Fine Tuning LLM¶
Dans ce cours, nous allons présenter en détail l'article BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding que nous avons déjà mentionné dans le cours 7 sur les transformers.
La plupart des LLM (GPT, BERT etc ...) sont pré-entrainé sur une tâche de prédiction du prochain mot ou prédiction de mots masqués et sont ensuite finetune sur des tâches plus spécifiques. Les LLM sans fine-tuning ne sont en général pas très utiles.
Note : Lorsque l'on finetune un LLM, on va réentrainer tous les paramètres du modèle. Lorsque l'on finetune des modèles de vision comme des CNN, il est courant de ne ré-entraîner qu'une partie des couches (uniquement la dernière parfois).
BERT : différences avec GPT¶
Dans le cours sur les transformers, nous avons longuement introduit GPT et nous l'avons implementé. La particularité de GPT est qu'il est unidirectionnel, c'est à dire que pour prédire le token de droite, on n'utilise que les tokens de gauche. Cependant, ce type de génération n'est pas opimale pour de nombreuses tâches. Bien souvent, on a besoin du contexte de toute la phrase pour notre tâche.
BERT propose une alternative à cela en utilisant un transformer bidirectionnel c'est à dire que l'on utilise le contexte de droit et de gauche pour notre prédiction.
Ce transformer a une architecture permettant d'être finetune sur deux types de tâches :
- sentence-level prediction : On veut prédire la classe de la phrase (par exemple dans le cas d'analyse de sentiment)
- token-level prediction : On veut prédire la classe de chaque token (named entity recognition par exemple)
Contrairement à GPT, l'architecture de BERT est basé sur le block encoder du transformer et pas le block decoder (voir cours 7 pour rappel).
Tokens et embeddings¶
Tout d'abord, il faut savoir que le token [CLS] est rajouté à chaque séquence d'entrée. Nous verrons son utilisation plus tard dans la partie sur le finetuning du modèle.
De plus, lors de son pre-entrainement, BERT prend en entrée 2 phrases que l'on va séparer par un [SEP] token. En plus de la séparation, on ajoute également un segment embedding à chaque token embedding qui indique l'indice de la phrase de provenance (1 ou 2). Bien sur, comme pour GPT, on utilise un position embedding que l'on ajoute également à chaque token embedding.
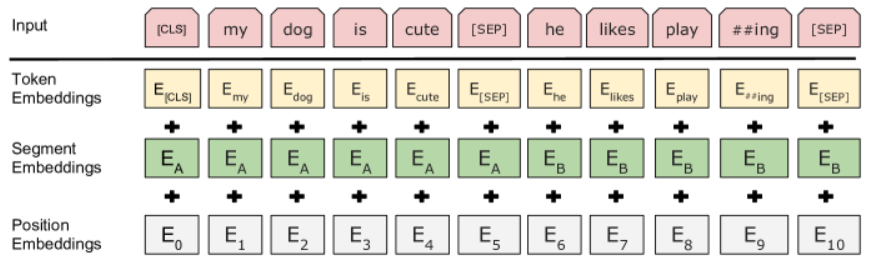
Note : L'utilisation de phrase n'est pas à comprendre dans le sens linguistique du terme mais plutôt comme une séquence de tokens qui se suivent.
Comment pré-entraîner BERT ?¶
Tâche 1 : Prédiction des mots masqués¶
Pour GPT, nous avions vu que pour entraîner le modèle, il suffisait de masquer le futur (le token à prédire et les tokens à droite) pour entraîner le modèle. Comme BERT est bidirectionnel, on ne peut pas utiliser cette méthode.
A la place, les auteurs proposent de masquer une partie des tokens (15% en pratique) de manière aléatoire et d'entraîner le modèle à prédire ces mots.
BERT est alors appelé un Masked Language Model (MLM). L'idée va être de remplacer ces tokens par des tokens [MSK].
Lors du fine-tuning, il n'y aura aucun [MSK] token donc pour compenser ce problème, les auteurs proposent de ne pas convertir l'intégralité des 15% de tokens en [MSK] tokens mais plutôt de faire de la manière suivante :
Sur les 15% de tokens choisis :
- 80% sont convertis en [MSK] tokens
- 10% sont convertis en un autre token random
- 10% restent identiques
Cette technique va permettre un fine-tuning beaucoup plus efficace.
Note : Attention à la confusion avec le terme masked. Le Masked Language Model (MLM) n'utilise pas de couche masked self-attention alors que GPT (qui n'est pas un MLM) en utilise.
Note 2 : Un parallèle très intéressant est fait entre BERT et un denoising autoencoder. En effet, quand on y refléchit, l'idée de BERT est de corrompre le texte d'entrée en masquant certains tokens et de prédire le texte réel. Pour le denoising autoencoder, on va corrompre l'image en rajoutant du bruit et prédire l'image réelle. L'idée est vraiment similaire mais en pratique, il y a quand même une différence : les denoising autoencoders vont reconstruire l'image entière alors que BERT va se contenter de prédire les tokens manquants sans toucher aux autres tokens de l'input.
Tâche 2 : Prédiction de la prochaine phrase¶
De nombreuses tâches de NLP se basent sur des relations entre 2 phrases. Ce type de relation n'est pas directement capturé par le language modeling et il est donc intéressant d'ajouter un objectif spécifique pour la compréhension de ces relations.
Pour cela, BERT ajouter une prédiction binaire de next sentence prediction. On a une phrase A et une phrase B, séparées par un [SEP] token, 50% du temps les phrases A et B vont être des phrases qui se suivent dans le texte original et 50% du temps ça ne sera pas le cas. BERT va alors devoir prédire si ces phrases se suivent.
Ce simple ajout d'objectif d'entraînement est très bénéfique si l'on souhaite finetune BERT sur des tâches de réponses aux questions par exemple.
Données utilisées pour l'entraînement¶
L'article indique égalements les données utilisées pour l'entraînement. Avoir cette information est de plus en plus rare de nos jours. BERT a été entraîné sur ces deux datasets :
- BooksCorpus (800 millions de mots) : Un dataset qui contient environ 7000 livres.
- English Wikipedia (2500 millions de mots) : Un dataset qui contient les textes issus de la version anglaise de wikipedia (juste le texte et pas les listes etc ...).
Comment finetune BERT ?¶
Le finetuning de BERT est assez direct. On va simplement utiliser les inputs et outputs de la tâche que l'on souhaite faire et ré-entraîner l'ensemble des paramètres du modèle.
On a deux grandes familles de tâches :
- sentence-level prediction : Pour ces tâches, on va utiliser le [CLS] token pour extraire la classification de la phrase. L'utilisation du [CLS] token permet de faire fonctionner le modèle peu importe la taille de phrase d'entrée (dans la limite du contexte bien sûr) et de ne pas avoir un biais en fonction du choix du tokens. Sans le [CLS] token, on serait obligé d'utiliser une des ces 2 méthodes : connecter l'ensemble des embeddings de sortie à une couche fully connected pour obtenir la prédiction (mais cela ne fonctionnera pas pour une taille de séquence arbitraire) ou prédire à partir de l'embedding d'un token de la phrase choisi au hasard (mais cela pourrait biaiser le résultat en fonction du token que l'on selectionne).
- token-level prediction : Pour cette tâche, on va simplement prédire une classe pour tous les embeddings de tokens que nous avons car on souhaite un label par token.
Note : Finetune BERT ou un autre LLM est beaucoup moins couteux que de pré-entrainé le modèle. Une fois que l'on a un modèle pré-entrainé, on peut le réutiliser sur un grand nombre de tâches à moindre coût.