Métriques d'évaluation de modèles¶
Une partie essentielle de l'entraînement d'un modèle est son évaluation. Jusqu'à présent, nous avons uniquement utilisé le loss de test ou des métriques simples comme la précision pour évaluer notre modèle.
En fonction du problème à résoudre, il existe différents types de métriques permettant d'évaluer différents aspects de notre modèle. Ce cours présente plusieurs métriques que l'on peut choisir ou non d'utiliser pour évaluer notre modèle.
Métriques de classification¶
Matrice de confusion¶
Dans un cadre de classification binaire, on peut se representer les prédictions du modèle de la manière suivante :
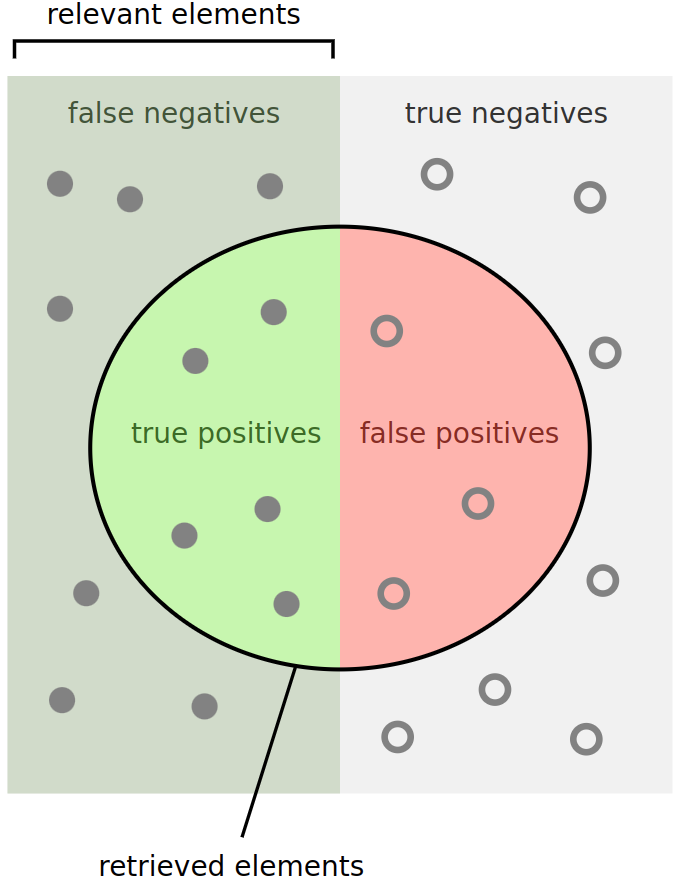
Figure extraite de wikipedia
Définissons d'abord les termes de base :
- Faux positif (fp) : L'élément a été classé comme positif alors qu'il est négatif.
- Vrai positif (vp) : L'élément a été classé comme positif et il est réellement positif.
- Faux négatif (fn) : L'élément a été classé comme négatif alors qu'il est positif.
- Vrai négatif (vn) : L'élément a été classé comme négatif et il est réellement négatif.
Pour se representer la figure plus haut, on peut créer une matrice de confusion :
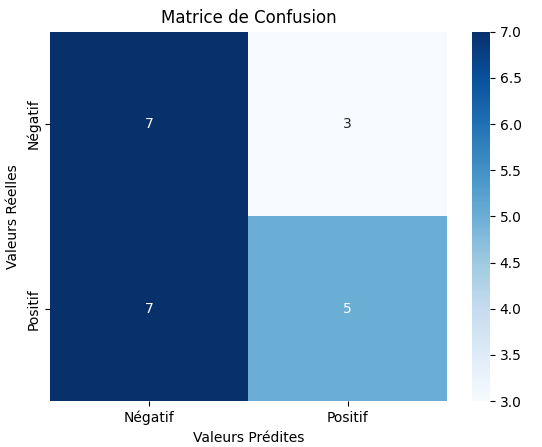
Note : Pour une classification avec plus de deux classes, on peut aussi construire une matrice de confusion. Cela nous donnera des informations sur les classes que le modèle confond.
Précision, rappel et spécificité¶
A partir de la matrice de confusion et des termes de base (fn,vp etc ...), on peut calculer plusieurs métriques intéressants :
- Précision : La précision est définie par l'équation suivante : $Précision=\frac{vp}{vp+fp}$. C'est la mesure qui indique combien d'éléments positifs ont été correctement classifiés sur l'ensemble des éléments classifiés positifs par le modèle.
- Rappel ou sensitivité : Le rappel est défini par l'équation suivante : $Rappel=\frac{vp}{vp+fn}$. C'est la mesure qui indique combien d'éléments positifs ont été correctement classifiés sur l'ensemble des éléments positifs.
- Spécificité ou sélectivité : La spécificité est définie par l'équation suivante : $Spécificité=\frac{vn}{vn+fp}$. C'est le nombre d'éléments négatifs correctement classifiées sur l'ensemble des éléments négatifs.
Accuracy¶
La métrique accuracy (nom un peu trompeur car la traduction de accuracy en français c'est précision mais que ce ne sont pas les mêmes métriques) est définie comme le nombre de prédictions correctes sur le nombre total de prédictions.
Son équation est la suivante :
$Accuracy=\frac{vp+vn}{vp+vn+fp+fn}$
Note : Il faut faire attention avec cette métrique en cas de class imbalance car celui ci peut être trompeur.
F1-score¶
Le F1-score est une mesure très souvent utilisée pour évaluer la performance du modèle : il s'agit en fait de la moyenne harmonique de la précision et du rappel.
Son équation est la suivante :
$F1=2 \times \frac{précision \times rappel}{précision + rappel}$
Si les valeurs de précision et de rappel sont proches, le F1-score correpond à peu près à la moyenne.
Courbe ROC¶
La courbe ROC (Receiver Operating Characteristic) est un graphique qui illustre les performances d'un modèle de classification binaire à différents seuils de décision. La courbe ROC contient les éléments suivants :
- Axe des X est de le taux de faux positifs ($1-spécificité$). C'est le nombre d'éléments négatifs incorrectement classés comme positifs, divisé par le nombre total d'éléments négatifs.
- Axe des Y est le taux de vrais positifs ($rappel$). C'est le nombre d'éléments positifs correctement classés comme positifs, divisé par le nombre total d'éléments positifs.
Chaque point de la courbe va représenter un seuil de décision différent pour la classification des éléments.
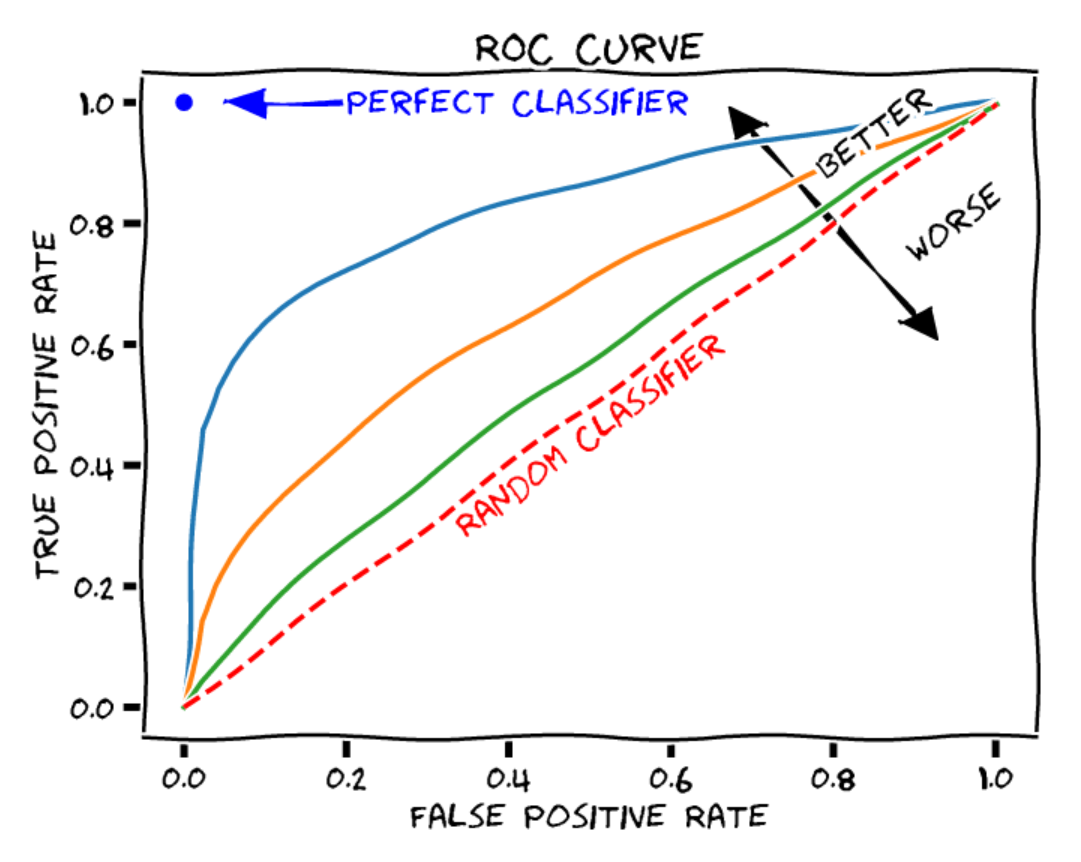
Figure extraite de blogpost.
Pour juger la qualité d'un modèle, on peut calculer l'aire sous la courbe ROC (AUROC). Dans le cas du random classifier on aura un AUROC de 0.5 alors que si il s'agit du classifieur parfait, l'AUROC sera de 1.
Log loss¶
Comme métrique, on peut simplement regarder la valeur du loss sur les données de test. Comme le loss est censé représenter notre objectif, regarder uniquement le loss peut être suffisant dans de nombreux cas.
Métriques de regression/autoencoder¶
Mean Absolute Error (MAE)¶
Pour les modèles de régression ou les autoencodeurs, on a plutôt comparer les valeurs prédites par rapport aux valeurs réelles en calculant une distance.
On peut le faire avec la MAE qui est la moyenne des valeurs absolues des erreurs entre les prédictions et les valeurs réelles.
La formule est la suivante :
$\text{MAE} = \frac{1}{n} \sum_{i=1}^{n} \left| y_i - \hat{y}_i \right|$
Mean Squared Error (MSE)¶
Souvent, on préfere utiliser MSE qui est la moyenne des carrés des erreurs entre les prédictions et les valeurs réelles.
La formule est la suivante :
$\text{MSE} = \frac{1}{n} \sum_{i=1}^{n} \left( y_i - \hat{y}_i \right)^2$
Métriques pour la détection et la segmentation¶
AP et mAP¶
Dans un problème de détection, on ne peut pas simplement évaluer la précision et il faut tenir compte des différents seuils de rappels pour avoir une évaluation sensée.
On la définit average precision (AP) de la manière suivante :
$\text{AP} = \int_{0}^{1} \text{Precision}(r) \, \text{d}r$
ou de manière discrète :
$\text{AP} = \sum_{k=1}^{K} \text{Precision}(r_k) \cdot (r_k - r_{k-1})$
où :
- $\text{Precision}(r)$ est la précision au rappel $r$.
- $K$ est le nombre de points d'évaluation du rappel.
- $r_k $ et $r_{k-1}$ sont les rappels aux points $k$ et $k-1$, respectivement.
La mean average precision (mAP) est la moyenne des AP pour toutes les classes dans un problème de détection multi-classes. Elle donne une évaluation globale de la performance du modèle en prenant en compte toutes les classes.
$\text{mAP} = \frac{1}{C} \sum_{c=1}^{C} \text{AP}_c$
Intersection Over Union (IoU)¶
Dans la cadre de la détection et de la segmentation, la mesure d'IoU est très importante. Pour la détection, on va définir un seuil d'IoU en dessous duquel la détection sera considérée comme invalide (donc ne sera pas prise en compte pour le calcul du mAP). Pour la segmentation, l'IoU est une métrique à part entière et permet de juger de la qualité de la segmentation.
La formule est la suivante :
$\text{IoU} = \frac{|\text{Intersection}|}{|\text{Union}|} = \frac{|\text{Prédiction} \cap \text{Vérité terrain}|}{|\text{Prédiction} \cup \text{Vérité terrain}|}$
Note : Un défaut de l'IoU pour évaluer la segmentation est que cette mesure va pénaliser les petits objets et les classes rares. Pour réduire ce biais, on peut utiliser le dice coefficient.
Dice Coefficient¶
Pour une tâche de segmentation, on va plus souvent utilisé le dice coefficient plutôt que l'IoU.
Sa formule est la suivante :
$\text{Dice} = \frac{2 \times |\text{Prédiction} \cap \text{Vérité terrain}|}{|\text{Prédiction}| + |\text{Vérité terrain}|}$
Le dice coefficient met l'accent sur l'importance de l'intersection entre la prédiction et la vérité terrain, en donnant plus de poids à la présence d'éléments communs.
Evaluation des modèle de langages¶
L'évaluation des modèles de langages est une tâche très compliquée. De manière évidente, on peut se baser sur le loss de test pour avoir une idée des performances du modèle mais cela ne nous donne pas une réelle information sur les capacités du modèle en pratique.
De nombreuses méthodes et benchmarks ont été proposés pour essayer d'évaluer les modèles de langages selon différents critères.
Ce blogpost présente les différentes méthodes d'évaluation des LLMs.
Sur hugging face, un leaderboard des LLMs est aussi disponible où chaque modèle open-source est évalué selon différents benchmarks.
Evaluation des modèle de génération d'images¶
Pour les modèles de génération d'images, c'est aussi assez compliqué d'évaluer les modèles en se basant sur de simples calculs. En général, on va avoir besoin d'une évaluation humaine pour juger de la qualité de la génération d'images.
Ce blogpost permet d'avoir une vision d'ensemble de l'évaluation de ce type de modèles.