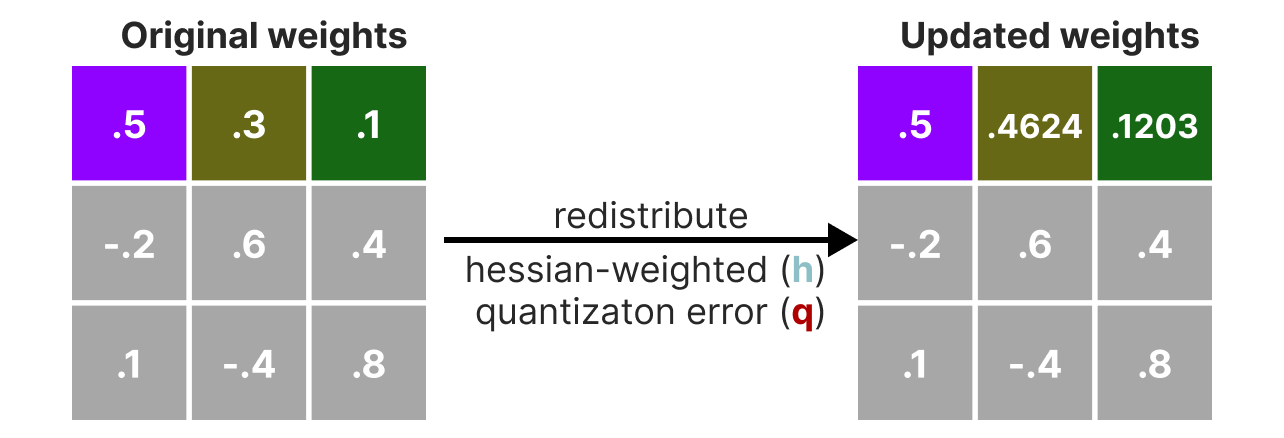
On fait ce process jusqu'à ce que toutes les valeurs soient quantizés.
En pratique, cette méthode marche bien car tous les poids sont corrélés les uns avec les autres donc si un poids a une grosse erreur de quantization, les autres poids sont changés pour compenser l'erreur (en se basant sur la Hessian).
GGUF¶
GPTQ est une très bonne méthode pour faire tourner un LLM sur un GPU. Cependant, même avec cette quantization, on a parfois pas assez de mémoire GPU pour faire tourner un modèle LLM profond. La méthode GGUF permet de déplacer n'importe quelle couche du LLM sur le CPU.
De cette manière, on peut utiliser la mémoire vive et la mémoire vidéo (vram) en même temps.
Cette méthode de quantization est changée fréquemment et dépend du niveau de bit quantization que l'on souhaite.
De manière générale, la méthode fonctionne de la manière suivante :
D'abord, les poids d'une couche sont divisés en super block où chaque super block est à nouveau divisé en sub blocks. On va ensuite extraire les valeurs $s$ et $\alpha$ (absmax) pour chaque block (le super et les sub).
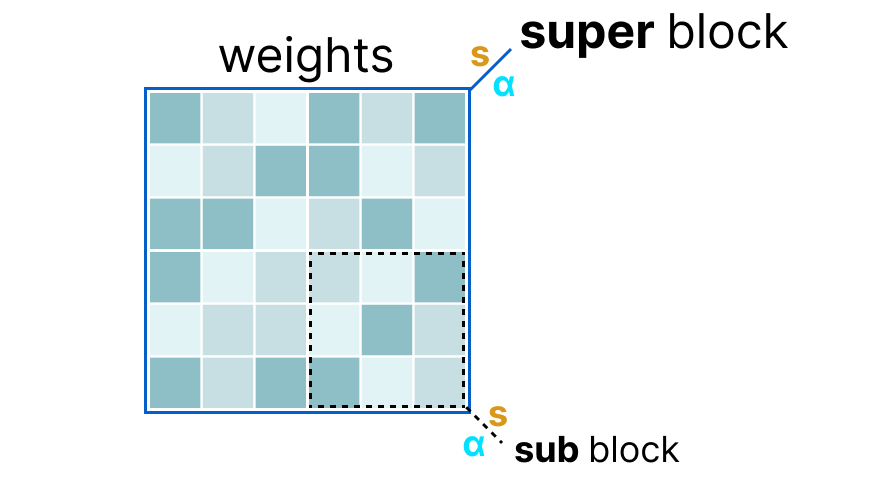
Les scales factor $s$ des sub block sont ensuite quantizé à nouveau en utilisant l'information du super block (qui a son propre scale factor). Cette méthode est appelée block-wise quantization.
Note : De manière générale, le niveau de quantization est différent entre les sub block et le super block : le super block a une précision supérieure aux sub block le plus souvent.
Quantization Aware Training (QAT)¶
Au lieu d'effectuer la quantization après l'entraînement, on peut le faire pendant l'entraînement. En effet, faire la quantization après l'entraînement ne tient pas compte du procédé d'entraînement ce qui peut poser des problèmes.
La quantization aware training est une méthode permettant d'effectuer la quantization pendant l'entraînement et d'apprendre les différents paramètres de quantization pendant la rétropropagation :
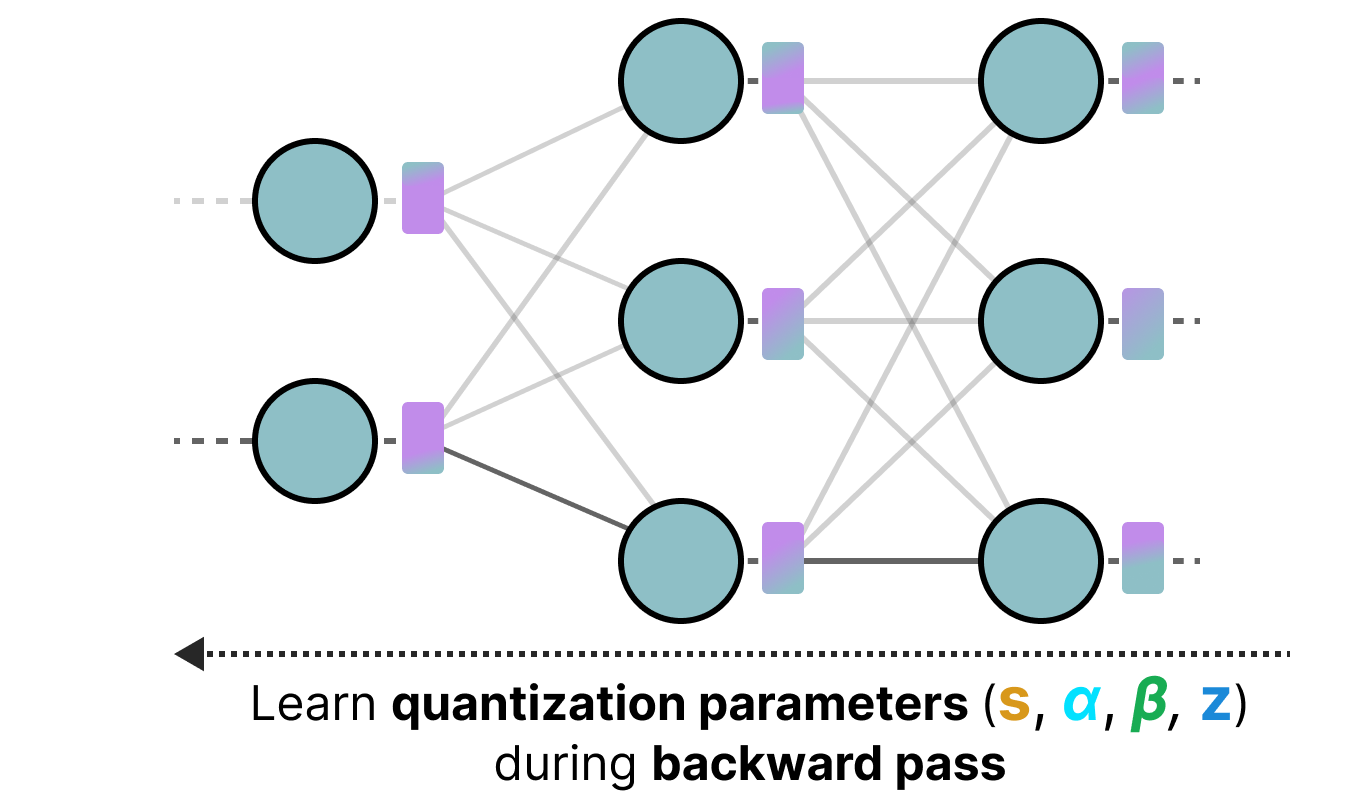
En pratique, cette méthode est souvent plus précise que la PTQ parce que la quantization est déjà prévue lors de l'entrainement et on peut donc adapter le modèle spécifiquement dans un objectif futur de quantization.
Cette approche fonctionne de la manière suivante :
Pendant l'entraînement, un processus de quantization/dequantization (fake quantization) est introduit (quantize de 32 bits à 4 bits puis dequantize de 4 bits à 32 bits par exemple).

Cette approche permet au modèle de considérer la quantization pendant l'entraînement et donc d'adapter la mise à jours de poids pour favoriser des bons résultats du modèle quantizé.
Une façon de voir les choses est d'imaginer que le modèle va converger vers des minimums larges qui minimize l'erreur de quantization plutôt que des minimuns étroits qui pourraient provoquer des erreurs lors de la quantization. Pour un modèle entraîné sans fake quantization, il n'y aurait pas de préférences sur le minimum choisi pour la convergence :
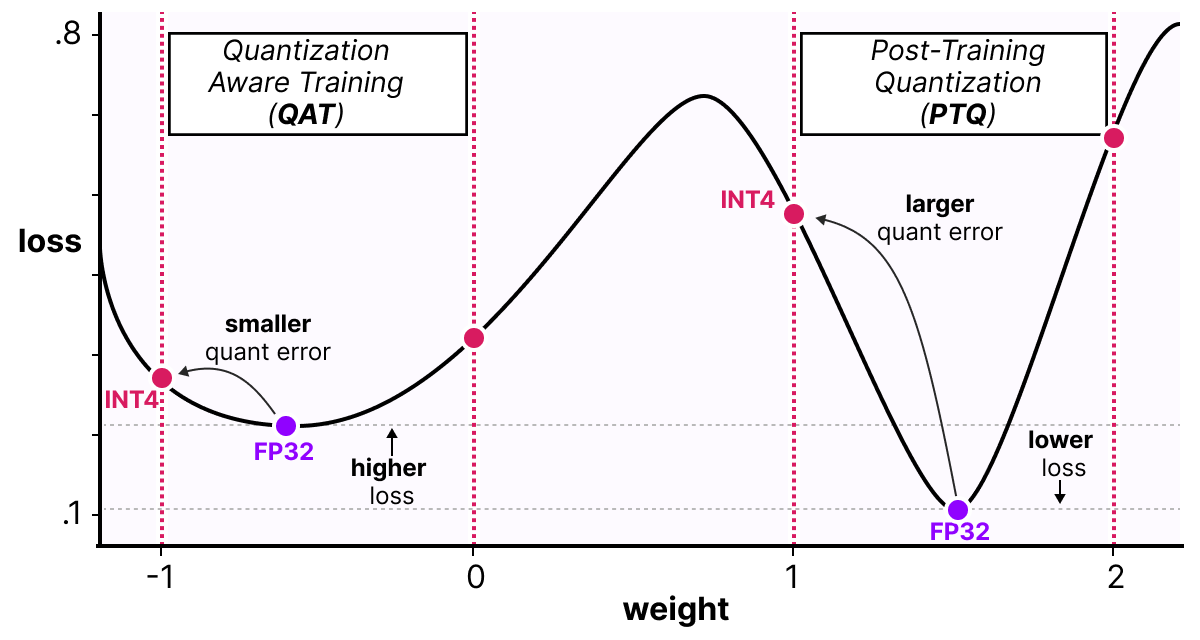
En pratique, les modèles entrainé de manière classique ont un loss plus faible que les modèle entraîné en QAT lorsque la précision est grande (FP32) mais dès lors que l'on quantize le modèle, le modèle QAT sera bien plus performant qu'un modèle quantizé via une méthode PTQ.
BitNet : quantization 1-bit¶
L'idéal pour réduire la taille d'un modèle serait de quantité en 1 seul bit. Cela parait fou, comment peut-on imaginer représenter un réseau de neurones avec uniquement est 0 et des 1 pour chaque poids.
BitNet propose de representer les poids d'un modèle avec un seul bit en utilisant la valeur -1 ou 1 pour un poids. Il faut imaginer que l'on remplace les couches linéaires de l'architecture transformers par des couches BitLinear :
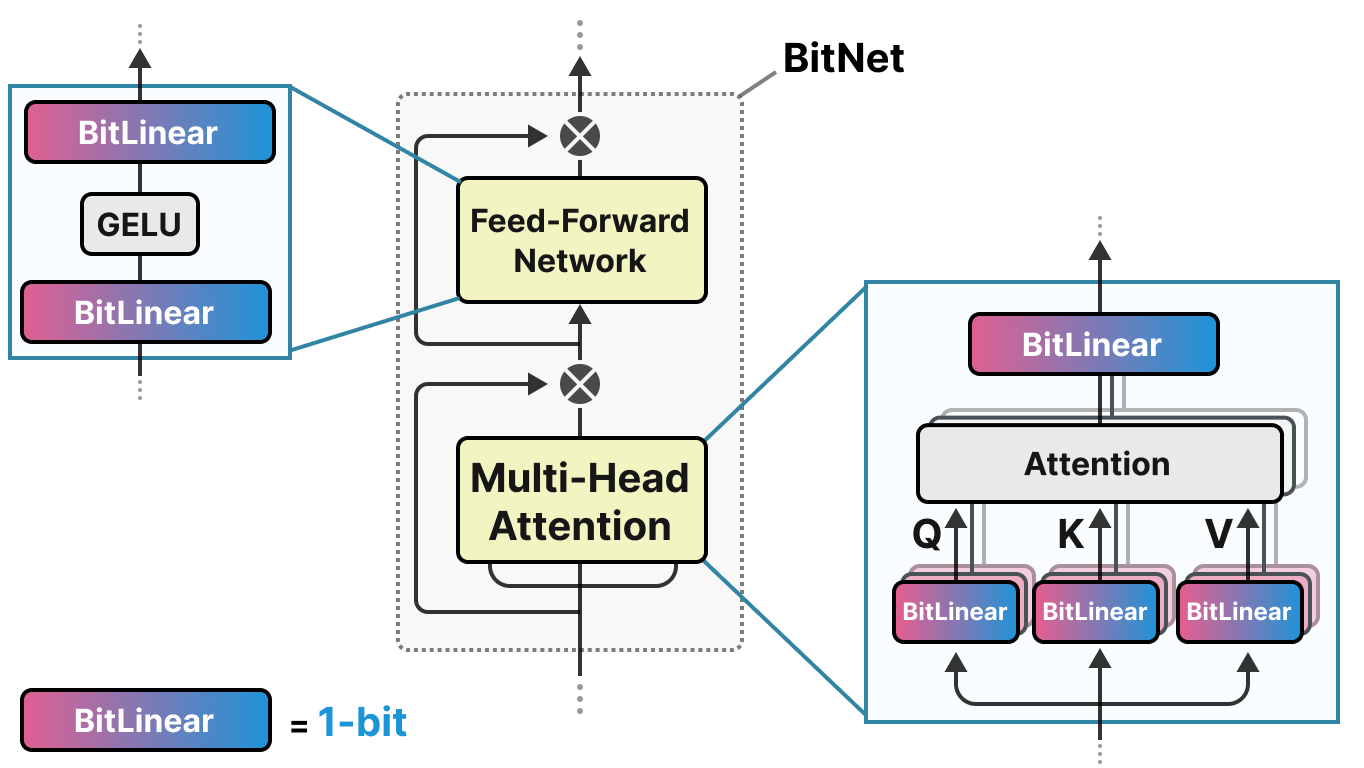
La couche BitLinear marche exactement comme une couche linéaire de base sauf que les poids sont représenté avec un unique bit et les activations en INT8.
Comme expliqué précedemment, il y a une forme de fake quantization permettant d'apprendre au modèle l'effet de la quantization pour le forcer à s'adapter à cette nouvelle contrainte :
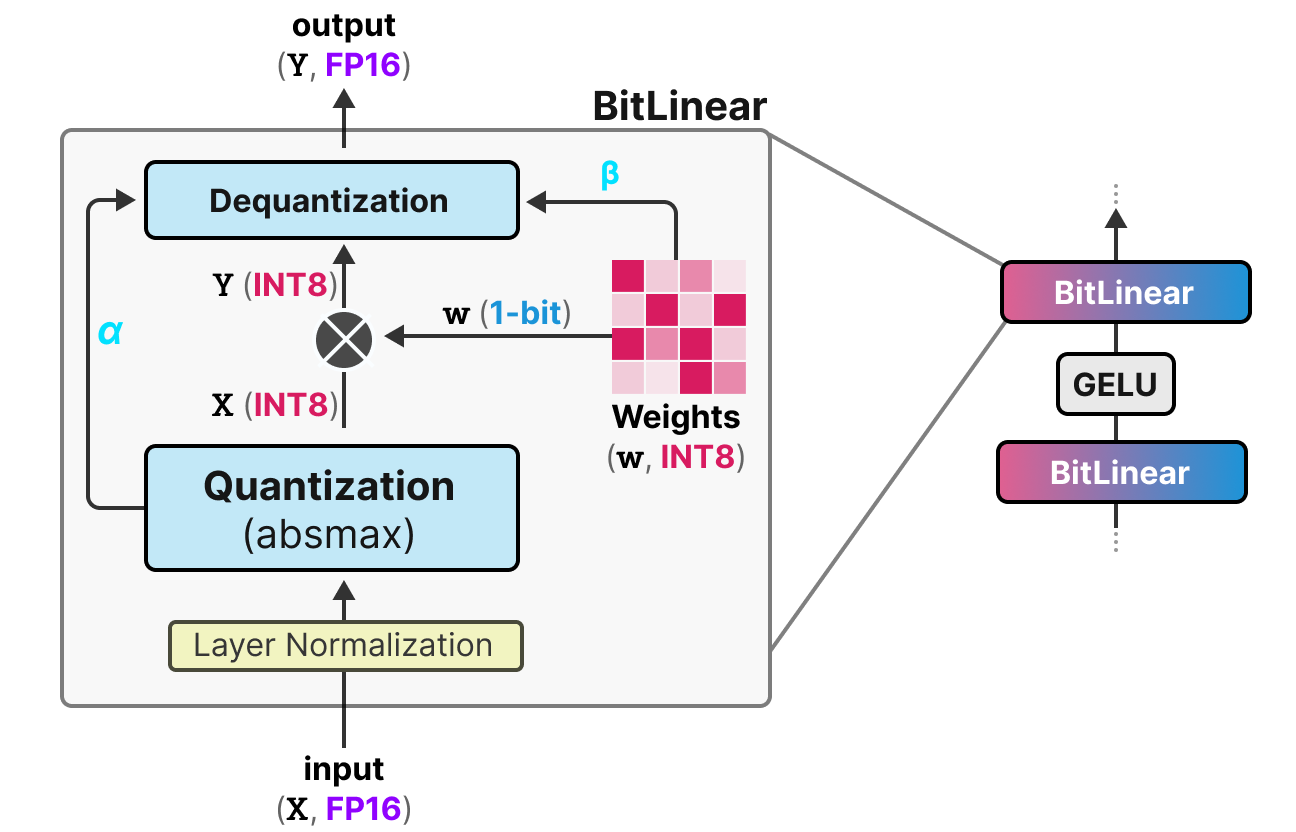
Analysons cette couche étape par etape :
Première Etape : Quantization des poids
Pendant l'entraînement, les poids sont stockés en INT8 et quantizé en 1-bit en utilisant la fonction signum.
Cette fonction permet simplement de centrer la distribution des poids en 0 et convertit tout ce qui est inférieur à 0 en -1 et tout ce qui est supérieur à 0 en 1.
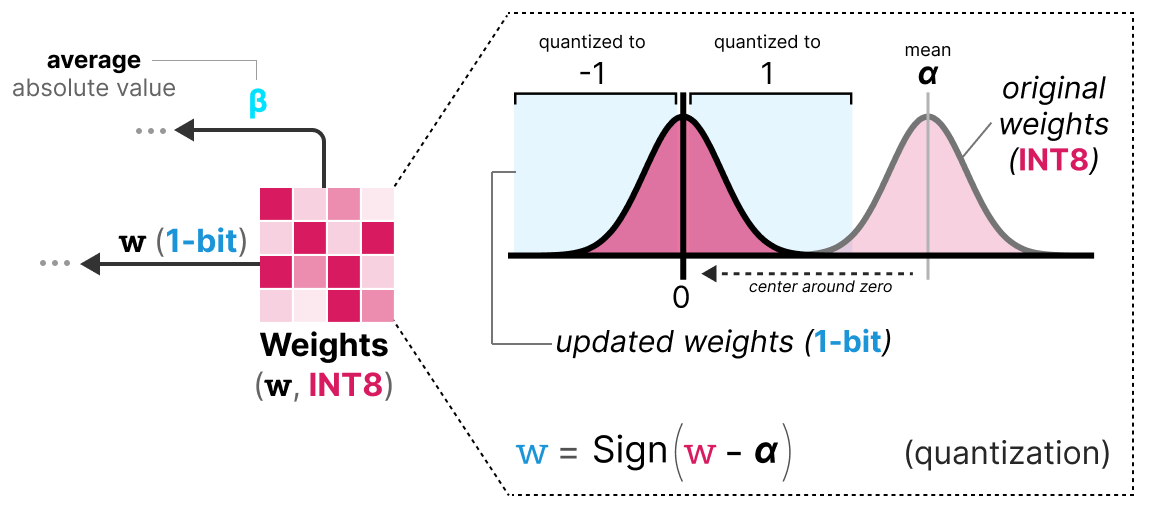
Une valeur $\beta$ (valeur moyenne absolue) est également extraite pour le processus de déquantization.
Deuxième Etape : Quantization des activation
Pour les activations, la couche BitLinear utilise la quantization absmax pour convertir de FP16 à INT8 et une valeur $\alpha$ (valeur maximum absolue) est stockée pour la déquantization.
Troisième Etape : Dequantization
A partir des $\alpha$ et $\beta$ que l'on a gardé, on peut utiliser ces valeurs pour déquantizer et repasser en précision FP16.
Et c'est tout, la procédure est assez simple et permet au modèle d'être représenté avec uniquement des -1 et des 1.
Les auteurs du papier ont remarqué que, en utilisant cette technique, on obtient des bons résultats sur des modèles assez profonds (plus de 30B) mais les résultats sont assez moyens pour des modèles plus petits.
BitNet 1.58 : On a besoin du zéro !¶
La méthode BitNet1.58 a été introduite pour améliorer le modèle précédent notamment pour le cas des modèles plus petits.
Dans cette méthode, les auteurs proposent d'ajouter la valeur 0 en plus de -1 et 1. Cela ne parait pas être un gros changement mais cette méthode permet d'améliorer grandement le modèle BitNet original.
Note : Le modèle est surnommé 1.58 bits car $log_2(3)=1.58$ donc théoriquement, une représentation de 3 valeurs utilise 1.58 bits.
Mais alors pourquoi 0 est si utile ?
En fait, il faut simplement revenir aux bases et regarder la multiplication matricielle.
Une multiplication matricielle peut être décomposée en deux opérations : la multiplication des poids deux par deux et la somme de l'ensemble des ces poids.
Avec -1 et 1, lors de la somme, on pouvait décider uniquement d'ajouter la valeur ou de la soustraire. Avec l'ajout du 0, on peut maintenant ignorer la valeur :
- 1 : Je veux ajouter cette valeur
- 0 : Je veux ignorer cette valeur
- -1 : Je veux soustraire cette valeur
De cette manière, on peut filtrer efficacement les valeurs ce qui permet une bien meilleure représentation.
Pour réaliser le quantization en 1.58b, on utilise la quantization absmean qui est une variante de absmax. Au lieu de se baser sur le maximum, on se base sur la moyenne en valeur absolue $\alpha$ et on arrondit ensuite les valeurs à -1, 0 ou 1 :
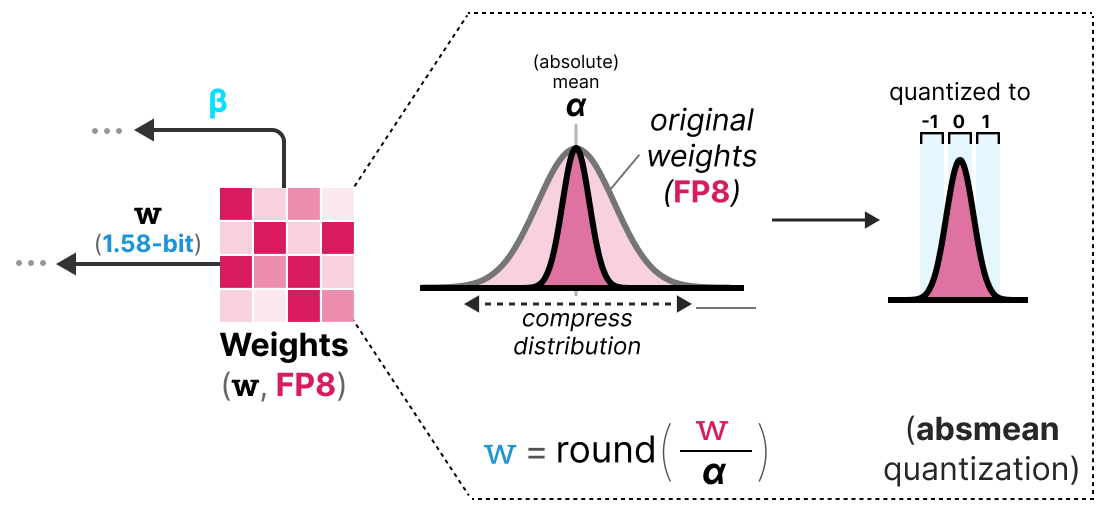
Et voilà, c'est simplement ces deux techniques (representation ternaire et absmean quantization) qui permettent d'améliorer drastiquement la méthode BitNet classique et de proposer des modèles extrémement quantizés et encore performants.
Fine-Tuning des modèle de langages¶
Lorsque nous avons calculé la VRAM nécessaire pour un modèle, on a regardé uniquement pour l'inférence. Si l'on souhaite entraîner le modèle, la VRAM nécessaire est beaucoup plus importante et va dépendre de l'optimizer que l'on utilise (voir cours sur les optimizers). On peut alors imaginer que les LLMs ont besoin d'une quantité énorme de mémoire pour être entraîné ou fine-tune.
Pour réduire cette nécessité en mémoire, des méthodes de parameter efficient fine-tuning(PEFT) ont été proposées et permettent de ne réentrainer qu'une partie du modèle. En plus de permettre de fine-tuner les modèles, cela a également pour effet d'éviter le catastrophic forgetting car on entraîne uniquement une petite partie des paramètres totaux du modèle.
Il existe de nombreuses méthodes pour le PEFT : LoRA, Adapter, Prefix Tuning, Prompt Tuning, QLoRA etc ...
L'idée avec les méthodes type Adapter, LoRA et QLora est d'ajouter une couche entraînable permettant d'adapter la valeur des poids (sans avoir besoin de ré-entraîner les couches de base du modèle).
LoRA¶
La méthode LoRA (low-rank adaptation of large language models) est une technique de fine-tuning permettant d'adapter un LLM à une tâche ou un domaine spécifique. Cette méthode introduit des matrices entraînables de décomposition en rang à chaque couche du transformer ce qui réduit les paramètres entraînables du modèle car les couches de bases sont frozen. La méthode peut potentiellement diminuer le nombre de paramètres entraînables d'un facteur 10 000 tout en réduisant la VRAM nécessaire pour l'entraînement d'un facteur allant jusqu'à 3. Les performances des modèles fine-tune avec cette méthode sont équivalent ou mieux que les modèles fine-tune de manière classique sur de nombreuses tâches.
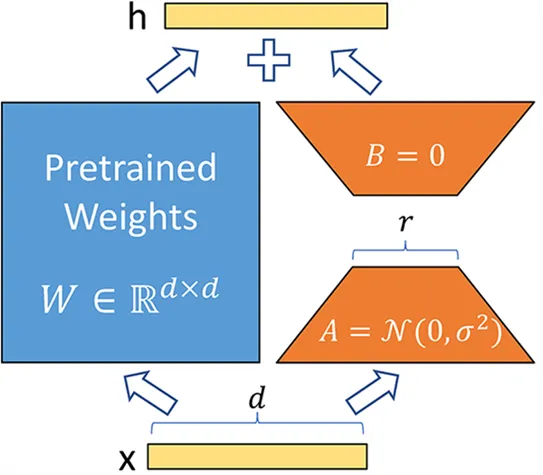
Au lieu de modifier la matrice $W$ d'une couche, la méthode LoRA ajoute deux nouvelles matrices $A$ et $B$ dont le produit representent les modifications à apporter à la matrice $W$.
$Y=W+AB$
Si $W$ est de taille $m \times n$ alors $A$ est de taille $m \times r$ et $B$ de taille $r \times n$ où $r$ est le rang qui est bien plus petit que $m$ ou $n$ (ce qui explique la diminution du nombre de paramètres). Pendant l'entraînement, seulement $A$ et $B$ sont modifié ce qui permet au modèle d'apprendre la tâche spécifique.
QLoRA¶
QLoRA est une version améliorée de LoRA qui permet d'ajouter la quantization 4-bit pour les paramètres du modèle pré-entrainé. Comme nous l'avons vu précédemment, la quantization permet de réduire drastiquement la mémoire nécessaire pour faire tourner le modèle. En combinant LoRA et la quantization, on peut maintenant imaginer faire entraîner un LLM sur un simple GPU grand public ce qui paraissait impossible il y encore quelques années.
Note : QLoRA quantize les poids en Normal Float 4 (NF4) qui est une méthode de quantization spécifique aux modèles de deep learning. Pour en savoir plus, vous pouvez consulter cette vidéo au temps indiqué. Le NF4 est conçu spécifiquement pour représenter des distributions gaussiennes (et les réseaux de neurones sont supposés avoir des poids suivants une distribution gaussienne).