Réseau convolutif¶
Intuition¶
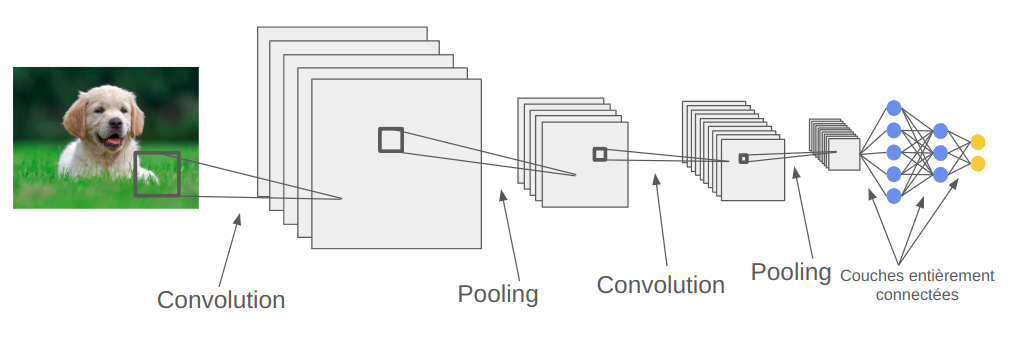
A l'image des réseaux fully connected, les réseaux convolutifs sont également constitués d'une succession de couches. L'idée principale est d'augmenter les filtres (canaux) avec la profondeur tout en réduisant la résolution spatiale des FeatureMap. En faisant cela, on augmente l'abstraction au fur et à mesure du réseau avec les premières couches qui détecteront plus des informations de contours alors que les couches profondes contiendront des informations plus contextuelles.
Pour un problème de classification (MNIST par exemple), les dernières couches du réseau seront souvent des couches entièrement connectées pour adapter la dimension de sortie des couches de convolutions avec le nombre de classes.
De manière générale, un réseau convolutif est constitué d'une succession de couches de convolution, de couche d'activation (ReLU, sigmoid, tanH etc ) et de couche de pooling. La couche de convolution va permettre de changer le nombre de filtres et d'ajouter des paramètres entraînables, la couche d'activation permet de rendre le réseau non linéaire et la couche de pooling permet de diminuer la résolution spatiale de l'image.
L'architecture classique d'un réseau de neurones convolutif est la suivante :
Champ réceptif¶
Comme indiqué dans le notebook précédent, une unique couche de convolution permet uniquement une interaction locale entre les pixels (pour un filtre de taille $3 \times 3$, chaque pixel n'est influencé que par ses pixels adjacents). Cela est très problématique lorsqu'il faut détecter un élément qui occupe l'integralité de l'image.
Cependant, on peut comprendre assez facilement qu'un empilement de couches de convolutions peut conduire à une augmentation de la zone d'influence d'un pixel.
L'image suivante illustre le principe :
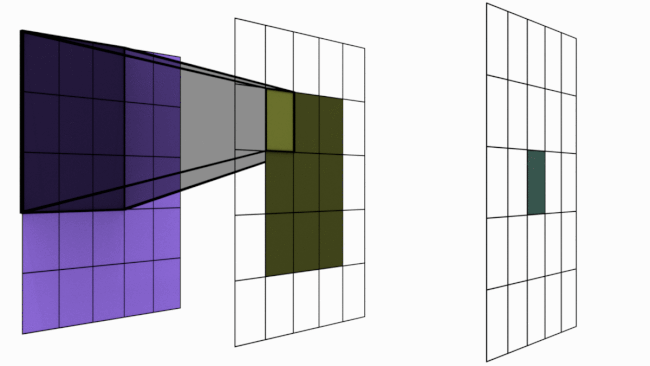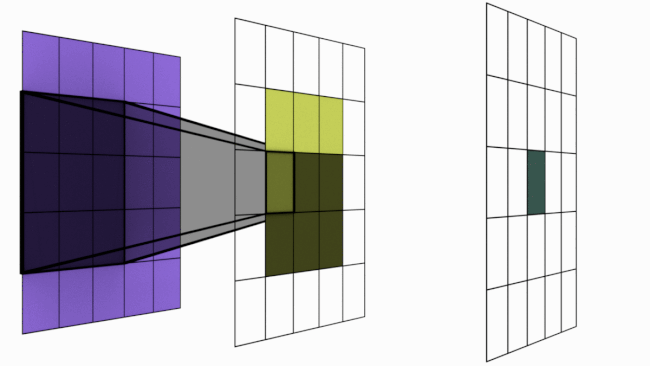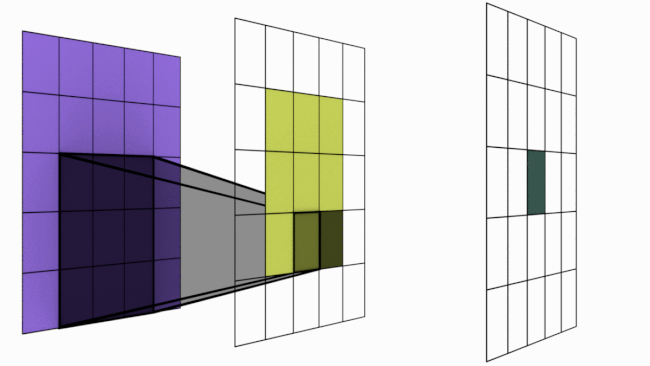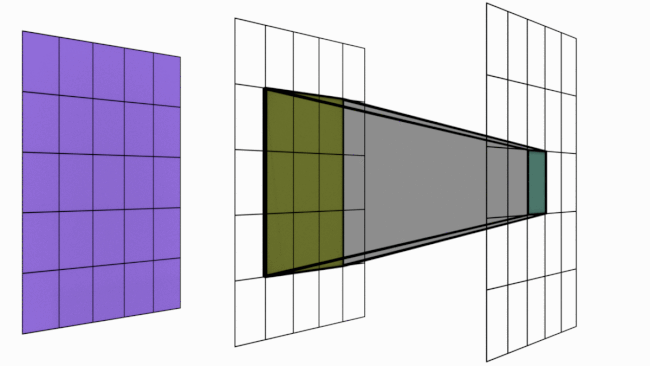
Figure extraire de blogpost.
Plus formellement, on définit le champ réceptif d'un pixel par la formule suivante :
$R_{Eff}=R_{Init} + (k-1)*S$
Avec $R_{Eff}$ le champ réceptif de la couche de sortie, $R_{Init}$ le champ réceptif initial, $k$ la taille du noyau de convolution et $S$ le stride.
Lorsqu'on implémente des réseaux convolutifs, il faut donc faire attention à ce paramètre pour être sûr que notre réseau étudie bien l'interaction de l'ensemble des pixels les uns avec les autres. Plus l'image d'entrée est grande, plus il faut un champ réceptif important.
Précision : Les outils vu dans les cours précédents permettant d'améliorer le modèle sont utilisables également avec les réseaux convolutifs (BatchNorm, Dropout, etc ...)
Visualisation de ce que le réseau apprend¶
Pour appréhender le fonctionnement d'un réseau de neurones convolutifs et le rôle de chaque couche, on peut visualiser les activations des FeatureMaps en fonction de la profondeur.
Voici une visualisation en fonction de la profondeur du réseau :
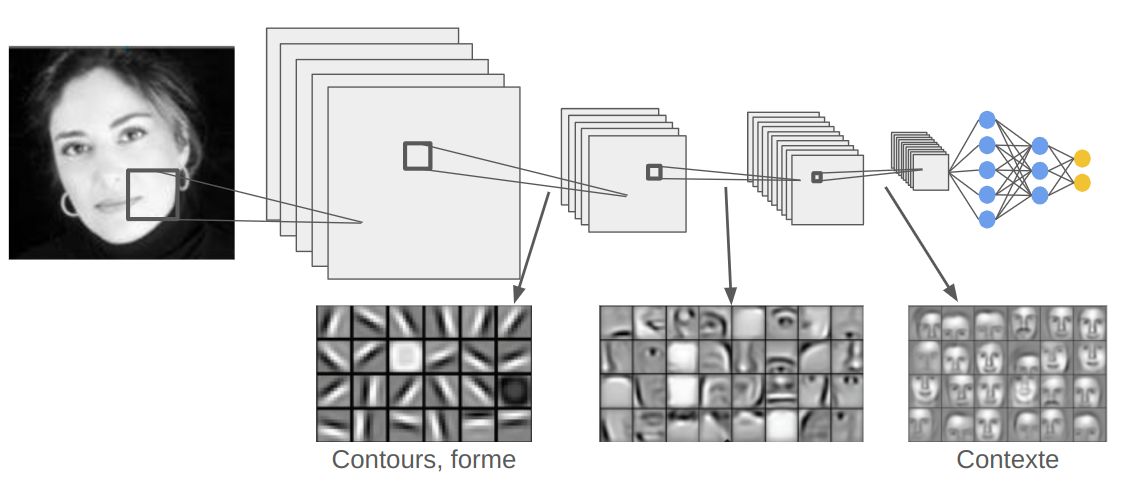
Comment on peut le voir, les couches peu profondes vont plus regarder les informations locales comme les contours et les formes basiques tandis que les couches profondes contiendront plutôt des informations de contexte. Bien sûr, il s'agit d'un continuum et les couches intermédiaires contiendront des informations d'une partie importante de l'image.