Introduction NLP¶
NLP, Qu'est ce que c'est ?¶
Le NLP ou natural language processing (traitement du langage naturel) est un problème important dans le domaine du machine learning. Ce domaine regroupe plusieurs tâches liées au texte comme la traduction, la compréhension de texte, les questions/réponses et bien d'autres.
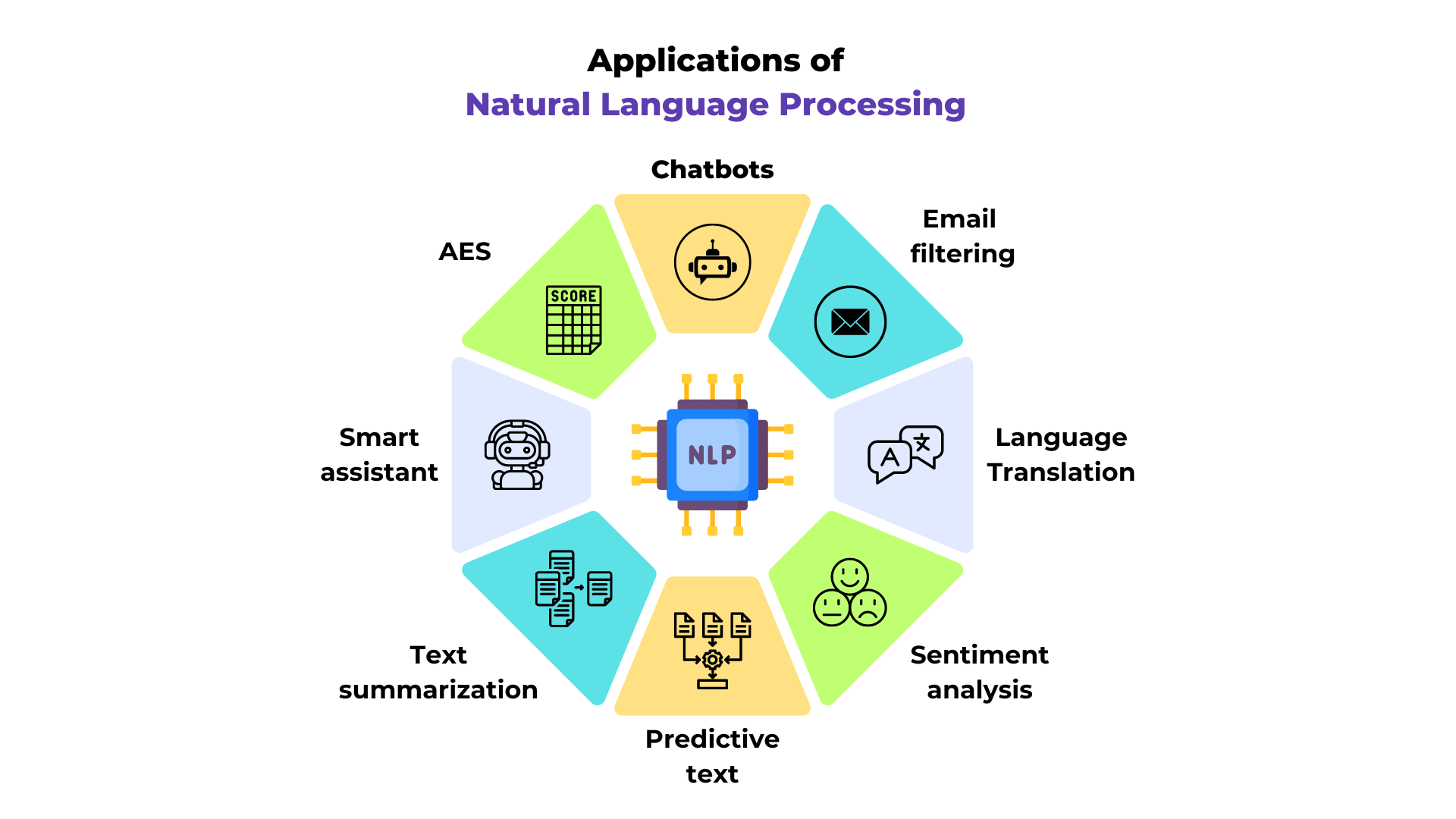
Figure extraite du blogpost.
C'est une tâche un peu à part dans le domaine du deep learning car il s'agit de traiter des données discrètes qui se lisent en général de gauche à droite.
Qu'est ce que ce cours aborde ?¶
Ce cours va aborder principalement l'aspect "prédiction du prochain token" en prenant l'exemple de la prédiction du prochain caractère dans un premier temps pour plus de simplicité.
Ce problème est le fondement des modèles de langages (type GPT, Llama, gemini etc ...).
L'idée est de prédire le mot qui va suivre en fonction des mots précédents (avec plus ou moins de contexte en fonction de la méthode et de la puissance du modèle).
Le contexte est défini par le nombre de token (ou mots) qui vont être utilisés pour prédire le prochain mot.
Un token, qu'est ce que c'est ? : Un token correspond à un élément d'entrée du modèle, il peut s'agir d'un caractère, d'un groupe de caractères ou d'un mot qui est converti en vecteur avant d'être donné en entrée au modèle.
Inspiration pour le cours¶
Ce cours s'inspire fortement de la série de vidéos de Andrej Karpathy (lien du repository github) et en particulier des cours "building makemore". Ce cours va consister à apporter une version écrite et en français des enseignements de cette série de vidéos. Je vous invite à regarder cette série de vidéos en plus, il s'agit d'un des meilleurs cours sur les modèles de langages à ce jour (et c'est gratuit).
Nous subdiviserons ce cours en plusieurs notebooks avec des modèles de difficulté croissante. L'intêret est de voir les limitations de chaque modèle avant de passer à un modèle plus complexe.
Voici un plan du cours :
- Cours 1 : Bigramme : Méthode classique et réseau de neurones
- Cours 2 : Prédiction du prochain mot avec Réseau Fully Connected
- Cours 3 : WaveNet : architecture hierarchique
- Cours 4 : RNN : réseau de neurones récurrents avec architecture séquentielle
- Cours 5 : LSTM : réseau récurrent "amélioré"
Notes : Le cours 7 sur les transformers s'attaque au même problème de génération du prochain caractère mais avec une architecture transformer et sur un dataset plus complexe.
Récuperation du dataset prenom.txt¶
Dans ce cours, nous travaillons sur un dataset de prénoms qui contient environ 30 000 prénoms les plus courant en France depuis 1900 (données de l'INSEE). Le fichier prenoms.txt existe déjà dans le dossier, il n'est pas donc pas nécessaire d'executer le code ci-dessous. Si vous souhaitez le faire il faut d'abord télécharger le fichier 'nat2022.csv' sur le site de l'INSEE.
import pandas as pd
# Chargement du fichier CSV
df = pd.read_csv('nat2022.csv', sep=';')
# On enlève la catégorie '_PRENOMS_RARES' qui regroupe les prénoms peu fréquents
df_filtered = df[df['preusuel'] != '_PRENOMS_RARES']
# Pour compter, on fait la somme des nombres de naissances pour chaque prénom
df_grouped = df_filtered.groupby('preusuel', as_index=False)['nombre'].sum()
# On va trier les prénoms par popularité
df_sorted = df_grouped.sort_values(by='nombre', ascending=False)
# On extrait les 30 000 prénoms les plus populaires
top_prenoms = df_sorted['preusuel'].head(30000).values
with open('prenoms.txt', 'w', encoding='utf-8') as file:
for prenom in top_prenoms:
file.write(f"{prenom}\n")
Dans le notebook suivant, nous commencerons par analyser le dataset (caractères distincts etc ...).