Introduction aux transformers¶
Dans le chapitre précédent, nous avons vu de nombreuses applications de la library transformers de Hugging Face. Comme son nom l'indique, cette library gère des modèles transformers. Mais alors, qu'est ce qu'un modèle transformer ?
Le transformer, d'où ça vient ?¶
Jusqu'à 2017, la plupart des réseaux de neurones pour les tâches de NLP utilisaient des réseaux récurrents (RNN). En 2017, des chercheurs de google ont publié un papier qui a changé le domaine du NLP puis plus tard les autres domaines du deep learning (vision, audio etc...) en introduisant l'architecture transformer.
Ce papier est "Attention Is All You Need" et l'architecture du transformer ressemble à cela :
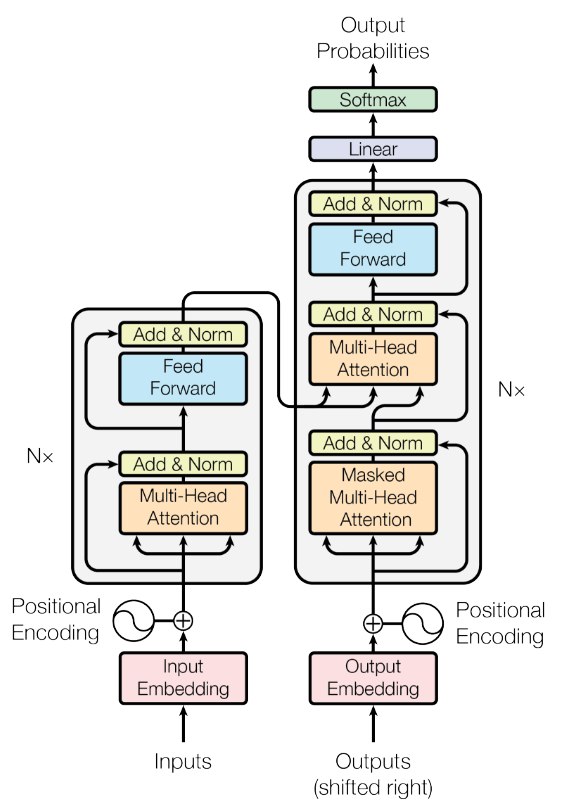
A première vue, ça semble bien compliqué. La partie de gauche s'appelle l'encodeur et la partie de droite le décodeur.
Contenu du cours¶
Première partie : construisons GPT from scratch¶
La première partie de ce cours s'inspire grandement de la vidéo "Let's build GPT: from scratch, in code, spelled out." de Andrej Karpathy et consiste à implémenter un modèle de prédiction du prochain caractère en se basant sur les caractères précédents (c'est un peu la continuité du cours 5 sur les NLP). Cette partie va servir à appréhender l'intêret de l'architecture transformer et en particulier du décodeur.
Dans cette partie, nous entrainerons un modèle à écrire du "Molière" automatiquement.
Deuxième partie : Théorie et encodeur¶
La deuxième partie présente des concepts un peu plus mathématiques et présente également le décodeur de l'architecture transformer.
Troisième partie : ViT, BERT et autres architectures marquantes¶
Cette troisième partie présente rapidement des adaptations de l'architecture transformer pour des tâches différente de GPT.
Quatrième partie : Implémentation du Vision Transformer¶
Dans la quatrième partie, nous implémentons le vision transformer à partir du papier An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale et nous l'entraînons sur le dataset CIFAR-10.
Cinquième partie : Implémentation du Swin Transformer¶
Cette cinquième et dernière partie propose une explication du papier Swin Transformer: Hierarchical Vision Transformer using Shifted Windows ainsi qu'une implémentation simplifiée.